

HDFS集中式的缓存管理原理与代码剖析

Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。 主要解决了哪些问题 1.用户可
Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。
主要解决了哪些问题
1.用户可以根据自己的逻辑指定一些经常被使用的数据或者高优先级任务对应的数据常驻内存而不被淘汰到磁盘。例如在Hive或Impala构建的数据仓库应用中fact表会频繁地与其他表做JOIN,显然应该让fact常驻内存,这样DataNode在内存使用紧张的时候也不会把这些数据淘汰出去,同时也实现了对于?mixed workloads的SLA。
2.centralized cache是由NameNode统一管理的,那么HDFS client(例如MapReduce、Impala)就可以根据block被cache的分布情况去调度任务,做到memory-locality。
3.HDFS原来单纯靠DataNode的OS buffer cache,这样不但没有把block被cache的分布情况对外暴露给上层应用优化任务调度,也有可能会造成cache浪费。例如一个block的三个replica分别存储在三个DataNote 上,有可能这个block同时被这三台DataNode的OS buffer cache,那么从HDFS的全局看就有同一个block在cache中存了三份,造成了资源浪费。?
4.加快HDFS client读速度。过去NameNode处理读请求时只根据拓扑远近决定去哪个DataNode读,现在还要加入speed的因素。当HDFS client和要读取的block被cache在同一台DataNode的时候,可以通过zero-copy read直接从内存读,略过磁盘I/O、checksum校验等环节。
5.即使数据被cache的DataNode节点宕机,block移动,集群重启,cache都不会受到影响。因为cache被NameNode统一管理并被被持久化到FSImage和EditLog,如果cache的某个block的DataNode宕机,NameNode会调度其他存储了这个replica的DataNode,把它cache到内存。
基本概念
cache directive: 表示要被cache到内存的文件或者目录。
cache pool: 用于管理一系列的cache directive,类似于命名空间。同时使用UNIX风格的文件读、写、执行权限管理机制。命令例子:
hdfs cacheadmin -addDirective -path /user/hive/warehouse/fact.db/city -pool financial -replication 1?
以上代码表示把HDFS上的文件city(其实是hive上的一个fact表)放到HDFS centralized cache的financial这个cache pool下,而且这个文件只需要被缓存一份。
系统架构与原理
 用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
DFSClient读取文件时向NameNode发送getBlockLocations RPC请求。NameNode会返回一个LocatedBlock列表给DFSClient,这个LocatedBlock对象里有这个block的replica所在的DataNode和cache了这个block的DataNode。可以理解为把被cache到内存中的replica当做三副本外的一个高速的replica。
注:centralized cache和distributed cache的区别:
distributed cache将文件分发到各个DataNode结点本地磁盘保存,并且用完后并不会被立即清理的,而是由专门的一个线程根据文件大小限制和文件数目上限周期性进行清理。本质上distributed cache只做到了disk locality,而centralized cache做到了memory locality。
实现逻辑与代码剖析
HDFS centralized cache涉及到多个操作,其处理逻辑非常类似。为了简化问题,以addDirective这个操作为例说明。
1.NameNode处理逻辑
 NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
DFSClient给NameNode发送名为addCacheDirective的RPC, 在ClientNamenodeProtocol.proto这个文件中定义相应的接口。
NameNode接收到这个RPC之后处理,首先把这个需要被缓存的Path包装成CacheDirective加入CacheManager所管理的directivesByPath中。这时对应的File/Directory并没有被cache到内存。
一旦CacheManager那边添加了新的CacheDirective,触发CacheReplicationMonitor.rescan()来扫描并把需要通知DataNode做cache的block加入到CacheReplicationMonitor. cachedBlocks映射中。这个rescan操作在NameNode启动时也会触发,同时在NameNode运行期间以固定的时间间隔触发。
Rescan()函数主要逻辑如下:
rescanCacheDirectives()->rescanFile():依次遍历每个等待被cache的directive(存储在CacheManager. directivesByPath里),把每个等待被cache的directive包含的block都加入到CacheReplicationMonitor.cachedBlocks集合里面。
rescanCachedBlockMap():调用CacheReplicationMonitor.addNewPendingCached()为每个等待被cache的block选择一个合适的DataNode去cache(一般是选择这个block的三个replica所在的DataNode其中的剩余可用内存最多的一个),加入对应的DatanodeDescriptor的pendingCached列表。
2.NameNode与DataNode的RPC逻辑
DataNode定期向NameNode发送heartbeat RPC用于表明它还活着,同时DataNode还会向NameNode定期发送block report(默认6小时)和cache block(默认10秒)用于同步block和cache的状态。
NameNode会在每次处理某一DataNode的heartbeat RPC时顺便检查该DataNode的pendingCached列表是否为空,不为空的话发送DatanodeProtocol.DNA_CACHE命令给具体的DataNode去cache对应的block replica。
3.DataNode处理逻辑
 DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
在DataNode节点上每个BlockPool对应有一个BPServiceActor线程向NameNode发送heartbeat、接收response并处理。如果接收到来自NameNode的RPC里面的命令是DatanodeProtocol.DNA_CACHE,那么调用FsDatasetImpl.cacheBlock()把对应的block cache到内存。
这个函数先是通过RPC传过来的blockId找到其对应的FsVolumeImpl (因为执行cache block操作的线程cacheExecutor是绑定在对应的FsVolumeImpl里的);然后调用FsDatasetCache.cacheBlock()把这个block封装成MappableBlock加入到mappableBlockMap里统一管理起来,然后向对应的FsVolumeImpl.cacheExecutor线程池提交一个CachingTask异步任务(cache的过程是异步执行的)。
FsDatasetCache有个成员mappableBlockMap(HashMap)管理着这台DataNode的所有的MappableBlock及其状态(caching/cached/uncaching)。目前DataNode中”哪些block被cache到内存里了”也是只保存了soft state(和NameNode的block map一样),是DataNode向NameNode 发送heartbeat之后从NameNode那问回来的,没有持久化到DataNode本地硬盘。
CachingTask的逻辑: 调用MappableBlock.load()方法把对应的block从DataNode本地磁盘通过mmap映射到内存中,然后通过mlock锁定这块内存空间,并对这个映射到内存的block做checksum检验其完整性。这样对于memory-locality的DFSClient就可以通过zero-copy直接读内存中的block而不需要校验了。
4.DFSClient读逻辑:
HDFS的读主要有三种: 网络I/O读 -> short circuit read -> zero-copy read。网络I/O读就是传统的HDFS读,通过DFSClient和Block所在的DataNode建立网络连接传输数据。?
当DFSClient和它要读取的block在同一台DataNode时,DFSClient可以跨过网络I/O直接从本地磁盘读取数据,这种读取数据的方式叫short circuit read。目前HDFS实现的short circuit read是通过共享内存获取要读的block在DataNode磁盘上文件的file descriptor(因为这样比传递文件目录更安全),然后直接用对应的file descriptor建立起本地磁盘输入流,所以目前的short circuit read也是一种zero-copy read。
增加了Centralized cache的HDFS的读接口并没有改变。DFSClient通过RPC获取LocatedBlock时里面多了个成员表示哪个DataNode把这个block cache到内存里面了。如果DFSClient和该block被cache的DataNode在一起,就可以通过zero-copy read大大提升读效率。而且即使在读取的过程中该block被uncache了,那么这个读就被退化成了本地磁盘读,一样能够获取数据。?
对上层应用的影响
对于HDFS上的某个目录已经被addDirective缓存起来之后,如果这个目录里新加入了文件,那么新加入的文件也会被自动缓存。这一点对于Hive/Impala式的应用非常有用。
HBase in-memory table:可以直接把某个HBase表的HFile放到centralized cache中,这会显著提高HBase的读性能,降低读请求延迟。
和Spark RDD的区别:多个RDD的之间的读写操作可能完全在内存中完成,出错就重算。HDFS centralized cache中被cache的block一定是先写到磁盘上的,然后才能显式被cache到内存。也就是说只能cache读,不能cache写。
目前的centralized cache不是DFSClient读了谁就会把谁cache,而是需要DFSClient显式指定要cache谁,cache多长时间,淘汰谁。目前也没有类似LRU的置换策略,如果内存不够用的时候需要client显式去淘汰对应的directive到磁盘。
现在还没有跟YARN整合,需要用户自己调整好留给DataNode用于cache的内存和NodeManager的内存使用。
参考文献
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html
https://issues.apache.org/jira/browse/HDFS-4949
原文地址:HDFS集中式的缓存管理原理与代码剖析, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Analysis of the function and principle of nohup
Mar 25, 2024 pm 03:24 PM
Analysis of the function and principle of nohup
Mar 25, 2024 pm 03:24 PM
Analysis of the role and principle of nohup In Unix and Unix-like operating systems, nohup is a commonly used command that is used to run commands in the background. Even if the user exits the current session or closes the terminal window, the command can still continue to be executed. In this article, we will analyze the function and principle of the nohup command in detail. 1. The role of nohup: Running commands in the background: Through the nohup command, we can let long-running commands continue to execute in the background without being affected by the user exiting the terminal session. This needs to be run
 How to view and refresh dns cache in Linux
Mar 07, 2024 am 08:43 AM
How to view and refresh dns cache in Linux
Mar 07, 2024 am 08:43 AM
DNS (DomainNameSystem) is a system used on the Internet to convert domain names into corresponding IP addresses. In Linux systems, DNS caching is a mechanism that stores the mapping relationship between domain names and IP addresses locally, which can increase the speed of domain name resolution and reduce the burden on the DNS server. DNS caching allows the system to quickly retrieve the IP address when subsequently accessing the same domain name without having to issue a query request to the DNS server each time, thereby improving network performance and efficiency. This article will discuss with you how to view and refresh the DNS cache on Linux, as well as related details and sample code. Importance of DNS Caching In Linux systems, DNS caching plays a key role. its existence
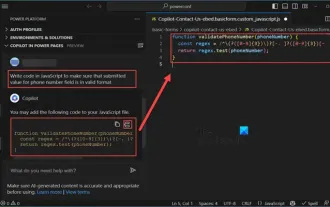 How to use Copilot to generate code
Mar 23, 2024 am 10:41 AM
How to use Copilot to generate code
Mar 23, 2024 am 10:41 AM
As a programmer, I get excited about tools that simplify the coding experience. With the help of artificial intelligence tools, we can generate demo code and make necessary modifications as per the requirement. The newly introduced Copilot tool in Visual Studio Code allows us to create AI-generated code with natural language chat interactions. By explaining functionality, we can better understand the meaning of existing code. How to use Copilot to generate code? To get started, we first need to get the latest PowerPlatformTools extension. To achieve this, you need to go to the extension page, search for "PowerPlatformTool" and click the Install button
 Create and run Linux ".a" files
Mar 20, 2024 pm 04:46 PM
Create and run Linux ".a" files
Mar 20, 2024 pm 04:46 PM
Working with files in the Linux operating system requires the use of various commands and techniques that enable developers to efficiently create and execute files, code, programs, scripts, and other things. In the Linux environment, files with the extension ".a" have great importance as static libraries. These libraries play an important role in software development, allowing developers to efficiently manage and share common functionality across multiple programs. For effective software development in a Linux environment, it is crucial to understand how to create and run ".a" files. This article will introduce how to comprehensively install and configure the Linux ".a" file. Let's explore the definition, purpose, structure, and methods of creating and executing the Linux ".a" file. What is L
 Caching mechanism and application practice in PHP development
May 09, 2024 pm 01:30 PM
Caching mechanism and application practice in PHP development
May 09, 2024 pm 01:30 PM
In PHP development, the caching mechanism improves performance by temporarily storing frequently accessed data in memory or disk, thereby reducing the number of database accesses. Cache types mainly include memory, file and database cache. Caching can be implemented in PHP using built-in functions or third-party libraries, such as cache_get() and Memcache. Common practical applications include caching database query results to optimize query performance and caching page output to speed up rendering. The caching mechanism effectively improves website response speed, enhances user experience and reduces server load.
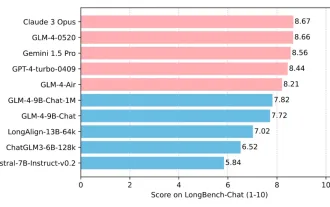 Tsinghua University and Zhipu AI open source GLM-4: launching a new revolution in natural language processing
Jun 12, 2024 pm 08:38 PM
Tsinghua University and Zhipu AI open source GLM-4: launching a new revolution in natural language processing
Jun 12, 2024 pm 08:38 PM
Since the launch of ChatGLM-6B on March 14, 2023, the GLM series models have received widespread attention and recognition. Especially after ChatGLM3-6B was open sourced, developers are full of expectations for the fourth-generation model launched by Zhipu AI. This expectation has finally been fully satisfied with the release of GLM-4-9B. The birth of GLM-4-9B In order to give small models (10B and below) more powerful capabilities, the GLM technical team launched this new fourth-generation GLM series open source model: GLM-4-9B after nearly half a year of exploration. This model greatly compresses the model size while ensuring accuracy, and has faster inference speed and higher efficiency. The GLM technical team’s exploration has not
 Create Agent in one sentence! Robin Li: The era is coming when everyone is a developer
Apr 17, 2024 pm 02:28 PM
Create Agent in one sentence! Robin Li: The era is coming when everyone is a developer
Apr 17, 2024 pm 02:28 PM
The big model subverts everything, and finally got to the head of this editor. It is also an Agent that was created in just one sentence. Like this, give him an article, and in less than 1 second, fresh title suggestions will come out. Compared to me, this efficiency can only be said to be as fast as lightning and as slow as a sloth... What's even more incredible is that creating this Agent really only takes a few minutes. Prompt belongs to Aunt Jiang: And if you also want to experience this subversive feeling, now, based on the new Wenxin intelligent agent platform launched by Baidu, everyone can create their own intelligent assistant for free. You can use search engines, smart hardware platforms, speech recognition, maps, cars and other Baidu mobile ecological channels to let more people use your creativity! Robin Li himself
 The relationship between CPU, memory and cache is explained in detail!
Mar 07, 2024 am 08:30 AM
The relationship between CPU, memory and cache is explained in detail!
Mar 07, 2024 am 08:30 AM
There is a close interaction between the CPU (central processing unit), memory (random access memory), and cache, which together form a critical component of a computer system. The coordination between them ensures the normal operation and efficient performance of the computer. As the brain of the computer, the CPU is responsible for executing various instructions and data processing; the memory is used to temporarily store data and programs, providing fast read and write access speeds; and the cache plays a buffering role, speeding up data access speed and improving The computer's CPU is the core component of the computer and is responsible for executing various instructions, arithmetic operations, and logical operations. It is called the "brain" of the computer and plays an important role in processing data and performing tasks. Memory is an important storage device in a computer.
