

SQL Server 总结复习(二)

SQL Server 总结复习(二) 有要学习的朋友可参考一下。
1. 排名函数与PARTITION BY
| 代码如下 | 复制代码 |
|
--所有数据 ------------------------------------------- ---------------------------------------------------------------------------- ----------------------------------------------------------------------------
|
|
2. TOP 新用法
| 代码如下 | 复制代码 |
|
SELECT TOP (@num) * FROM Student ORDER BY Id --必须用括号括起来 SELECT TOP (@num) percent * FROM Student ORDER BY Id --只接受float并且1-100之间的数,如果传入其他则会报错
|
|
3. group by all 字段 / group by 字段
前者有点像left join ,right join的感觉,两者的主要区别体现在有where条件被过滤的聚合函数,会重新抓取出来放入查询的数据表中,只是聚合函数会根据返回值的类型用默认值0或者NULL来代替聚合函数的返回值。
当然从效率上来说,后者优于前者,就像inner join 优于left join一样
4. count(*)/count(0) 与 count(字段)
如果查询出来的字段中没有NULL值,那么俩种查询条件无任何区别,如果有NULL,后者统计出来的记录则是 总记录数 - NULL记录数
从性能上来说,前者高于后者,因为后者会逐行扫描字段中是否有NULL值,有NULL则不加以统计,减少了逻辑读的开销,从而性能达到提升
5. top n With ties 的用法
详见 http://www.cnblogs.com/skynet/archive/2010/03/29/1700055.html
举个例子
select top 1 with ties * from student order by score desc
等价于
select * from student where score=(select top 1 score from student order by score desc)
6. Apply运算符
View Code
--准备数据
CREATE TABLE [dbo].[Student](
[Id] [int] NULL,
[Name] [varchar](50) NULL
)
go
INSERT INTO dbo.Student VALUES (1, '张三')
INSERT INTO dbo.Student VALUES (2, '李斯')
INSERT INTO dbo.Student VALUES (3, '王五')
INSERT INTO dbo.Student VALUES (4, '神人')
go
CREATE TABLE [dbo].[scoretb](
[stuId] [int] NULL,
[scorename] [varchar](50) NULL,
[score] INT NULL
)
go
INSERT INTO [scoretb] VALUES (1,'语文',22)
INSERT INTO [scoretb] VALUES (1,'数学',32)
INSERT INTO [scoretb] VALUES (1,'外语',42)
INSERT INTO [scoretb] VALUES (2,'语文',52)
INSERT INTO [scoretb] VALUES (2,'数学',62)
INSERT INTO [scoretb] VALUES (2,'外语',72)
INSERT INTO [scoretb] VALUES (3,'语文',82)
INSERT INTO [scoretb] VALUES (3,'数学',92)
INSERT INTO [scoretb] VALUES (3,'外语',72)
--创建表值函数
CREATE FUNCTION [dbo].[fGetScore](@stuid int)
RETURNS @score TABLE
(
[stuId] [int] NULL,
[scorename] [varchar](50) NULL,
[score] INT NULL
)
as
BEGIN
INSERT INTO @score
SELECT stuid,scorename,score FROM dbo.scoretb WHERE stuId = @stuid
RETURN;
END
GO
--开始使用
SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
CROSS APPLY [dbo].[fGetScore](A.Id) B --相当于inner join效果
SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
OUTER APPLY [dbo].[fGetScore](A.Id) B --相当于left join效果
--而不能这样使用
--SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
-- INNER JOIN [dbo].[fGetScore](A.Id) B ON A.Id = B.stuid
-- SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
-- INNER JOIN (SELECT * FROM [dbo].[fGetScore](A.Id)) B ON A.Id = B.stuid
7. INTERSECT和EXCEPT运算符
EXCEPT 只包含excpet关键字左边而且右边的结果集中不存在的那些行 INTERSECT 只包含两个结果集中都存在的那些行
往往EXISTS关键字可以代替上面的关键字,并且从性能中可以看到比他们更好,但EXCEPT/INTERSECT更便于阅读和直观。还是建议从性能更优入手。
8. 索引提高查询效率的原理
索引与EXISTS运算符在处理方式上很像,它们都可以在找到匹配值后立即退出查询运行,从而提高了查询性能
9. 表变量与临时表
主要区别: 1表变量不写日志,没有统计信息,频繁更改不会造成存储过程重新编译,不能建索引和统计信息,但是可以建立主键,变通实现索引查找,表变量不只是在内存中操作,数据量大的情况也会写tempdb,即物理磁盘的IO操作。 2.事务回滚对表变量无效(原因没有统计信息)
一般来说,数据量大,临时结果集需要和其他表二次关联用临时表 数据量小,单独操作临时结果集用表变量
10. 脚本和批处理
Go不是一条T-SQL命令,他只能被编译工具Management Studio, SQLCMD识别,如果用第三方工具,不一定支持GO命令。例如ADO.NET,ADO。
11. SQLCMD的运用
SQLCMD -Usa -Psa -Q "SELECT * FROM TESTDB.dbo.mytable"
SQLCMD -Usa -Psa -i testsql.sql 运行文件里的SQL语句
12. EXEC 使用说明
在执行过EXEC之后,可以使用类似@@ROWCOUNT这样的变量查看影响行数;不能在EXEC的参数中,针对EXEC字符串运行函数,例如cast(XX AS VARCHAR),对于EXEC的参数,只能用字符串相加,或者是整体的字符串。
13. WAITFOR 的含义
WAITFOR TIME 定时执行; WAITFOR DELAY 延迟执行
14. 存储过程 总结
1)用TRY/CATCH 替代 @@ERROR这种更科学,其一@@ERROR没有TRA/CATCH直观,其二遇到错误级别在11-19的错误,错误会使运行直接中断,导致@@ERROR判断错误与否无效。
2)使用RAISERROR 抛错
WITH LOG,当严重级别大于等于19时,需要使用这个选项
WITH SETERROR,使其重写@@ERROR值,方便外部调用
WITH NOWAIT 立刻将错误通知给客户端
15. 游标的复习
游标主要部分包括:1)声明 2)打开 3)使用或导航 4)关闭 5)释放
嵌套使用游标示例
DECLARE BillMsgCursor CURSOR FOR
SELECT TypeNo,TabDetailName FROM dbo.BillType
OPEN BillMsgCursor
DECLARE @TypeNo CHAR(5)
DECLARE @DetailName VARCHAR(50)
FETCH NEXT FROM BillMsgCursor INTO @TypeNo,@DetailName
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @DataFieldName VARCHAR(50)
DECLARE ColumnName CURSOR FOR
SELECT name FROM syscolumns WHERE id = OBJECT_ID(@DetailName)
OPEN ColumnName
FETCH NEXT FROM ColumnName INTO @DataFieldName
PRINT '单据编号:' + @TypeNo
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'ListDetailDataFiled.Add('''+@DataFieldName+''');'
FETCH NEXT FROM ColumnName INTO @DataFieldName
END
CLOSE ColumnName
DEALLOCATE ColumnName
FETCH NEXT FROM BillMsgCursor INTO @TypeNo,@DetailName
END
CLOSE BillMsgCursor
DEALLOCATE BillMsgCursor
@@fetch_status值的意义:0 FETCH 语句成功;-1 FETCH 语句失败或此行不在结果集中;-2 被提取的行不存在
FETCH [NEXT/PRIOR/FIRST/LAST] FROM ... INTO 针对游标为SCROLL类型的
16. 游标的分类
1)静态游标(static):相当于临时表,会保存在tempdb里的私有表中,犹如快照表复制一份
a.一旦创建了游标,它就与实际记录相分离并不再维持任何锁
b.游标就是独立的,不再以任何方式与原始数据相关联
2)键集驱动的游标(keyset):需要在一定程度上感知对数据的修改,但不必了解最新发生的所有插入
a.表必须具有唯一索引
b.只有键集在tempdb中,而非整个数据集,对整个服务器性能产生有利的影响
c.能感知到对己是键集一部分的行所做的修改(改删),不能感知新增
3)动态游标(DYNAMIC)
a.完全动态,非常敏感,对底层数据做的所有事情都会影响,性能当然也是最差的
b.它们会带来额外的并发性问题
c.每发出一次FETCH,都要重建游标
d.可允许运行没有唯一索引的表中,但弊端会造成SQLSERVER无法追踪它在游标的位置造成死循环,应避免这样使用
4)快进游标(FAST_FORWARD)
在许多情况下,FAST_FORWARD游标会隐式转换为其他游标类型

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
The message "Your organization has asked you to change your PIN" will appear on the login screen. This happens when the PIN expiration limit is reached on a computer using organization-based account settings, where they have control over personal devices. However, if you set up Windows using a personal account, the error message should ideally not appear. Although this is not always the case. Most users who encounter errors report using their personal accounts. Why does my organization ask me to change my PIN on Windows 11? It's possible that your account is associated with an organization, and your primary approach should be to verify this. Contacting your domain administrator can help! Additionally, misconfigured local policy settings or incorrect registry keys can cause errors. Right now
 How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
Windows 11 brings fresh and elegant design to the forefront; the modern interface allows you to personalize and change the finest details, such as window borders. In this guide, we'll discuss step-by-step instructions to help you create an environment that reflects your style in the Windows operating system. How to change window border settings? Press + to open the Settings app. WindowsI go to Personalization and click Color Settings. Color Change Window Borders Settings Window 11" Width="643" Height="500" > Find the Show accent color on title bar and window borders option, and toggle the switch next to it. To display accent colors on the Start menu and taskbar To display the theme color on the Start menu and taskbar, turn on Show theme on the Start menu and taskbar
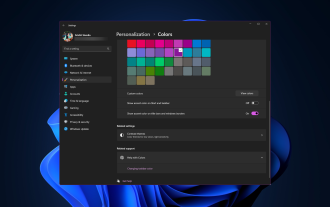 How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
By default, the title bar color on Windows 11 depends on the dark/light theme you choose. However, you can change it to any color you want. In this guide, we'll discuss step-by-step instructions for three ways to change it and personalize your desktop experience to make it visually appealing. Is it possible to change the title bar color of active and inactive windows? Yes, you can change the title bar color of active windows using the Settings app, or you can change the title bar color of inactive windows using Registry Editor. To learn these steps, go to the next section. How to change title bar color in Windows 11? 1. Using the Settings app press + to open the settings window. WindowsI go to "Personalization" and then
 OOBELANGUAGE Error Problems in Windows 11/10 Repair
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE Error Problems in Windows 11/10 Repair
Jul 16, 2023 pm 03:29 PM
Do you see "A problem occurred" along with the "OOBELANGUAGE" statement on the Windows Installer page? The installation of Windows sometimes stops due to such errors. OOBE means out-of-the-box experience. As the error message indicates, this is an issue related to OOBE language selection. There is nothing to worry about, you can solve this problem with nifty registry editing from the OOBE screen itself. Quick Fix – 1. Click the “Retry” button at the bottom of the OOBE app. This will continue the process without further hiccups. 2. Use the power button to force shut down the system. After the system restarts, OOBE should continue. 3. Disconnect the system from the Internet. Complete all aspects of OOBE in offline mode
 How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
Taskbar thumbnails can be fun, but they can also be distracting or annoying. Considering how often you hover over this area, you may have inadvertently closed important windows a few times. Another disadvantage is that it uses more system resources, so if you've been looking for a way to be more resource efficient, we'll show you how to disable it. However, if your hardware specs can handle it and you like the preview, you can enable it. How to enable taskbar thumbnail preview in Windows 11? 1. Using the Settings app tap the key and click Settings. Windows click System and select About. Click Advanced system settings. Navigate to the Advanced tab and select Settings under Performance. Select "Visual Effects"
 Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
We all have different preferences when it comes to display scaling on Windows 11. Some people like big icons, some like small icons. However, we all agree that having the right scaling is important. Poor font scaling or over-scaling of images can be a real productivity killer when working, so you need to know how to customize it to get the most out of your system's capabilities. Advantages of Custom Zoom: This is a useful feature for people who have difficulty reading text on the screen. It helps you see more on the screen at one time. You can create custom extension profiles that apply only to certain monitors and applications. Can help improve the performance of low-end hardware. It gives you more control over what's on your screen. How to use Windows 11
 10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
Screen brightness is an integral part of using modern computing devices, especially when you look at the screen for long periods of time. It helps you reduce eye strain, improve legibility, and view content easily and efficiently. However, depending on your settings, it can sometimes be difficult to manage brightness, especially on Windows 11 with the new UI changes. If you're having trouble adjusting brightness, here are all the ways to manage brightness on Windows 11. How to Change Brightness on Windows 11 [10 Ways Explained] Single monitor users can use the following methods to adjust brightness on Windows 11. This includes desktop systems using a single monitor as well as laptops. let's start. Method 1: Use the Action Center The Action Center is accessible
 How to turn off private browsing authentication for iPhone in Safari?
Nov 29, 2023 pm 11:21 PM
How to turn off private browsing authentication for iPhone in Safari?
Nov 29, 2023 pm 11:21 PM
In iOS 17, Apple introduced several new privacy and security features to its mobile operating system, one of which is the ability to require two-step authentication for private browsing tabs in Safari. Here's how it works and how to turn it off. On an iPhone or iPad running iOS 17 or iPadOS 17, Apple's browser now requires Face ID/Touch ID authentication or a passcode if you have any Private Browsing tab open in Safari and then exit the session or app to access them again. In other words, if someone gets their hands on your iPhone or iPad while it's unlocked, they still won't be able to view your privacy without knowing your passcode
