

Berkeley DB 由浅入深【转自架构师杨建】

for (fail = 0;;) { /* Begin the transaction. */ if ((ret = dbenv-txn_begin(dbenv, NULL, tid, 0)) != 0) { dbenv-err(dbenv, ret, dbenv-txn_begin); exit (1); } /* Store the key. */ switch (ret = dbp-put(dbp, tid, key, data, 0)) { case 0: /* S
for (fail = 0;;) { /* Begin the transaction. */ if ((ret = dbenv->txn_begin(dbenv, NULL, &tid, 0)) != 0) { dbenv->err(dbenv, ret, "dbenv->txn_begin"); exit (1); } <p>/* Store the key. */ switch (ret = dbp->put(dbp, tid, &key, &data, 0)) { case 0: /* Success: commit the change. */ printf("db: %s: key stored.\n", (char *)key.data); if ((ret = tid->commit(tid, 0)) != 0) { dbenv->err(dbenv, ret, "DB_TXN->commit"); exit (1); } return (0); case DB_LOCK_DEADLOCK: default: /* Failure: retry the operation. */ if ((t_ret = tid->abort(tid)) != 0) { dbenv->err(dbenv, t_ret, "DB_TXN->abort"); exit (1); } if (fail++ == MAXIMUM_RETRY) return (ret); continue; } }</p>
<p> <wbr></wbr></p>
<p>
<wbr> <wbr> <wbr> Berkeley DB由五个主要的子系统构成.包括: 存取管理子系统、内存池管理子系统、事务子系统、锁子系统以及日志子系统。其中存取管理子系统作为Berkeley DB数据库进程包内部核心组件,而其他子系统都存在于Berkeley DB数据库进程包的外部。每个子系统支持不同的应用级别。</wbr></wbr></wbr></p>
<p>1.数据存取子系统
<wbr> <wbr>数据存取(Access Methods)子系统为创建和访问数据库文件提供了多种支持。Berkeley DB提供了以下四种文件存储方法:
哈希文件、B树、定长记录(队列)和变长记录(基于记录号的简单存储方式),应用程序可以从中选择最适合的文件组织结构。程序员创建表时可以使用任意一种结构,并且可以在同一个应用程序中对不同存储类型的文件进行混合操作。</wbr></wbr></p>
<p> <wbr> <wbr> <wbr> 在没有事务管理的情况下,该子系统中的模块可单独使用,为应用程序提供快速高效的数据存取服务。
数据存取子系统适用于不需事务只需快速格式文件访问的应用。</wbr></wbr></wbr></p>
<p> <wbr>2.内存池管理子系统
<wbr> <wbr> <wbr> 内存池(Memory pool)子系统对Berkeley DB所使用的共享缓冲区进行有效的管理。它允许同时访问数据库的多个进程或者
进程的多个线程共享一个高速缓存,负责将修改后的页写回文件和为新调入的页分配内存空间。它也可以独立于Berkeley DB系统之外,单独被应用程序使用,为其自己的文件和页分配内存空间。内存池管理子系统适用于需要灵活的、面向页的、缓冲的共享文件访问的应用。</wbr></wbr></wbr></wbr></p>
<p> <wbr>3.事务子系统
<wbr> <wbr>事务(Transaction)子系统为Berkeley DB提供事务管理功能。它允许把一组对数据库的修改看作一个原子单位,这组操作要么全做,要么全不做。在默认的情况下,系统将提供严格的ACID事务属性,但是应用程序可以选择不使用系统所作的隔离保证。该子系统使用两段锁技术和先写日志策略来保证数据库数据的正确性和一致性。它也可以被应用程序单独使用来对其自身的数据更新进行事务保护。事务子系统适用于需要事务保证数据的修改的应用。
<wbr> <wbr> <wbr>
<wbr>4.锁子系统
<wbr> <wbr> <wbr> 锁(Locking)子系统为Berkeley DB提供锁机制,为系统提供多用户读取和单用户修改同一对象的共享控制。
数据存取子系统可利用该子系统获得对页或记录的读写权限;事务子系统利用锁机制来实现多个事务的并发控制。
<wbr> <wbr> <wbr>
<wbr> <wbr> <wbr> 该子系统也可被应用程序单独采用。锁子系统适用于一个灵活的、快速的、可设置的锁管理器。
<wbr> <wbr> <wbr>
5.日志子系统 <wbr> <wbr> <wbr>
<wbr>日志(Logging)子系统采用的是先写日志的策略,用于支持事务子系统进行数据恢复,保证数据一致性。
它不大可能被应用程序单独使用,只能作为事务子系统的调用模块。</wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></p>
<p> <wbr> <wbr> <wbr>以上几部分构成了整个Berkeley DB数据库系统。各部分的关系如下图所示:</wbr></wbr></wbr></p>
<p><img src="/static/imghw/default1.png" data-src="/inc/test.jsp?url=http%3A%2F%2Fleeon.me%2Fupload%2F2010-04%2F20100403150406_56033.jpg&refer=http%3A%2F%2Fblog.csdn.net%2Fduanbeibei%2Farticle%2Fdetails%2F26456603" class="lazy" alt="Berkeley DB 由浅入深【转自架构师杨建】" >
<wbr> <wbr> <wbr>
<wbr> <wbr> <wbr> 在这个模型中,应用程序直接调用的是数据存取子系统和事务管理子系统,这两个系统进而调用更下层的内存管理子系统、
锁子系统和日志子系统。
<wbr> <wbr> <wbr>
<wbr> <wbr> <wbr> 由于几个子系统相对比较独立,所以应用程序在开始的时候可以指定哪些数据管理服务将被使用。可以全部使用,也可以只用其中的一部分。例如,如果一个应用程序需要支持多用户并发操作,但不需要进行事务管理,那它就可以只用锁子系统而不用事务。有些应用程序可能需要快速的、单用户、没有事务管理功能的B树存储结构,那么应用程序可以使锁子系统和事务子系统失效,这样就会减少开销。 <wbr> <wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></p>

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 17 ways to solve the kernel_security_check_failure blue screen
Feb 12, 2024 pm 08:51 PM
17 ways to solve the kernel_security_check_failure blue screen
Feb 12, 2024 pm 08:51 PM
Kernelsecuritycheckfailure (kernel check failure) is a relatively common type of stop code. However, no matter what the reason is, the blue screen error causes many users to be very distressed. Let this site carefully introduce 17 types to users. Solution. 17 solutions to kernel_security_check_failure blue screen Method 1: Remove all external devices When any external device you are using is incompatible with your version of Windows, the Kernelsecuritycheckfailure blue screen error may occur. To do this, you need to unplug all external devices before trying to restart your computer.
 Comparative analysis of deep learning architectures
May 17, 2023 pm 04:34 PM
Comparative analysis of deep learning architectures
May 17, 2023 pm 04:34 PM
The concept of deep learning originates from the research of artificial neural networks. A multi-layer perceptron containing multiple hidden layers is a deep learning structure. Deep learning combines low-level features to form more abstract high-level representations to represent categories or characteristics of data. It is able to discover distributed feature representations of data. Deep learning is a type of machine learning, and machine learning is the only way to achieve artificial intelligence. So, what are the differences between various deep learning system architectures? 1. Fully Connected Network (FCN) A fully connected network (FCN) consists of a series of fully connected layers, with every neuron in each layer connected to every neuron in another layer. Its main advantage is that it is "structure agnostic", i.e. no special assumptions about the input are required. Although this structural agnostic makes the complete
 What is the architecture and working principle of Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
What is the architecture and working principle of Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA is based on the JPA architecture and interacts with the database through mapping, ORM and transaction management. Its repository provides CRUD operations, and derived queries simplify database access. Additionally, it uses lazy loading to only retrieve data when necessary, thus improving performance.
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
 This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Jun 14, 2023 pm 01:43 PM
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Jun 14, 2023 pm 01:43 PM
Some time ago, a tweet pointing out the inconsistency between the Transformer architecture diagram and the code in the Google Brain team's paper "AttentionIsAllYouNeed" triggered a lot of discussion. Some people think that Sebastian's discovery was an unintentional mistake, but it is also surprising. After all, considering the popularity of the Transformer paper, this inconsistency should have been mentioned a thousand times. Sebastian Raschka said in response to netizen comments that the "most original" code was indeed consistent with the architecture diagram, but the code version submitted in 2017 was modified, but the architecture diagram was not updated at the same time. This is also the root cause of "inconsistent" discussions.
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
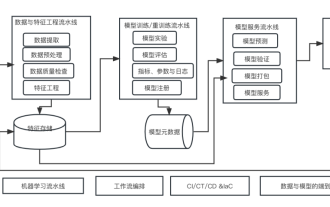 Ten elements of machine learning system architecture
Apr 13, 2023 pm 11:37 PM
Ten elements of machine learning system architecture
Apr 13, 2023 pm 11:37 PM
This is an era of AI empowerment, and machine learning is an important technical means to achieve AI. So, is there a universal machine learning system architecture? Within the cognitive scope of experienced programmers, Anything is nothing, especially for system architecture. However, it is possible to build a scalable and reliable machine learning system architecture if applicable to most machine learning driven systems or use cases. From a machine learning life cycle perspective, this so-called universal architecture covers key machine learning stages, from developing machine learning models, to deploying training systems and service systems to production environments. We can try to describe such a machine learning system architecture from the dimensions of 10 elements. 1.
 AI Infrastructure: The Importance of IT and Data Science Team Collaboration
May 18, 2023 pm 11:08 PM
AI Infrastructure: The Importance of IT and Data Science Team Collaboration
May 18, 2023 pm 11:08 PM
Artificial intelligence (AI) has changed the game in many industries, enabling businesses to improve efficiency, decision-making and customer experience. As AI continues to evolve and become more complex, it is critical that enterprises invest in the right infrastructure to support its development and deployment. A key aspect of this infrastructure is collaboration between IT and data science teams, as both play a critical role in ensuring the success of AI initiatives. The rapid development of artificial intelligence has led to increasing demands for computing power, storage and network capabilities. This demand puts pressure on traditional IT infrastructure, which was not designed to handle the complex and resource-intensive workloads required by AI. As a result, enterprises are now looking to build systems that can support AI workloads.
