

ApacheHive一点一点进步(1) 简单介绍

Hive是一个 hadoop 的数据仓库,便于对 hadoop 中存储的大数据进行数据汇总,点对点查询,以及分析。 Hive提供了一套管理机制用于管理HDFS中的数据及一套类型于sql的查询语言HiveQL。 同时当HiveQL无法满足逻辑的时候,这种语言支持传统的MR程序,以插件的形
Hive是一个hadoop的数据仓库,便于对hadoop中存储的大数据进行数据汇总,点对点查询,以及分析。
Hive提供了一套管理机制用于管理HDFS中的数据及一套类型于sql的查询语言HiveQL。
同时当HiveQL无法满足逻辑的时候,这种语言支持传统的MR程序,以插件的形式集成到Hive的MR中。
Hive是apache基金会下的一个开源志愿者项目。以前他是一个Hadoop的子项目。但是现在他已经升级为一个顶级项目。
安装
Requirements Java1.6,hadoop0.20.xx选择一个稳定版进行安装 http://hive.apache.org/releases.html解压缩tarball。$ tar -xzvf hive-x.y.z.tar.gz$ cd hive-x.y.z $ export HIVE_HOME={{pwd}}配置 Hive默认的配置是<install-dir>/conf/hive-DEFAULT.xml如果需要变更配置,可以重新配置于 <install-dir>/conf/hive-site.xmlLog4j配置储存于<install-dir>/conf/hive-log4j.propertiesHive的配置是基于对hadoop的一个覆盖,意思是hadoop的配置变量是缺省继承的。Hive变量的配置方法:1.修改hive-site.xml文件2.通过cli客户端使用SET命令进行3.通过授权hive使用如下语法$ bin/hive -hiveconf x1=y1 -hiveconf x2=y2</install-dir></install-dir></install-dir>
运行时配置
Hive的查询是通过MR查询执行的,因此,这样的查询行为都是被hadoop的配置变量进行控制的。hive> SET mapred.job.tracker=myhost.mycompany.com:50030;hive> SET -v;上面的最后一条语句可以显示当前的所有配置。如果不加-v参数,则只显示与基础的hadoop配置不同的配置。
Local模式
hive> SET mapred.job.tracker=LOCAL;hive> SET hive.EXEC.mode.LOCAL.auto=FALSE;$ export PATH=$HIVE_HOME/bin:$PATH
修改Log路径
bin/hive -hiveconf hive.root.logger=INFO,consolebin/hive -hiveconf hive.root.logger=INFO,DRFAMETASTOREmodel描述文件位置:src/contrib/hive/metastore/src/modelDML Operations默认的文件分割呼号是ctr+a文件上传的默认目录是: hive-DEFAULT.xml 中的hive.metastore.warehouse.dir上传文件的两种方式:本地文件LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');远程文件 LOAD DATA INPATH '/user/myname/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');上面的命令会发生文件和目录的转移。将结果插入到HDFS INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='2008-08-15';将结果插入到本地文件INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
只定义mapper任务:py
import sysimport datetimeFOR line IN sys.stdin: line = line.strip() userid, movieid, rating, unixtime = line.split('\t') weekday = datetime.datetime.fromtimestamp(FLOAT(unixtime)).isoweekday() print '\t'.JOIN([userid, movieid, rating, str(weekday)])CREATE TABLE u_data_new ( userid INT, movieid INT, rating INT, weekday INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t';ADD FILE weekday_mapper.py;INSERT OVERWRITE TABLE u_data_newSELECT TRANSFORM (userid, movieid, rating, unixtime) USING 'python weekday_mapper.py' AS (userid, movieid, rating, weekday)FROM u_data;SELECT weekday, COUNT(*)FROM u_data_newGROUP BY weekday;原文地址:ApacheHive一点一点进步(1) 简单介绍, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The easiest way to query the hard drive serial number
Feb 26, 2024 pm 02:24 PM
The easiest way to query the hard drive serial number
Feb 26, 2024 pm 02:24 PM
The hard disk serial number is an important identifier of the hard disk and is usually used to uniquely identify the hard disk and identify the hardware. In some cases, we may need to query the hard drive serial number, such as when installing an operating system, finding the correct device driver, or performing hard drive repairs. This article will introduce some simple methods to help you check the hard drive serial number. Method 1: Use Windows Command Prompt to open the command prompt. In Windows system, press Win+R keys, enter "cmd" and press Enter key to open the command
 Detailed introduction to what wapi is
Jan 07, 2024 pm 09:14 PM
Detailed introduction to what wapi is
Jan 07, 2024 pm 09:14 PM
Users may have seen the term wapi when using the Internet, but for some people they definitely don’t know what wapi is. The following is a detailed introduction to help those who don’t know to understand. What is wapi: Answer: wapi is the infrastructure for wireless LAN authentication and confidentiality. This is like functions such as infrared and Bluetooth, which are generally covered near places such as office buildings. Basically they are owned by a small department, so the scope of this function is only a few kilometers. Related introduction to wapi: 1. Wapi is a transmission protocol in wireless LAN. 2. This technology can avoid the problems of narrow-band communication and enable better communication. 3. Only one code is needed to transmit the signal
 Detailed explanation of whether win11 can run PUBG game
Jan 06, 2024 pm 07:17 PM
Detailed explanation of whether win11 can run PUBG game
Jan 06, 2024 pm 07:17 PM
Pubg, also known as PlayerUnknown's Battlegrounds, is a very classic shooting battle royale game that has attracted a lot of players since its popularity in 2016. After the recent launch of win11 system, many players want to play it on win11. Let's follow the editor to see if win11 can play pubg. Can win11 play pubg? Answer: Win11 can play pubg. 1. At the beginning of win11, because win11 needed to enable tpm, many players were banned from pubg. 2. However, based on player feedback, Blue Hole has solved this problem, and now you can play pubg normally in win11. 3. If you meet a pub
 Introduction to Python functions: Introduction and examples of exec function
Nov 03, 2023 pm 02:09 PM
Introduction to Python functions: Introduction and examples of exec function
Nov 03, 2023 pm 02:09 PM
Introduction to Python functions: Introduction and examples of exec function Introduction: In Python, exec is a built-in function that is used to execute Python code stored in a string or file. The exec function provides a way to dynamically execute code, allowing the program to generate, modify, and execute code as needed during runtime. This article will introduce how to use the exec function and give some practical code examples. How to use the exec function: The basic syntax of the exec function is as follows: exec
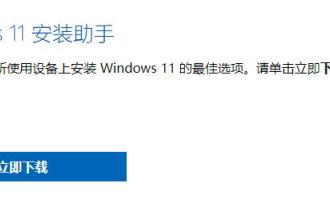 Detailed introduction to whether i5 processor can install win11
Dec 27, 2023 pm 05:03 PM
Detailed introduction to whether i5 processor can install win11
Dec 27, 2023 pm 05:03 PM
i5 is a series of processors owned by Intel. It has various versions of the 11th generation i5, and each generation has different performance. Therefore, whether the i5 processor can install win11 depends on which generation of the processor it is. Let’s follow the editor to learn about it separately. Can i5 processor be installed with win11: Answer: i5 processor can be installed with win11. 1. The eighth-generation and subsequent i51, eighth-generation and subsequent i5 processors can meet Microsoft’s minimum configuration requirements. 2. Therefore, we only need to enter the Microsoft website and download a "Win11 Installation Assistant" 3. After the download is completed, run the installation assistant and follow the prompts to install Win11. 2. i51 before the eighth generation and after the eighth generation
 How to write a simple online reservation system through PHP
Sep 26, 2023 pm 09:55 PM
How to write a simple online reservation system through PHP
Sep 26, 2023 pm 09:55 PM
How to write a simple online reservation system through PHP. With the popularity of the Internet and users' pursuit of convenience, online reservation systems are becoming more and more popular. Whether it is a restaurant, hospital, beauty salon or other service industry, a simple online reservation system can improve efficiency and provide users with a better service experience. This article will introduce how to use PHP to write a simple online reservation system and provide specific code examples. Create database and tables First, we need to create a database to store reservation information. In MyS
 How to write a simple student performance report generator using Java?
Nov 03, 2023 pm 02:57 PM
How to write a simple student performance report generator using Java?
Nov 03, 2023 pm 02:57 PM
How to write a simple student performance report generator using Java? Student Performance Report Generator is a tool that helps teachers or educators quickly generate student performance reports. This article will introduce how to use Java to write a simple student performance report generator. First, we need to define the student object and student grade object. The student object contains basic information such as the student's name and student number, while the student score object contains information such as the student's subject scores and average grade. The following is the definition of a simple student object: public
 Introducing the latest Win 11 sound tuning method
Jan 08, 2024 pm 06:41 PM
Introducing the latest Win 11 sound tuning method
Jan 08, 2024 pm 06:41 PM
After updating to the latest win11, many users find that the sound of their system has changed slightly, but they don’t know how to adjust it. So today, this site brings you an introduction to the latest win11 sound adjustment method for your computer. It is not difficult to operate. And the choices are diverse, come and download and try them out. How to adjust the sound of the latest computer system Windows 11 1. First, right-click the sound icon in the lower right corner of the desktop and select "Playback Settings". 2. Then enter settings and click "Speaker" in the playback bar. 3. Then click "Properties" on the lower right. 4. Click the "Enhance" option bar in the properties. 5. At this time, if the √ in front of "Disable all sound effects" is checked, cancel it. 6. After that, you can select the sound effects below to set and click
