

Sql效能优化总结与sql语句优化篇

Sql效能优化总结与sql语句优化篇总结了关于优化查询速度的各种方法,有需要同学可参考一下。
今晚继续进行Sql效能问题的分享,今天主要是一些具体的sql优化方法和思路分享,若看过后你也有其他想法,欢迎一起探讨,好了,进入今天的主题。
针对性地对一些耗资源严重的具体应用进行优化
出现效能问题时,首先要做的是什么?这个问题我问过不少同事,有人说凭经验对出问题的sql进行优化,如我们一般说的要合理使用索引,尽量不要使用前面带*号的Like语句,不要再比较操作符前边进行计算或使用函数等等,这些道路都是对的,但经验有时候不一定能解决问题。问题出现时,首先要做的是确定问题点是什么,只有正确的找到问题后才能有针对性的解决问题。下面简单介绍我们一般从哪些角度入手,来确定问题所在。
1.首先从业务上理解该处功能,理解用户的真正意图,用户真正关注的是什么,想要的是什么数据,是否有变通简洁的方法达到用户要求。而非使用复杂sql查询。其实有些时候进行变通的修改,同样能达到目的,但是采用的sql语句已经极大地简化了。这是解决效能问题的优先要考虑的。
2.对固定的sql进行优化时,一定要关注查询相关的数据量,关注数据量的大小,有些时候用户进行一个查询,若没有处理好查询条件的话,返回的记录集合太大,这对用户来说,其实意义不大,关键是这样必然会导致较多的磁盘IO,效能问题是必然的。除非是用户真的需要这么多数据,但事实证明,多数都不是的,所以着眼点是怎样限制返回的记录集的大小或查询中使用的临时中间数据集合的大小。这样才能使你的优化达到效果,起到作用。
下面简单介绍几种常用的检查问题sql的方法。
当然其中是有些技巧的,如:
- 使用 set statistics io on 检查实际的磁盘IO信息,物理读、逻辑读等信息,这个是一个简单有效的参考数据,在笔者以往的经验中,也是主要的参考数据。
在查询分析器中贴出问题sql,使用set statistics io 为on,也可以在空白处点击右键,选择,

选择

勾选Set Statistics Io 。
运行查询,除了得到结果集合以外,还可以得到本次查询相关的IO信息,如下图:

我们一般关注逻辑读的次数,当多个表联合查询时,这里会现时每一个表的IO信息,当某个表的逻辑读的次数很大时,你就要重点关注和分析这个表了,是不是查询时涉及到这个表中的记录条数过多,是不是没有合理使用到Index,是不是可以增加其它的过滤条件来减少相关的记录集合等等。下面是简单说明:
输出项 含义
Table 表的名称。
Scan 执行的索引或表扫描数。
logical reads 从数据缓存读取的页数。
physical reads 从磁盘读取的页数。
read-ahead reads 为进行查询而放入缓存的页数。
lob logical reads 从数据缓存读取的 text、ntext、image 或大值类型 (varchar(max)、nvarchar(max)、varbinary(max)) 页的数目。
lob physical reads 从磁盘读取的 text、ntext、image 或大值类型页的数目。
lob read-ahead reads 为进行查询而放入缓存的 text、ntext、image 或大值类型页的数目。
磁盘IO相关信息先介绍到这里,另外一个参考数据是使用 set statistics time on 参考显示分析、编译和执行语句所需的毫秒数。具体的使用方法同set statistics io on 基本相同,只不过显示的是本次查询所使用的分析编译、执行等的时间信息。聪明的你一定一看就明白了。在此不再赘述。

- 使用 set statistics profile on 参考显示当前语句执行的配置文件信息,执行步骤等信息,使用方法同上。
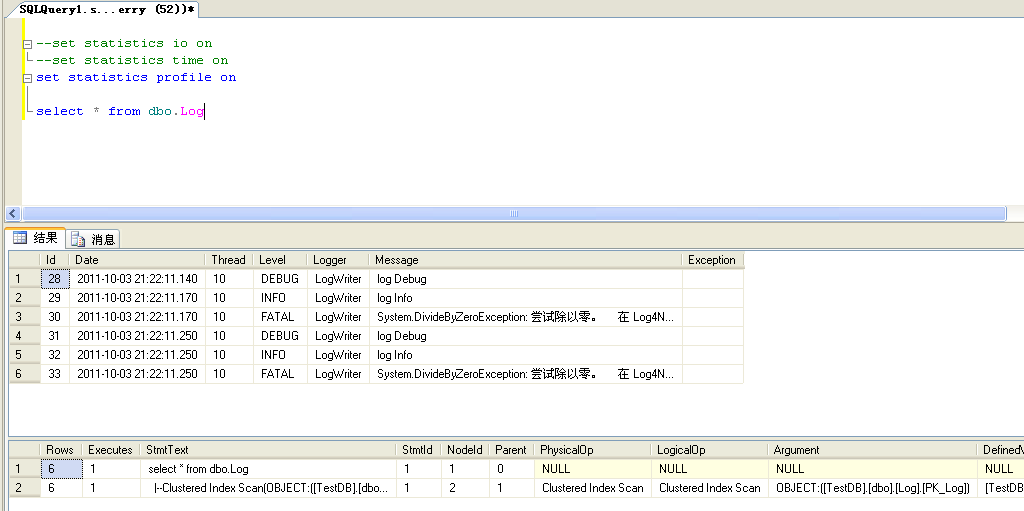
执行查询后,除了显示所执行的结果集合外,还另外显示本次sql语句执行的相关配置信息,采用记录树的形式显示,对应执行计划中的各个步骤,比如某个步骤使用的索引类型,评估行数,IO信息,时间信息等。这些信息都可以用来参考,以确定该段sql语句的问题在哪里。
参考当前语句的估计的执行计划或实际的执行计划,分析当前语句执行时SQL Server 查询优化器所选择的数据检索方法。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
The message "Your organization has asked you to change your PIN" will appear on the login screen. This happens when the PIN expiration limit is reached on a computer using organization-based account settings, where they have control over personal devices. However, if you set up Windows using a personal account, the error message should ideally not appear. Although this is not always the case. Most users who encounter errors report using their personal accounts. Why does my organization ask me to change my PIN on Windows 11? It's possible that your account is associated with an organization, and your primary approach should be to verify this. Contacting your domain administrator can help! Additionally, misconfigured local policy settings or incorrect registry keys can cause errors. Right now
 How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
Windows 11 brings fresh and elegant design to the forefront; the modern interface allows you to personalize and change the finest details, such as window borders. In this guide, we'll discuss step-by-step instructions to help you create an environment that reflects your style in the Windows operating system. How to change window border settings? Press + to open the Settings app. WindowsI go to Personalization and click Color Settings. Color Change Window Borders Settings Window 11" Width="643" Height="500" > Find the Show accent color on title bar and window borders option, and toggle the switch next to it. To display accent colors on the Start menu and taskbar To display the theme color on the Start menu and taskbar, turn on Show theme on the Start menu and taskbar
 How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
By default, the title bar color on Windows 11 depends on the dark/light theme you choose. However, you can change it to any color you want. In this guide, we'll discuss step-by-step instructions for three ways to change it and personalize your desktop experience to make it visually appealing. Is it possible to change the title bar color of active and inactive windows? Yes, you can change the title bar color of active windows using the Settings app, or you can change the title bar color of inactive windows using Registry Editor. To learn these steps, go to the next section. How to change title bar color in Windows 11? 1. Using the Settings app press + to open the settings window. WindowsI go to "Personalization" and then
 How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
Taskbar thumbnails can be fun, but they can also be distracting or annoying. Considering how often you hover over this area, you may have inadvertently closed important windows a few times. Another disadvantage is that it uses more system resources, so if you've been looking for a way to be more resource efficient, we'll show you how to disable it. However, if your hardware specs can handle it and you like the preview, you can enable it. How to enable taskbar thumbnail preview in Windows 11? 1. Using the Settings app tap the key and click Settings. Windows click System and select About. Click Advanced system settings. Navigate to the Advanced tab and select Settings under Performance. Select "Visual Effects"
 What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
HQL and SQL are compared in the Hibernate framework: HQL (1. Object-oriented syntax, 2. Database-independent queries, 3. Type safety), while SQL directly operates the database (1. Database-independent standards, 2. Complex executable queries and data manipulation).
 Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
We all have different preferences when it comes to display scaling on Windows 11. Some people like big icons, some like small icons. However, we all agree that having the right scaling is important. Poor font scaling or over-scaling of images can be a real productivity killer when working, so you need to know how to customize it to get the most out of your system's capabilities. Advantages of Custom Zoom: This is a useful feature for people who have difficulty reading text on the screen. It helps you see more on the screen at one time. You can create custom extension profiles that apply only to certain monitors and applications. Can help improve the performance of low-end hardware. It gives you more control over what's on your screen. How to use Windows 11
 10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
Screen brightness is an integral part of using modern computing devices, especially when you look at the screen for long periods of time. It helps you reduce eye strain, improve legibility, and view content easily and efficiently. However, depending on your settings, it can sometimes be difficult to manage brightness, especially on Windows 11 with the new UI changes. If you're having trouble adjusting brightness, here are all the ways to manage brightness on Windows 11. How to Change Brightness on Windows 11 [10 Ways Explained] Single monitor users can use the following methods to adjust brightness on Windows 11. This includes desktop systems using a single monitor as well as laptops. let's start. Method 1: Use the Action Center The Action Center is accessible
 Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
"Usage of Division Operation in OracleSQL" In OracleSQL, division operation is one of the common mathematical operations. During data query and processing, division operations can help us calculate the ratio between fields or derive the logical relationship between specific values. This article will introduce the usage of division operation in OracleSQL and provide specific code examples. 1. Two ways of division operations in OracleSQL In OracleSQL, division operations can be performed in two different ways.
