

hadoop wordcount新API例子

准备 准备一些输入文件,可以用hdfs dfs -put xxx/*?/user/fatkun/input上传文件 代码 package com.fatkun;?import java.io.IOException;import java.util.ArrayList;import java.util.List;import java.util.StringTokenizer;?import org.apache.commons.lo
准备
准备一些输入文件,可以用hdfs dfs -put xxx/*?/user/fatkun/input上传文件
代码
package com.fatkun;
?
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
?
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
?
public class WordCount extends Configured implements Tool {
static enum Counters {
INPUT_WORDS // 计数器
}
?
static Log logger = LogFactory.getLog(WordCount.class);
?
public static class CountMapper extends
Mapper {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive = true;
?
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
// 读取配置
Configuration conf = context.getConfiguration();
caseSensitive = conf.getBoolean("wordcount.case.sensitive", true);
super.setup(context);
}
?
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
if (caseSensitive) { // 是否大小写敏感
word.set(itr.nextToken());
} else {
word.set(itr.nextToken().toLowerCase());
}
context.write(word, one);
context.getCounter(Counters.INPUT_WORDS).increment(1);
}
}
}
?
public static class CountReducer extends
Reducer {
?
@Override
protected void reduce(Text text, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(text, new IntWritable(sum));
}
?
}
?
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration(getConf());
Job job = Job.getInstance(conf, "Example Hadoop WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(CountMapper.class);
job.setCombinerClass(CountReducer.class);
job.setReducerClass(CountReducer.class);
?
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
?
List other_args = new ArrayList();
for (int i = 0; i
<h2 id="运行">运行</h2>
<p>在eclipse导出jar包,执行以下命令</p>
<pre class="brush:php;toolbar:false">hadoop jar wordcount.jar com.fatkun.WordCount -Dwordcount.case.sensitive=false /user/fatkun/input /user/fatkun/output参考
http://cxwangyi.blogspot.com/2009/12/wordcount-tutorial-for-hadoop-0201.html
http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html#Example%3A+WordCount+v2.0
原文地址:hadoop wordcount新API例子, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



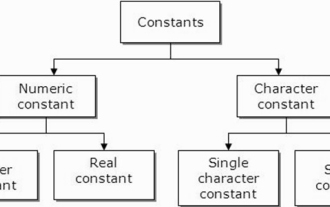 What are constants in C language? Can you give an example?
Aug 28, 2023 pm 10:45 PM
What are constants in C language? Can you give an example?
Aug 28, 2023 pm 10:45 PM
A constant is also called a variable and once defined, its value does not change during the execution of the program. Therefore, we can declare a variable as a constant referencing a fixed value. It is also called text. Constants must be defined using the Const keyword. Syntax The syntax of constants used in C programming language is as follows - consttypeVariableName; (or) consttype*VariableName; Different types of constants The different types of constants used in C programming language are as follows: Integer constants - For example: 1,0,34, 4567 Floating point constants - Example: 0.0, 156.89, 23.456 Octal and Hexadecimal constants - Example: Hex: 0x2a, 0xaa.. Octal
 How to crawl and process data by calling API interface in PHP project?
Sep 05, 2023 am 08:41 AM
How to crawl and process data by calling API interface in PHP project?
Sep 05, 2023 am 08:41 AM
How to crawl and process data by calling API interface in PHP project? 1. Introduction In PHP projects, we often need to crawl data from other websites and process these data. Many websites provide API interfaces, and we can obtain data by calling these interfaces. This article will introduce how to use PHP to call the API interface to crawl and process data. 2. Obtain the URL and parameters of the API interface. Before starting, we need to obtain the URL of the target API interface and the required parameters.
 React API Call Guide: How to interact and transfer data with the backend API
Sep 26, 2023 am 10:19 AM
React API Call Guide: How to interact and transfer data with the backend API
Sep 26, 2023 am 10:19 AM
ReactAPI Call Guide: How to interact with and transfer data to the backend API Overview: In modern web development, interacting with and transferring data to the backend API is a common need. React, as a popular front-end framework, provides some powerful tools and features to simplify this process. This article will introduce how to use React to call the backend API, including basic GET and POST requests, and provide specific code examples. Install the required dependencies: First, make sure Axi is installed in the project
 Oracle API Usage Guide: Exploring Data Interface Technology
Mar 07, 2024 am 11:12 AM
Oracle API Usage Guide: Exploring Data Interface Technology
Mar 07, 2024 am 11:12 AM
Oracle is a world-renowned database management system provider, and its API (Application Programming Interface) is a powerful tool that helps developers easily interact and integrate with Oracle databases. In this article, we will delve into the Oracle API usage guide, show readers how to utilize data interface technology during the development process, and provide specific code examples. 1.Oracle
 Oracle API integration strategy analysis: achieving seamless communication between systems
Mar 07, 2024 pm 10:09 PM
Oracle API integration strategy analysis: achieving seamless communication between systems
Mar 07, 2024 pm 10:09 PM
OracleAPI integration strategy analysis: To achieve seamless communication between systems, specific code examples are required. In today's digital era, internal enterprise systems need to communicate with each other and share data, and OracleAPI is one of the important tools to help achieve seamless communication between systems. This article will start with the basic concepts and principles of OracleAPI, explore API integration strategies, and finally give specific code examples to help readers better understand and apply OracleAPI. 1. Basic Oracle API
 Save API data to CSV format using Python
Aug 31, 2023 pm 09:09 PM
Save API data to CSV format using Python
Aug 31, 2023 pm 09:09 PM
In the world of data-driven applications and analytics, APIs (Application Programming Interfaces) play a vital role in retrieving data from various sources. When working with API data, you often need to store the data in a format that is easy to access and manipulate. One such format is CSV (Comma Separated Values), which allows tabular data to be organized and stored efficiently. This article will explore the process of saving API data to CSV format using the powerful programming language Python. By following the steps outlined in this guide, we will learn how to retrieve data from the API, extract relevant information, and store it in a CSV file for further analysis and processing. Let’s dive into the world of API data processing with Python and unlock the potential of the CSV format
 How to deal with Laravel API error problems
Mar 06, 2024 pm 05:18 PM
How to deal with Laravel API error problems
Mar 06, 2024 pm 05:18 PM
Title: How to deal with Laravel API error problems, specific code examples are needed. When developing Laravel, API errors are often encountered. These errors may come from various reasons such as program code logic errors, database query problems, or external API request failures. How to handle these error reports is a key issue. This article will use specific code examples to demonstrate how to effectively handle Laravel API error reports. 1. Error handling in Laravel
 PHP API Interface: Getting Started Guide
Aug 25, 2023 am 11:45 AM
PHP API Interface: Getting Started Guide
Aug 25, 2023 am 11:45 AM
PHP is a popular server-side scripting language used for building web applications and websites. It can interact with various different types of API interfaces and is very convenient during the development process. In this article, we will provide an introductory guide to the PHP API interface to help beginners learn to use it faster. What is an API? API stands for "Application Programming Interface", which is a standardized way that allows different applications to exchange data and information between them. This interaction is achieved by visiting a website on W
