

Hadoop-Nutch学习整理(持续更新)

Nutch学习整理第一部分 单机尝试1、安装部署Nutch的部署和其他Hadoop生态产品的部署流程基本相:下载软件,上传到服务器,解压文件,修改配置文件。网上有很多类资料,不再赘述。Nutch的配置文件主要有两个: domain-urlfilter.txt 是用来配置所爬取网站的范
Nutch学习整理 第一部分 单机尝试 1、安装部署 Nutch的部署和其他Hadoop生态产品的部署流程基本相似:下载软件,上传到服务器,解压文件,修改配置文件。网上有很多类似资料,不再赘述。 Nutch的配置文件主要有两个:- domain-urlfilter.txt
是用来配置所爬取网站的范围,域名和它的子网页的正则表达式,类似于爬取规则。一般配置为:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
- nutch-site.xml
这类似于对我要爬取的网站进行一下声明,不声明的话,会导致爬取失败。
2、单机主要爬取命令 简单命令格式,不赘述。 bin/nutch crawl[-dir d] [-threads n] [-depth i] [-topN]
3、爬取结果解析 nutch爬取下来的网页信息,保存路径格式如下:
主要爬取信息保存在路径segments下:
喎?http://www.2cto.com/kf/ware/vc/" target="_blank" class="keylink">vcD4KPHVsPgo8bGk+Q3Jhd2xkYsrHy/nT0NDo0qrXpcihtcSzrMGsvdPQxc+iKLTmt8XPwtTYtcRVUkyjrLywz8LU2LXEyNXG2qOs08PAtNKzw+a4/NDCvOyy6cqxvOSjrNK7sOPU2sXAyKHE2sjdveLO9sq9sru74dPDtb2jqTxsaT5MaW5rZGLW0LTmt8W1xMrHy/nT0LOsway907ywxuTDv7j2way907XEwazI67XY1re6zcOqzsSxvqGjPGxpPlNlZ21lbnRztOa3xdelyKG1xNKzw+ajrNPryc/D5sG0vdPJ7rbIIGRlcHRoIM/gudijrGRlcHRoyejOqry41PLU2iBzZWdtZW50c8/Cyfqzyby4uPbS1MqxvOTD/MP7tcTX087EvP680KGjz8LA/b3YzbzKxwogLWRlcHRoPTMKCjxpbWcgc3JjPQ=="http://www.2cto.com/uploadfile/Collfiles/20141127/2014112709151123.jpg" alt="\">
Segments下的文件夹含义:- crawl_generate :names a set of urls to be fetched
- crawl_fetch : contains the status of fetching each url
- crawl_parse : contains the outlink urls, used to update the crawldb
- content : contains the content of each url
- parse_text : contains the parsed text of each url
- parse_data : contains
outlinks and metadata parsed from each url
Segments是每轮抓取的时候根据crawldb生成的。存放的信息包括6种content、crawl_fetch、crawl_generate、crawl_parse、parse_data、parse_text。其中content是抓取下来的网页内容;crawl_generate最初生成(待下载URL集合);crawl_fetch(每个下载URL的状态)、content在抓取时生成;crawl_parse(包含用来更新crawldb的外链)、parse_data、parse_text在解析抓取的数据文件时生成。 在进行爬取结果导出的时候,六个参数(-nocontent -nofetch -noparse -noparsedata -noparsetext -nogenerate)分别对应需要导出的内容。 导出命令例: [root@master local]# bin/nutch readseg -dump data_1125/segments/20141125020224 data_dump -nocontent -nofetch -nogenerate -noparse -noparsedata
- nutch-site.xml
这类似于对我要爬取的网站进行一下声明,不声明的话,会导致爬取失败。






Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 How to fix Blizzard Battle.net update stuck at 45%?
Mar 16, 2024 pm 06:52 PM
How to fix Blizzard Battle.net update stuck at 45%?
Mar 16, 2024 pm 06:52 PM
Blizzard Battle.net update keeps stuck at 45%, how to solve it? Recently, many people have been stuck at the 45% progress bar when updating software. They will still get stuck after restarting multiple times. So how to solve this situation? We can reinstall the client, switch regions, and delete files. To deal with it, this software tutorial will share the operation steps, hoping to help more people. Blizzard Battle.net update keeps stuck at 45%, how to solve it? 1. Client 1. First, you need to confirm that your client is the official version downloaded from the official website. 2. If not, users can enter the Asian server website to download. 3. After entering, click Download in the upper right corner. Note: Be sure not to select Simplified Chinese when installing.
 How to install Angular on Ubuntu 24.04
Mar 23, 2024 pm 12:20 PM
How to install Angular on Ubuntu 24.04
Mar 23, 2024 pm 12:20 PM
Angular.js is a freely accessible JavaScript platform for creating dynamic applications. It allows you to express various aspects of your application quickly and clearly by extending the syntax of HTML as a template language. Angular.js provides a range of tools to help you write, update and test your code. Additionally, it provides many features such as routing and form management. This guide will discuss how to install Angular on Ubuntu24. First, you need to install Node.js. Node.js is a JavaScript running environment based on the ChromeV8 engine that allows you to run JavaScript code on the server side. To be in Ub
 Windows cannot access the specified device, path, or file
Jun 18, 2024 pm 04:49 PM
Windows cannot access the specified device, path, or file
Jun 18, 2024 pm 04:49 PM
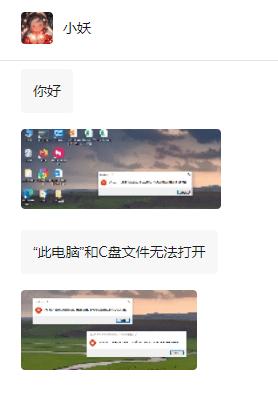
A friend's computer has such a fault. When opening "This PC" and the C drive file, it will prompt "Explorer.EXE Windows cannot access the specified device, path or file. You may not have the appropriate permissions to access the project." Including folders, files, This computer, Recycle Bin, etc., double-clicking will pop up such a window, and right-clicking to open it is normal. This is caused by a system update. If you also encounter this situation, the editor below will teach you how to solve it. 1. Open the registry editor Win+R and enter regedit, or right-click the start menu to run and enter regedit; 2. Locate the registry "Computer\HKEY_CLASSES_ROOT\PackagedCom\ClassInd"
 How to update MSI graphics card driver? MSI graphics card driver download and installation steps
Mar 13, 2024 pm 08:49 PM
How to update MSI graphics card driver? MSI graphics card driver download and installation steps
Mar 13, 2024 pm 08:49 PM
MSI graphics cards are the mainstream graphics card brand on the market. We know that graphics cards need to install drivers to achieve performance and ensure compatibility. So how to update the MSI graphics card driver to the latest version? Generally, MSI graphics card drivers can be downloaded and installed from the official website. Let’s find out more below. Graphics card driver update method: 1. First, we enter the "MSI official website". 2. After entering, click the "Search" button in the upper right corner and enter your graphics card model. 3. Then find the corresponding graphics card and click on the details page. 4. Then enter the "Technical Support" option above. 5.Finally go to “Driver & Download”
 Windows permanently pauses updates, Windows turns off automatic updates
Jun 18, 2024 pm 07:04 PM
Windows permanently pauses updates, Windows turns off automatic updates
Jun 18, 2024 pm 07:04 PM
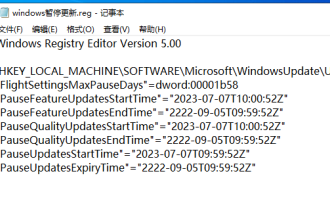
Windows updates may cause some of the following problems: 1. Compatibility issues: Some applications, drivers, or hardware devices may be incompatible with new Windows updates, causing them to not work properly or crash. 2. Performance issues: Sometimes, Windows updates may cause the system to become slower or experience performance degradation. This may be due to new features or improvements requiring more resources to run. 3. System stability issues: Some users reported that after installing Windows updates, the system may experience unexpected crashes or blue screen errors. 4. Data loss: In rare cases, Windows updates may cause data loss or file corruption. This is why before making any important updates, back up your
 Outlook stuck updating inbox;
Mar 25, 2024 am 09:46 AM
Outlook stuck updating inbox;
Mar 25, 2024 am 09:46 AM
When Outlook has problems updating your inbox, it can affect productivity. This article will introduce some simple troubleshooting steps to help you solve the problem and get Outlook back to normal. Why is Outlook always stuck updating the inbox? Outlook may be stuck updating the inbox. Common reasons include network problems, excessive mailbox capacity, and the impact of anti-virus software or firewalls. Corrupted external plug-ins or data files can also cause this to happen. Next, we'll explore these possible causes in detail and provide solutions. Fix Outlook Stuck Updating Inbox If Outlook is unable to update your inbox, please refer to the solutions listed below: Restart Outlook Disabled
 Let's learn how to input the root number in Word together
Mar 19, 2024 pm 08:52 PM
Let's learn how to input the root number in Word together
Mar 19, 2024 pm 08:52 PM
When editing text content in Word, you sometimes need to enter formula symbols. Some guys don’t know how to input the root number in Word, so Xiaomian asked me to share with my friends a tutorial on how to input the root number in Word. Hope it helps my friends. First, open the Word software on your computer, then open the file you want to edit, and move the cursor to the location where you need to insert the root sign, refer to the picture example below. 2. Select [Insert], and then select [Formula] in the symbol. As shown in the red circle in the picture below: 3. Then select [Insert New Formula] below. As shown in the red circle in the picture below: 4. Select [Radical Formula], and then select the appropriate root sign. As shown in the red circle in the picture below:
 How to update TikTok to the latest version
Mar 27, 2024 am 11:06 AM
How to update TikTok to the latest version
Mar 27, 2024 am 11:06 AM
1. Open the Douyin app, click [Me] in the lower right corner, and click the [Three Stripes] icon in the upper right corner. 2. Select [Settings], click to enter the settings interface, find and click [General Settings]. 3. Pull down on the general settings interface, find and click [Check for Updates]. 4. If the version currently used by the user is not the latest version, an update prompt for the new version will appear. Click [Upgrade]. 5. Wait for the installation package to be downloaded. The system will automatically install it. Click [Continue Installation]. 6. If the current version is already the latest version, a prompt of "No update version available" will appear.
