

Adding Filter in Hadoop Mapper Class

There is my solutions to tackle the disk spaces shortage problem I described in the previous post. The core principle of the solution is to reduce the number of output records at Mapper stage; the method I used is Filter , adding a filter,
There is my solutions to tackle the disk spaces shortage problem I described in the previous post. The core principle of the solution is to reduce the number of output records at Mapper stage; the method I used is Filter, adding a filter, which I will explain later, to decrease the output records of Mapper, which in turn significantly decrease the Mapper’s Spill records, and fundamentally decrease the disk space usages. After applying the filter, with 30,661 records. some 200MB data set as inputs, the total Spill Records is 25,471,725, and it only takes about 509MB disk spaces!
Followed Filter
And now I’m going to reveal what’s kinda Filter it looks like, and how did I accomplish that filter. The true face of the FILTER is called Followed Filter, it filters users from computing co-followed combinations if their followed number does not satisfy a certain number, called Followed Threshold.
Followed Filter is used to reduce the co-followed combinations at Mapper stage. Say we set the followed threshold to 100, meaning users who doesn’t own 100 fans(be followed by 100 other users) will be ignored during co-followed combinations computing stage(to get the actual number of the threshold we need analyze statistics of user’s followed number of our data set).
Reason
Choosing followed filter is reasonable because how many user follows is a metric of user’s popularity/famousness.
HOW
In order to accomplish it, we need:
First, counting user’s followed number among our data set, which needs a new MapReduce Job;
Second, choosing a followed threshold after analyze the statistics perspective of followed number data set got in first step;
Third, using DistrbutedCache of Hadoop to cache users who satisfy the filter to all Mappers;
Forth, adding followed filter to Mapper class, only users satisfy filter condition will be passed into co-followed combination computing phrase;
Fifth, adding co-followed filter/threshold in Reducer side if necessary.
Outcomes
Here is the Hadoop Job Summary, after applying the followed filter with followed threshold of 1000, that means only users who are followed by 1000 users will have the opportunity to co-followed combinations, compared with the Job Summary in my previous post, most all metrics have significant improvements:
| Counter | Map | Reduce | Total |
| Bytes Written | 0 | 1,798,185 | 1,798,185 |
| Bytes Read | 203,401,876 | 0 | 203,401,876 |
| FILE_BYTES_READ | 405,219,906 | 52,107,486 | 457,327,392 |
| HDFS_BYTES_READ | 203,402,751 | 0 | 203,402,751 |
| FILE_BYTES_WRITTEN | 457,707,759 | 52,161,704 | 509,869,463 |
| HDFS_BYTES_WRITTEN | 0 | 1,798,185 | 1,798,185 |
| Reduce input groups | 0 | 373,680 | 373,680 |
| Map output materialized bytes | 52,107,522 | 0 | 52,107,522 |
| Combine output records | 22,202,756 | 0 | 22,202,756 |
| Map input records | 30,661 | 0 | 30,661 |
| Reduce shuffle bytes | 0 | 52,107,522 | 52,107,522 |
| Physical memory (bytes) snapshot | 2,646,589,440 | 116,408,320 | 2,762,997,760 |
| Reduce output records | 0 | 373,680 | 373,680 |
| Spilled Records | 22,866,351 | 2,605,374 | 25,471,725 |
| Map output bytes | 2,115,139,050 | 0 | 2,115,139,050 |
| Total committed heap usage (bytes) | 2,813,853,696 | 84,738,048 | 2,898,591,744 |
| CPU time spent (ms) | 5,766,680 | 11,210 | 5,777,890 |
| Virtual memory (bytes) snapshot | 9,600,737,280 | 1,375,002,624 | 10,975,739,904 |
| SPLIT_RAW_BYTES | 875 | 0 | 875 |
| Map output records | 117,507,725 | 0 | 117,507,725 |
| Combine input records | 137,105,107 | 0 | 137,105,107 |
| Reduce input records | 0 | 2,605,374 | 2,605,374 |
P.S.
Frankly Speaking, chances are I am on the wrong way to Hadoop Programming, since I’m palying Pesudo Distribution Hadoop with my personal computer, which has 4 CUPs and 4G RAM, in real Hadoop Cluster disk spaces might never be a trouble, and all the tuning work I have done may turn into meaningless efforts. Before the Followed Filter, I also did some Hadoop tuning like customed Writable class, RawComparator, block size and io.sort.mb, etc.
---EOF---
原文地址:Adding Filter in Hadoop Mapper Class, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Java Errors: Hadoop Errors, How to Handle and Avoid
Jun 24, 2023 pm 01:06 PM
Java Errors: Hadoop Errors, How to Handle and Avoid
Jun 24, 2023 pm 01:06 PM
Java Errors: Hadoop Errors, How to Handle and Avoid When using Hadoop to process big data, you often encounter some Java exception errors, which may affect the execution of tasks and cause data processing to fail. This article will introduce some common Hadoop errors and provide ways to deal with and avoid them. Java.lang.OutOfMemoryErrorOutOfMemoryError is an error caused by insufficient memory of the Java virtual machine. When Hadoop is
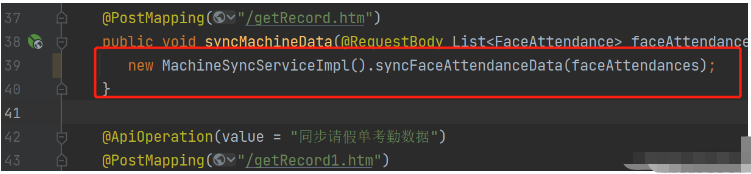 How to solve the problem of empty mapper automatically injected into idea springBoot project
May 17, 2023 pm 06:49 PM
How to solve the problem of empty mapper automatically injected into idea springBoot project
May 17, 2023 pm 06:49 PM
In the SpringBoot project, if MyBatis is used as the persistence layer framework, you may encounter the problem of mapper reporting a null pointer exception when using automatic injection. This is because SpringBoot cannot correctly identify the Mapper interface of MyBatis during automatic injection and requires some additional configuration. There are two ways to solve this problem: 1. Add annotations to the Mapper interface. Add the @Mapper annotation to the Mapper interface to tell SpringBoot that this interface is a Mapper interface and needs to be proxied. An example is as follows: @MapperpublicinterfaceUserMapper{//...}2
![How to solve the '[Vue warn]: Failed to resolve filter' error](https://img.php.cn/upload/article/000/887/227/169243040583797.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) How to solve the '[Vue warn]: Failed to resolve filter' error
Aug 19, 2023 pm 03:33 PM
How to solve the '[Vue warn]: Failed to resolve filter' error
Aug 19, 2023 pm 03:33 PM
Methods to solve the "[Vuewarn]:Failedtoresolvefilter" error During the development process using Vue, we sometimes encounter an error message: "[Vuewarn]:Failedtoresolvefilter". This error message usually occurs when we use an undefined filter in the template. This article explains how to resolve this error and gives corresponding code examples. When we are in Vue
 How does springboot specify the mapper file scanning path in mybatis?
May 17, 2023 pm 10:25 PM
How does springboot specify the mapper file scanning path in mybatis?
May 17, 2023 pm 10:25 PM
Specify all mapper mapping files in the mapper file scan path in mybatis mybatis.mapper-locations=classpath*:com/springboot/mapper/*.xml or mapper mapping files under resource mybatis.mapper-locations=classpath*:mapper/** /*.xmlmybatis configures multiple scan paths. The writing method was obtained from Baidu, but it is very messy. Let’s sort it out a little: I recently dismantled the project and encountered a small problem. I will record it a little:
 Using Hadoop and HBase in Beego for big data storage and querying
Jun 22, 2023 am 10:21 AM
Using Hadoop and HBase in Beego for big data storage and querying
Jun 22, 2023 am 10:21 AM
With the advent of the big data era, data processing and storage have become more and more important, and how to efficiently manage and analyze large amounts of data has become a challenge for enterprises. Hadoop and HBase, two projects of the Apache Foundation, provide a solution for big data storage and analysis. This article will introduce how to use Hadoop and HBase in Beego for big data storage and query. 1. Introduction to Hadoop and HBase Hadoop is an open source distributed storage and computing system that can
 How to use PHP and Hadoop for big data processing
Jun 19, 2023 pm 02:24 PM
How to use PHP and Hadoop for big data processing
Jun 19, 2023 pm 02:24 PM
As the amount of data continues to increase, traditional data processing methods can no longer handle the challenges brought by the big data era. Hadoop is an open source distributed computing framework that solves the performance bottleneck problem caused by single-node servers in big data processing through distributed storage and processing of large amounts of data. PHP is a scripting language that is widely used in web development and has the advantages of rapid development and easy maintenance. This article will introduce how to use PHP and Hadoop for big data processing. What is HadoopHadoop is
 Explore the application of Java in the field of big data: understanding of Hadoop, Spark, Kafka and other technology stacks
Dec 26, 2023 pm 02:57 PM
Explore the application of Java in the field of big data: understanding of Hadoop, Spark, Kafka and other technology stacks
Dec 26, 2023 pm 02:57 PM
Java big data technology stack: Understand the application of Java in the field of big data, such as Hadoop, Spark, Kafka, etc. As the amount of data continues to increase, big data technology has become a hot topic in today's Internet era. In the field of big data, we often hear the names of Hadoop, Spark, Kafka and other technologies. These technologies play a vital role, and Java, as a widely used programming language, also plays a huge role in the field of big data. This article will focus on the application of Java in large
 How to install Hadoop in linux
May 18, 2023 pm 08:19 PM
How to install Hadoop in linux
May 18, 2023 pm 08:19 PM
1: Install JDK1. Execute the following command to download the JDK1.8 installation package. wget--no-check-certificatehttps://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz2. Execute the following command to decompress the downloaded JDK1.8 installation package. tar-zxvfjdk-8u151-linux-x64.tar.gz3. Move and rename the JDK package. mvjdk1.8.0_151//usr/java84. Configure Java environment variables. echo'
