

MongoDB:数据模型介绍

在MongoDB的数据有灵活的模式。不像SQL数据库,(SQL数据库)要求你必须在插入数据之前决定和声明一个表的模式,MongoDB的集合不强制文档的结构。这个灵活性有利于文档到实体或对象的映射。每个文档可以匹配所要表示实体的数据字段,即使数据的变化很显著。
在MongoDB的数据有灵活的模式。不像SQL数据库,(SQL数据库)要求你必须在插入数据之前决定和声明一个表的模式,MongoDB的集合不强制文档的结构。这个灵活性有利于文档到实体或对象的映射。每个文档可以匹配所要表示实体的数据字段,即使数据的变化很显著。但在实际操作中,一个集合的文档共享一个相似的结构。
数据模型的关键挑战在于平衡应用的需要,数据库引擎的性能和数据存取模式。当设计数据模型时,要考虑数据在应用里的使用情况(如,查询、更新和处理数据),以及数据本身的内在结构。
文档结构
在为MongoDB应用设计数据模型时的关键是围绕文档的结构和应用时如何表示数据间的联系。有两个工具来允许应用来表示这些关系:引用和嵌入文档( references and embedded documents)。
引用引用通过包括连接或一个文档到另一个文档间的引用存储着数据间的关系。应用能够解析这些引用来访问到相关数据。广义上说,这些都是归一化的数据模型(normalized data models).

上图的数据模型使用引用来联系文档。contract文档和access文档都保护着user文档的引用。
下面介绍归一化数据模型在使用引用的优缺点:
归一化模型使用引用描述文档间的关系。一般地,使用归一化模型的情况有,
当嵌入会导致数据重复且不会提供有效的读性能。表示更复杂的多对多的关系对大型分级数据建模引用比嵌入式文档的灵活性更大。但客户端应用必须处理引用带来的查询问题。总之,归一化数据模型需要更多的往返服务器。
嵌入数据嵌入式文档通过在一个单一文档结构里存储相关数据来捕获数据间的关系。MongoDB的文档使在一个文档里的一个字段或字段数据嵌入一个文档作为子文档具体可能性。这些非规范化数据使得应用可以在一个单一数据库操作力获取和操纵数据。

上图的数据模型就是嵌入式字段保护所有的相关信息。
下面讨论嵌入子文档的数据模型的优缺点:
使用MongoDB,你可以在一个单一结构或文档嵌入相关数据。这个模型是著名的“非规范化”模型,利用了MongoDB丰富文档的优势。
嵌入数据模型允许应用在相同的数据库记录里存储相关片段信息。因此,应用在完成一个常规操作时,只需处理很少的查询或更新。
一般,当下面情形时可使用嵌入数据模型:
实体间有“包含关系”实体间有一对多的关系。在这些关系里,“多“或子文档经常被看做"一"或父文档的上下文里一般来说,嵌入提供了更好的读性能,以及在单一数据库操作里请求和获取相关数据的能力。嵌入数据模型使得在哪一个原子操作里更新相关数据成为可能。
然而,在一个文档的嵌入数据模型可能导致文档创建后的增长。文档的增长会影响写性能并导致数据碎片问题。并且,在MongoDB里的文档大小必须小于最大的BSON文档大小。对大型二进制数据,考虑GridFS。
写操作的原子性
在MongoDB,写操作在文档这一级是原子的,并且没有单一的写操作能原子性的影响多个文档或集合。一个有嵌入数据的非规范化数据模型在一个单一文档里包含了能表示一个实体的相关数据。这有利于写操作的原子性,因为单一的写操作能直接对一个实体插入或更新数据。规范化数据会在多个集合里分散了数据,这会要求多次写操作,因此不是原子性的。
然而,有利于原子性写的模式会限制一个应用使用数据的方法或修改数据的方法。因此需要平衡原子性和平衡性。
文档增长
有的更新,比如向数组添加元素或添加新的字段,会增大文档的大小。如果文档的大小超过了给该文档分配的空间,MongoDB会重新定位这个文档。文档的增长会影响规范化和非规范化数据的选择。
数据使用和性能
当设计一个文档模型,要考虑应用将如何使用你的数据库。比如,如果你的应用仅使用最近插入的数据,考虑使用 Capped Collections.或者,你的应用需要总是读操作,添加索引是常见的提升性能的办法。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1653
1653
 14
1413
52
1306
25
1251
29
1224
24
14
1413
52
1306
25
1251
29
1224
24

 How to configure MongoDB automatic expansion on Debian
Apr 02, 2025 am 07:36 AM
How to configure MongoDB automatic expansion on Debian
Apr 02, 2025 am 07:36 AM
This article introduces how to configure MongoDB on Debian system to achieve automatic expansion. The main steps include setting up the MongoDB replica set and disk space monitoring. 1. MongoDB installation First, make sure that MongoDB is installed on the Debian system. Install using the following command: sudoaptupdatesudoaptinstall-ymongodb-org 2. Configuring MongoDB replica set MongoDB replica set ensures high availability and data redundancy, which is the basis for achieving automatic capacity expansion. Start MongoDB service: sudosystemctlstartmongodsudosys
 Use Composer to solve the dilemma of recommendation systems: andres-montanez/recommendations-bundle
Apr 18, 2025 am 11:48 AM
Use Composer to solve the dilemma of recommendation systems: andres-montanez/recommendations-bundle
Apr 18, 2025 am 11:48 AM
When developing an e-commerce website, I encountered a difficult problem: how to provide users with personalized product recommendations. Initially, I tried some simple recommendation algorithms, but the results were not ideal, and user satisfaction was also affected. In order to improve the accuracy and efficiency of the recommendation system, I decided to adopt a more professional solution. Finally, I installed andres-montanez/recommendations-bundle through Composer, which not only solved my problem, but also greatly improved the performance of the recommendation system. You can learn composer through the following address:
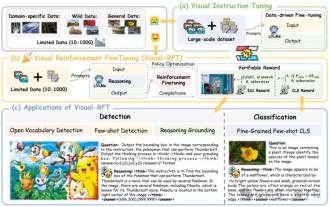 Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Researchers from Shanghai Jiaotong University, Shanghai AILab and the Chinese University of Hong Kong have launched the Visual-RFT (Visual Enhancement Fine Tuning) open source project, which requires only a small amount of data to significantly improve the performance of visual language big model (LVLM). Visual-RFT cleverly combines DeepSeek-R1's rule-based reinforcement learning approach with OpenAI's reinforcement fine-tuning (RFT) paradigm, successfully extending this approach from the text field to the visual field. By designing corresponding rule rewards for tasks such as visual subcategorization and object detection, Visual-RFT overcomes the limitations of the DeepSeek-R1 method being limited to text, mathematical reasoning and other fields, providing a new way for LVLM training. Vis
 How to ensure high availability of MongoDB on Debian
Apr 02, 2025 am 07:21 AM
How to ensure high availability of MongoDB on Debian
Apr 02, 2025 am 07:21 AM
This article describes how to build a highly available MongoDB database on a Debian system. We will explore multiple ways to ensure data security and services continue to operate. Key strategy: ReplicaSet: ReplicaSet: Use replicasets to achieve data redundancy and automatic failover. When a master node fails, the replica set will automatically elect a new master node to ensure the continuous availability of the service. Data backup and recovery: Regularly use the mongodump command to backup the database and formulate effective recovery strategies to deal with the risk of data loss. Monitoring and Alarms: Deploy monitoring tools (such as Prometheus, Grafana) to monitor the running status of MongoDB in real time, and
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
 What is the CentOS MongoDB backup strategy?
Apr 14, 2025 pm 04:51 PM
What is the CentOS MongoDB backup strategy?
Apr 14, 2025 pm 04:51 PM
Detailed explanation of MongoDB efficient backup strategy under CentOS system This article will introduce in detail the various strategies for implementing MongoDB backup on CentOS system to ensure data security and business continuity. We will cover manual backups, timed backups, automated script backups, and backup methods in Docker container environments, and provide best practices for backup file management. Manual backup: Use the mongodump command to perform manual full backup, for example: mongodump-hlocalhost:27017-u username-p password-d database name-o/backup directory This command will export the data and metadata of the specified database to the specified backup directory.
 How to choose a database for GitLab on CentOS
Apr 14, 2025 pm 04:48 PM
How to choose a database for GitLab on CentOS
Apr 14, 2025 pm 04:48 PM
GitLab Database Deployment Guide on CentOS System Selecting the right database is a key step in successfully deploying GitLab. GitLab is compatible with a variety of databases, including MySQL, PostgreSQL, and MongoDB. This article will explain in detail how to select and configure these databases. Database selection recommendation MySQL: a widely used relational database management system (RDBMS), with stable performance and suitable for most GitLab deployment scenarios. PostgreSQL: Powerful open source RDBMS, supports complex queries and advanced features, suitable for handling large data sets. MongoDB: Popular NoSQL database, good at handling sea
 How to encrypt data in Debian MongoDB
Apr 12, 2025 pm 08:03 PM
How to encrypt data in Debian MongoDB
Apr 12, 2025 pm 08:03 PM
Encrypting MongoDB database on a Debian system requires following the following steps: Step 1: Install MongoDB First, make sure your Debian system has MongoDB installed. If not, please refer to the official MongoDB document for installation: https://docs.mongodb.com/manual/tutorial/install-mongodb-on-debian/Step 2: Generate the encryption key file Create a file containing the encryption key and set the correct permissions: ddif=/dev/urandomof=/etc/mongodb-keyfilebs=512
