

hadoop本地目录相关代码分析

最近hadoop本地磁盘总是坏,伴随着有些hadoop job失败,阅读了一些相关的代码。 本地磁盘健康检查 NodeManager默认会每两分钟检查本地磁盘(local-dirs),找出那些目录可以使用。注意这里如果判定这个磁盘不可用,则在重启NodeManager之前,就算磁盘好了,
最近hadoop本地磁盘总是坏,伴随着有些hadoop job失败,阅读了一些相关的代码。
本地磁盘健康检查
NodeManager默认会每两分钟检查本地磁盘(local-dirs),找出那些目录可以使用。注意这里如果判定这个磁盘不可用,则在重启NodeManager之前,就算磁盘好了,也不会把它变成可用。代码在LocalDirsHandlerService,DirectoryCollection。
当好磁盘数少于一定量时,会把这台机器变成unhealthy,将不会再给这台机器分配任务。
参数 :
yarn.nodemanager.disk-health-checker.enable ? ? 是否开启磁盘健康检查,默认是开启 yarn.nodemanager.disk-health-checker.interval-ms 检查间隔时间,默认是2分钟 yarn.nodemanager.disk-health-checker.min-healthy-disks ?最少健康磁盘的个数,默认值是0.25,如果少于这个值,则把这个节点变成unhealthy
本地磁盘使用
NodeManager会从hdfs下载job.jar等东西,这叫资源本地化。代码在ResourceLocalizationService和DefaultContainerExecutor里。
token文件会使用第一个好的local-dirs,其他的文件会顺序的使用local-dirs,文件可能分散在各个盘上。
?AppMaster重试
AppMaster重试是由RM触发,代码在RMAppImpl的AttemptFailedTransition事件里。默认重试次数是1次(也就是不重试)
参数:
yarn.resourcemanager.am.max-retries AM最大重试次数
TaskAttempt重试
我们的map和reduce任务都是一个个TaskAttempt,TaskAttempt由AppMaster来管理,启动和重启的操作都是由AppMaster来处理。代码在TaskImpl的AttemptFailedTransition里
参数:
mapreduce.map.maxattempts map最大重试次数,默认是4 mapreduce.reduce.maxattempts reduce最大重试次数,默认是4
AppMaster资源分配
AppMaster会定时申请、释放container资源,代码在RMContainerRequestor.containerFailedOnHost
当taskAttempt在一个节点的失败数目超过一定上限(通过参数?mapreduce.job.maxtaskfailures.per.tracker 配置,默认是3),该节点会被加入临时的黑名单,为了防止大量的机器加入黑名单,还有个参数?yarn.app.mapreduce.am.job.node-blacklisting.ignore-threshold-node-percent 设置最多被加入黑名单的比例,默认值是33,当超过33%的机器被加入黑名单,则黑名单将会失效。
加入黑名单后,会让RM回收这台机器的container,申请其他机器的container
参数:
mapreduce.job.maxtaskfailures.per.tracker 失败多少次后,加入黑名单,默认是3 yarn.app.mapreduce.am.job.node-blacklisting.ignore-threshold-node-percent 加入黑名单的比例超过这个值时,关闭黑名单,默认是33 yarn.app.mapreduce.am.job.node-blacklisting.enable 是否使用黑名单,默认true
最终处理
在AM失败重启前,先sleep两分钟,等待磁盘健康检查完成。TaskAttempt有黑名单的方式,由于本地磁盘损坏造成的失败可能会比较少触发。
原文地址:hadoop本地目录相关代码分析, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1381
1381
 52
52

 What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do with blue screen code 0x0000001? The blue screen error is a warning mechanism when there is a problem with the computer system or hardware. Code 0x0000001 usually indicates a hardware or driver failure. When users suddenly encounter a blue screen error while using their computer, they may feel panicked and at a loss. Fortunately, most blue screen errors can be troubleshooted and dealt with with a few simple steps. This article will introduce readers to some methods to solve the blue screen error code 0x0000001. First, when encountering a blue screen error, we can try to restart
 GE universal remote codes program on any device
Mar 02, 2024 pm 01:58 PM
GE universal remote codes program on any device
Mar 02, 2024 pm 01:58 PM
If you need to program any device remotely, this article will help you. We will share the top GE universal remote codes for programming any device. What is a GE remote control? GEUniversalRemote is a remote control that can be used to control multiple devices such as smart TVs, LG, Vizio, Sony, Blu-ray, DVD, DVR, Roku, AppleTV, streaming media players and more. GEUniversal remote controls come in various models with different features and functions. GEUniversalRemote can control up to four devices. Top Universal Remote Codes to Program on Any Device GE remotes come with a set of codes that allow them to work with different devices. you may
 How to add local music to soda music
Feb 23, 2024 pm 07:13 PM
How to add local music to soda music
Feb 23, 2024 pm 07:13 PM
How to add local music to Soda Music? You can add your favorite local music to Soda Music APP, but most friends don’t know how to add local music. Next is the graphic tutorial on how to add local music to Soda Music brought by the editor. , interested users come and take a look! Tutorial on using soda music. How to add local music to soda music. 1. First open the soda music APP and click on the [Music] function area at the bottom of the main page; 2. Then enter the play page and click the [three dots] icon in the lower right corner; 3. Finally Expand the function bar below and select the [Download] button to add it to local music.
 How to use Copilot to generate code
Mar 23, 2024 am 10:41 AM
How to use Copilot to generate code
Mar 23, 2024 am 10:41 AM
As a programmer, I get excited about tools that simplify the coding experience. With the help of artificial intelligence tools, we can generate demo code and make necessary modifications as per the requirement. The newly introduced Copilot tool in Visual Studio Code allows us to create AI-generated code with natural language chat interactions. By explaining functionality, we can better understand the meaning of existing code. How to use Copilot to generate code? To get started, we first need to get the latest PowerPlatformTools extension. To achieve this, you need to go to the extension page, search for "PowerPlatformTool" and click the Install button
 Create and run Linux ".a" files
Mar 20, 2024 pm 04:46 PM
Create and run Linux ".a" files
Mar 20, 2024 pm 04:46 PM
Working with files in the Linux operating system requires the use of various commands and techniques that enable developers to efficiently create and execute files, code, programs, scripts, and other things. In the Linux environment, files with the extension ".a" have great importance as static libraries. These libraries play an important role in software development, allowing developers to efficiently manage and share common functionality across multiple programs. For effective software development in a Linux environment, it is crucial to understand how to create and run ".a" files. This article will introduce how to comprehensively install and configure the Linux ".a" file. Let's explore the definition, purpose, structure, and methods of creating and executing the Linux ".a" file. What is L
 How to automatically generate a directory. How to set the format of the automatically generated directory.
Feb 22, 2024 pm 03:30 PM
How to automatically generate a directory. How to set the format of the automatically generated directory.
Feb 22, 2024 pm 03:30 PM
Select the style of the catalog in Word, and it will be automatically generated after the operation is completed. Analysis 1. Go to Word on your computer and click to import. 2After entering, click on the file directory. 3 Then select the style of the directory. 4. After the operation is completed, you can see that the file directory is automatically generated. Supplement: The table of contents of the summary/notes article is automatically generated, including first-level headings, second-level headings and third-level headings, usually no more than third-level headings.
 How to read the catalog when reading on WeChat How to view the catalog
Mar 30, 2024 pm 05:56 PM
How to read the catalog when reading on WeChat How to view the catalog
Mar 30, 2024 pm 05:56 PM
The mobile version of WeChat Reading App is a very good reading software. This software provides a lot of books. You can read them anytime, anywhere with just one click to search and read them online. All of them are officially authorized and different types of books are neatly arranged. Sort and enjoy a comfortable and relaxing reading atmosphere. Switch the reading modes of different scenarios, update the latest book chapters continuously every day, support online login from multiple devices, and batch download to the bookshelf. You can read it with or without the Internet, so that everyone can discover more knowledge from it. Now the editor details it online Promote the method of viewing the catalog for WeChat reading partners. 1. Open the book you want to view the catalog and click in the middle of the book. 2. Click the three lines icon in the lower left corner. 3. In the pop-up window, view the book catalog
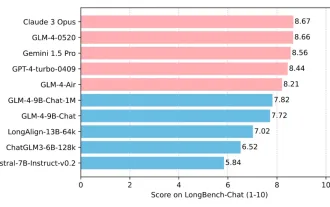 Tsinghua University and Zhipu AI open source GLM-4: launching a new revolution in natural language processing
Jun 12, 2024 pm 08:38 PM
Tsinghua University and Zhipu AI open source GLM-4: launching a new revolution in natural language processing
Jun 12, 2024 pm 08:38 PM
Since the launch of ChatGLM-6B on March 14, 2023, the GLM series models have received widespread attention and recognition. Especially after ChatGLM3-6B was open sourced, developers are full of expectations for the fourth-generation model launched by Zhipu AI. This expectation has finally been fully satisfied with the release of GLM-4-9B. The birth of GLM-4-9B In order to give small models (10B and below) more powerful capabilities, the GLM technical team launched this new fourth-generation GLM series open source model: GLM-4-9B after nearly half a year of exploration. This model greatly compresses the model size while ensuring accuracy, and has faster inference speed and higher efficiency. The GLM technical team’s exploration has not
