

sql distinct使用方法

本文章来给各位朋友介绍distinct用法及distinct在使用过程中一些常用见问题总结,有需要了解distinct用法的朋友可参考参考。
SQL SELECT DISTINCT 语句
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。
关键词 DISTINCT 用于返回唯一不同的值。
语法:
SELECT DISTINCT 列名称 FROM 表名称
如需从 Company" 列中仅选取唯一不同的值,我们需要使用 SELECT DISTINCT 语句:
| 代码如下 | 复制代码 |
|
SELECT DISTINCT Company FROM Orders |
|
distinct 关键字失效的办法
用distinct关键字只能过滤查询字段中所有记录相同的(记录集相同),而如果要指定一个字段却没有效果,另外
distinct关键字会排序,效率很低。
distinct name from t1 能消除重复记录,但只能取一个字段,现在要同时取id,name这2个字段的值。
select distinct id,name from t1 可以取多个字段,但只能消除这2个字段值全部相同的记录
所以用distinct达不到想要的效果,用 可以解决这个问题。
例如要显示的字段为A、B、C三个,而A字段的内容不能重复可以用下面的语句:
| 代码如下 | 复制代码 |
| select A, min(B),min(C),count(*) from [table] where [条件] group by A having [条件] order by A desc |
|
为了显示标题头好看点可以把select A, min(B),min(C),count(*) 换称select A as A, min(B) as B,min(C) as
C,count(*) as 重复次数
显示出来的字段和排序字段都要包括在group by 中
但显示出来的字段包有min,max,count,avg,sum等聚合函数时可以不在group by 中
如上句的min(B),min(C),count(*)
一般条件写在where 后面
有聚合函数的条件写在having 后面
如果在上句中having加 count(*)>1 就可以查出记录A的重复次数大于1的记录
如果在上句中having加 count(*)>2 就可以查出记录A的重复次数大于2的记录
如果在上句中having加 count(*)>=1 就可以查出所有的记录,但重复的只显示一条,并且后面有显示重复的次数-
---这就是所需要的结果,而且语句可以通过hibernate
下面语句可以查询出那些数据是重复的:
select 字段1,字段2,count(*) from 表名 group by 字段1,字段2 having count(*) > 1
将上面的>号改为=号就可以查询出没有重复的数据了。
例如
| 代码如下 | 复制代码 |
|
select count(*) from (select gcmc,gkrq,count(*) from gczbxx_zhao t group by gcmc,gkrq having count(*)>=1 order by GKRQ) 推荐使用: select * from gczbxx_zhao where viewid in ( select max(viewid) from gczbxx_zhao group by gcmc ) order by gkrq desc |
|

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to use mysql's DISTINCT
Jun 03, 2023 pm 05:56 PM
How to use mysql's DISTINCT
Jun 03, 2023 pm 05:56 PM
The DISTINCT keyword of mysql has many unexpected uses. 1. It can be used when counting non-duplicate records, such as SELECTCOUNT(DISTINCTid) FROMtablename; it is to count how many records with different IDs in the talbebname table. 2. When you need to return records For specific values of different ids, you can use, for example, SELECTDISTINCTidFROMtablename; to return the specific values of different ids in the talbebname table. 3. The above situation 2 will be ambiguous when you need to return results of more than 2 columns in the mysql table, such as SELECTDISTINCTid, type
 How to use distinct and group by in MySQL
May 26, 2023 am 10:34 AM
How to use distinct and group by in MySQL
May 26, 2023 am 10:34 AM
Let’s talk about the general conclusion first: when the semantics are the same and there is an index: both groupby and distinct can use the index, and the efficiency is the same. In the case of the same semantics and no index: distinct is more efficient than groupby. The reason is that both distinct and groupby will perform grouping operations, but groupby may perform sorting and trigger filesort, resulting in inefficient SQL execution. Based on this conclusion, you may ask: Why are groupby and distinct efficient when they have the same semantics and indexes? Under what circumstances does groupby perform sorting operations? Find answers to these two questions. Next, let’s take a look at dist
 Using the distinct keyword in parsing SQL
Feb 18, 2024 pm 09:21 PM
Using the distinct keyword in parsing SQL
Feb 18, 2024 pm 09:21 PM
Detailed explanation of distinct usage in SQL In SQL databases, we often encounter situations where we need to remove duplicate data. At this time, we can use the distinct keyword, which can help us remove duplicate data and make the query results clearer and more accurate. The basic usage of distinct is very simple, just use the distinct keyword in the select statement. For example, the following is a normal select statement: SELECTcolumn_name
 What is the usage of distinct in oracle?
Jul 11, 2023 am 09:35 AM
What is the usage of distinct in oracle?
Jul 11, 2023 am 09:35 AM
Oracle's distinct usage can filter duplicate rows in the result set to ensure that the value of the specified column or columns returned in the "SELECT" clause is unique. The syntax is "SELECT DISTINCT column 1, column 2, column 3... from table name". "distinct" will sort the returned result set and can be used in conjunction with "order by" to improve efficiency.
 How to optimize DISTINCT in MySQL to improve performance
May 11, 2023 am 08:12 AM
How to optimize DISTINCT in MySQL to improve performance
May 11, 2023 am 08:12 AM
MySQL is one of the most widely used relational databases currently. In large data storage and query, optimizing database performance is crucial. Among them, DISTINCT is a commonly used deduplication query operator. This article will introduce how to improve database query performance through MySQL DISTINCT optimization. 1. Principles and Disadvantages of DISTINCT The DISTINCT keyword is used to remove duplicate rows from query results. In the case of large amounts of data, there may be multiple duplicate values in the query, resulting in redundant output data.
 distinct usage in SQL
Jan 26, 2024 pm 03:14 PM
distinct usage in SQL
Jan 26, 2024 pm 03:14 PM
DISTINCT in SQL is a keyword used to query unique result sets. It can be used in SELECT statements, COUNT aggregate functions and other statements. The basic syntax is "SELECT DISTINCT column1, column2", where the DISTINCT keyword is placed in the SELECT key After the word, followed by the column name or expression to be queried, separated by commas.
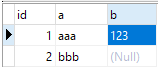 How to solve the problem of count distinct multiple columns in mysql
Jun 03, 2023 am 10:49 AM
How to solve the problem of count distinct multiple columns in mysql
Jun 03, 2023 am 10:49 AM
The reproduced test database is as follows: CREATETABLE`test_distinct`(`id`int(11)NOTNULLAUTO_INCREMENT,`a`varchar(50)CHARACTERSETutf8DEFAULTNULL,`b`varchar(50)CHARACTERSETutf8DEFAULTNULL,PRIMARYKEY(`id`))ENGINE= InnoDBAUTO_INCREMENT=1DEFAULTCHARSET=latin1;The test data in the table is as follows. Now we need to count the deduplicated columns of these three columns.
 How to use distinct in SQL
Jan 25, 2024 am 11:52 AM
How to use distinct in SQL
Jan 25, 2024 am 11:52 AM
The DISTINCT keyword in SQL is used to remove duplicate rows from query results. It can be applied to one or more columns in the SELECT statement to return a unique value combination. The usage method is "SELECT DISTINCT column1, column2, ..." The DISTINCT keyword acts on all specified columns. If multiple columns are combined to produce different results, then these rows will also be considered different and will not be deduplicated.
