

Libbson

Libbson is a new shared library written in C for developers wanting to work with the BSON serialization format. Its API will feel natural to C programmers but can also be used as the base of a C extension in higher-level MongoDB drivers. T
Libbson is a new shared library written in C for developers wanting to work with the BSON serialization format.
Its API will feel natural to C programmers but can also be used as the base of a C extension in higher-level MongoDB drivers.
The library contains everything you would expect from a BSON implementation. It has the ability to work with documents in their serialized form, iterating elements within a document, overwriting fields in place, Object Id generation, JSON conversion, data validation, and more. Some lessons were learned along the way that are beneficial for those choosing to implement BSON themselves.
Improving small document performance
A common use case of BSON is for relatively small documents. This has a profound impact on the memory allocator in userspace, causing what is commonly known as “memory fragmentation”. Memory fragmentation can make it more difficult for your allocator to locate a contiguous region of memory.
In addition to increasing allocation latency, it increases the memory requirements of your application to overcome that fragmentation.
To help with this issue, the bson_t structure contains 120 bytes of inline space that allows BSON documents to be built directly on the stack as opposed to the heap.
When the document size grows past 120 bytes it will automatically migrate to a heap allocation.
Additionally, bson_t will grow it’s buffers in powers of two. This is standard when working with buffers and arrays as it amortizes the overhead of growing the buffer versus calling realloc() every time data is appended. 120 bytes was chosen to align bson_t to the size of two sequential cachelines on x86_64 (each 64 bytes).
This may change based on future research, but not before a stable ABI has been reached.
Single allocation for nested documents
One strength of BSON is it’s ability to nest objects and arrays. Often times when serializing these nested documents, each sub-document is serialized independently and then appended to the parents buffer.
As you might imagine, this takes quite the toll on the allocator. It can generate many small allocations which were only created to have been immediately discarded after appending to the parents buffer. Libbson allows for building sub-documents directly into the parent documents buffer.
Doing so helps avoid this costly fragmentation. The topmost document will grow its underlying buffers in powers of two each time the allocation would overflow.
Parsing BSON documents from network buffers
Another common area for allocator fragmentation is during BSON document parsing. Libbson allows parsing and iteration of BSON documents directly from your incoming network buffer.
This means the only allocations created are those needed for your higher level language such as a PyDict if writing a Python extension.
Developers writing C extensions for their driver may choose to implement a “generator” style parsing of documents to help keep memory fragmentation low.
A technique we’re yet to explore is implementing a hashtable-esque structure backed by BSON, only deserializing the entire buffer after a threshold of keys have been accessed.
Generating BSON documents into network buffers
Much like parsing BSON documents, generating documents and placing them into your network buffers can be hard on your memory allocator. To help keep this fragmentation down, Libbson provides support for serializing your document to BSON directly within a buffer of your choosing.
This is ideal for situations such as writing a sequence of BSON documents into a MongoDB message.
Generating Object Ids without Synchronization
Applications are often doing ObjectId generation, especially in high insert environments. The uniqueness of generated ObjectIds is critical to avoiding duplicate key errors across multiple nodes.
Highly threaded environments create a local contention point slowing the rate of generation. This is because the threads must synchronize on the increment counter of each sequential ObjectId. Failure to do so could cause collisions that would not be detected until after a network round-trip. Most drivers implement the synchronization with an atomic increment or a mutex if atomics are not available.
Libbson will use atomic increments and in some cases avoid synchronization altogether if possible. One such case is a non-threaded environment.
Another is when running on Linux as both threads and processes are in the same namespace.
This allows the use of the thread identifier as the pid within the ObjectId.
You can find Libbson at https://github.com/mongodb/libbson and discuss design choices with its author, Christian Hergert, who can be found on twitter as @hergertme.
原文地址:Libbson, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

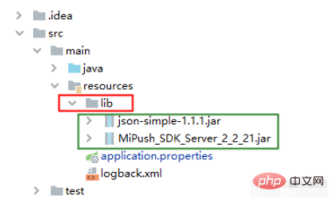 How to introduce local dependency jar package into springboot project and package it into lib folder
May 11, 2023 am 11:37 AM
How to introduce local dependency jar package into springboot project and package it into lib folder
May 11, 2023 am 11:37 AM
Preface: At work, I encountered a Javaweb project built with the SpringBoot framework that needed to integrate third-party push functions, so I used the Xiaomi push service and downloaded the relevant jar package. Introducing local jars into the project is not a big problem. After writing the code, it is no problem to pass the test class test. Then prepare to package and deploy to the development server. Since the project is deployed through tomcat, the packaging method is into a war package. After packaging, upload it to the development server. After successful startup, I went to test the written push interface and found that it failed. Through analysis, it was found that the lib directory in the packaged war where the project's dependent jars are stored does not contain locally introduced push-related jar packages. After struggling for half an hour, the problem was solved. solve
 What does lib refer to in linux?
May 23, 2023 pm 07:20 PM
What does lib refer to in linux?
May 23, 2023 pm 07:20 PM
In Linux, lib is the library file directory, which contains all library files useful to the system; library files are files required for the correct execution of applications, commands, or processes. The role of lib is similar to the DLL file in Windows. Almost all applications need to use the shared library files in the lib directory. lib is the abbreviation of Library (library). This directory stores the most basic dynamic link shared library of the system, and its function is similar to the DLL file in Windows. Almost all applications require these shared libraries. The /lib folder is the library file directory and contains all library files useful to the system. Simply put, it is a file that is required for the correct execution of an application, command, or process. in/bi
 What is the difference between make and new in go language
Jan 09, 2023 am 11:44 AM
What is the difference between make and new in go language
Jan 09, 2023 am 11:44 AM
Differences: 1. Make can only be used to allocate and initialize data of types slice, map, and chan; while new can allocate any type of data. 2. New allocation returns a pointer, which is the type "*Type"; while make returns a reference, which is Type. 3. The space allocated by new will be cleared; after make allocates the space, it will be initialized.
 How to use the new keyword in java
May 03, 2023 pm 10:16 PM
How to use the new keyword in java
May 03, 2023 pm 10:16 PM
1. Concept In the Java language, the "new" expression is responsible for creating an instance, in which the constructor is called to initialize the instance; the return value type of the constructor itself is void, not "the constructor returns the newly created Object reference", but the value of the new expression is a reference to the newly created object. 2. Purpose: Create an object of a new class. 3. Working mechanism: Allocate memory space for object members, and specify default values. Explicitly initialize member variables, perform construction method calculations, and return reference values. 4. Instance new operation often means opening up new memory in the memory. The memory space is allocated in the heap area in the memory. It is controlled by jvm and automatically manages the memory. Here we use the String class as an example. Pu
 Oukitel unleashes new C50, rugged WP39 and WP50 smartphones at budget-friendly prices
Jun 21, 2024 am 07:10 AM
Oukitel unleashes new C50, rugged WP39 and WP50 smartphones at budget-friendly prices
Jun 21, 2024 am 07:10 AM
 What to do if linux cannot find lib
Feb 28, 2023 am 09:59 AM
What to do if linux cannot find lib
Feb 28, 2023 am 09:59 AM
Solution to Linux not finding lib: 1. Copy the lib library in the program to the "/lib" or "/usr/local/lib" directory, and then execute "ldconfig"; 2. In "ld.so.conf "Add the directory where the library file is located, and then update the "ld.so.cache" file.
 How does the new operator work in js?
Feb 19, 2024 am 11:17 AM
How does the new operator work in js?
Feb 19, 2024 am 11:17 AM
How does the new operator in js work? Specific code examples are needed. The new operator in js is a keyword used to create objects. Its function is to create a new instance object based on the specified constructor and return a reference to the object. When using the new operator, the following steps are actually performed: create a new empty object; point the prototype of the empty object to the prototype object of the constructor; assign the scope of the constructor to the new object (so this points to new object); execute the code in the constructor and give the new object
 New Fujifilm fixed-lens GFX camera to debut new medium format sensor, could kick off all-new series
Sep 27, 2024 am 06:03 AM
New Fujifilm fixed-lens GFX camera to debut new medium format sensor, could kick off all-new series
Sep 27, 2024 am 06:03 AM
Fujifilm has seen a lot of success in recent years, largely due to its film simulations and the popularity of its compact rangefinger-style cameras on social media. However, it doesn't seem to be resting on its laurels, according to Fujirumors. The u
