

Using PhantomJS to make web page screenshots is economical and practical, but its API is small, making it more difficult to perform other functions. For example, its own Web Server Mongoose can only support up to 10 requests at the same time. It is not practical to expect it to become an independent service. So another language is needed to support the service, and NodeJS is used to complete it.
Install PhantomJS
First, go to PhantomJS official website to download the version corresponding to the platform, or download the source code and compile it yourself. Then configure PhantomJS into the environment variable and enter
$ phantomjs
If there is a response, then you can proceed to the next step.
Use PhantomJS to take simple screenshots
Here we set the window size to 1024 * 800:
page.viewportSize = { width: 1024, height: 800 };Intercept an image of size 1024 * 800 starting from (0, 0):
Disable Javascript, allow image loading, and change userAgent to "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0":
Then use page.open to open the page, and finally output the screenshot to ./snapshot/test.png:
NodeJS and PhantomJS communication
Let’s first take a look at what communication PhantomJS can do.
Command line parametersFor example:
phantomjs snapshot.js http://www.baidu.com
The command line parameters can only be passed when PhantomJS is opened, and there is nothing you can do during the running process.
Standard output can output data from PhantomJS to NodeJS, but it cannot transfer data from NodeJS to PhantomJS.
However, in the test, standard output is the fastest transmission method among these methods, and should be considered when transmitting large amounts of data.
PhantomJS makes an HTTP request to the NodeJS service, and NodeJS returns the corresponding data.
This way is simple, but the request can only be made by PhantomJS.
It is worth noting that PhantomJS 1.9.0 supports Websocket, but unfortunately it is hixie-76 Websocket, but after all, it still provides a solution for NodeJS to actively communicate with PhantomJS.
During the test, we found that it actually takes about 1 second for PhantomJS to connect to the local Websocket service. We will not consider this method for the time being.
phantomjs-node成功将PhantomJS作为NodeJS的一个模块来使用,但我们看看作者的原理解释:
I will answer that question with a question. How do you communicate with a process that doesn't support shared memory, sockets, FIFOs, or standard input?
Well, there's one thing PhantomJS does support, and that's opening webpages. In fact, it's really good at opening web pages. So we communicate with PhantomJS by spinning up an instance of ExpressJS, opening Phantom in a subprocess, and pointing it at a special webpage that turns socket.io messages into alert()calls. Those alert() calls are picked up by Phantom and there you go!
The communication itself happens via James Halliday's fantastic dnode library, which fortunately works well enough when combined with browserify to run straight out of PhantomJS's pidgin Javascript environment.
实际上phantomjs-node使用的也是HTTP或者Websocket来进行通讯,不过其依赖庞大,我们只想做一个简单的东西,暂时还是不考虑这个东东吧。
设计图
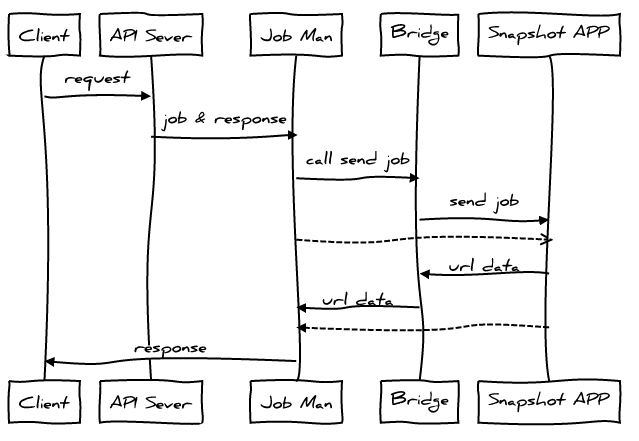
让我们开始吧
我们在第一版中选用HTTP进行实现。
首先利用cluster进行简单的进程守护(index.js):
if(!fs.existsSync('./snapshot')) {
fs.mkdirSync('./snapshot');
}
if (cluster.isMaster) {
cluster.fork();
cluster.on('exit', function (worker) {
console.log('Worker' worker.id ' died :(');
process.nextTick(function () {
cluster.fork();
});
})
} else {
require('./extract.js');
}
})();
然后利用connect做我们的对外API(extract.js):
var app = connect()
.use(connect.logger('dev'))
.use('/snapshot', connect.static(__dirname '/snapshot', { maxAge: pkg.maxAge }))
.use(connect.bodyParser())
.use('/bridge', bridge)
.use('/api', function (req, res, next) {
if (req.method !== "POST" || !req.body.campaignId) return next();
if (!req.body.urls || !req.body.urls.length) return jobMan.watch(req.body.campaignId, req, res, next);
var campaignId = req.body.campaignId
, imagesPath = './snapshot/' campaignId '/'
, urls = []
, url
, imagePath;
function _deal(id, url, imagePath) {
// just push into urls list
urls.push({
id: id,
url: url,
imagePath: imagePath
});
}
for (var i = req.body.urls.length; i--;) {
url = req.body.urls[i];
imagePath = imagesPath i '.png';
_deal(i, url, imagePath);
}
jobMan.register(campaignId, urls, req, res, next);
var snapshot = spawn('phantomjs', ['snapshot.js', campaignId]);
snapshot.stdout.on('data', function (data) {
console.log('stdout: ' data);
});
snapshot.stderr.on('data', function (data) {
console.log('stderr: ' data);
});
snapshot.on('close', function (code) {
console.log('snapshot exited with code ' code);
});
})
.use(connect.static(__dirname '/html', { maxAge: pkg.maxAge }))
.listen(pkg.port, function () { console.log('listen: ' 'http://localhost:' pkg.port); });
})();
这里我们引用了两个模块bridge和jobMan。
其中bridge是HTTP通讯桥梁,jobMan是工作管理器。我们通过campaignId来对应一个job,然后将job和response委托给jobMan管理。然后启动PhantomJS进行处理。
通讯桥梁负责接受或者返回job的相关信息,并交给jobMan(bridge.js):
return function (req, res, next) {
if (req.headers.secret !== pkg.secret) return next();
// Snapshot APP can post url information
if (req.method === "POST") {
var body = JSON.parse(JSON.stringify(req.body));
jobMan.fire(body);
res.end('');
// Snapshot APP can get the urls should extract
} else {
var urls = jobMan.getUrls(req.url.match(/campaignId=([^&]*)(s|&|$)/)[1]);
res.writeHead(200, {'Content-Type': 'application/json'});
res.statuCode = 200;
res.end(JSON.stringify({ urls: urls }));
}
};
})();
如果request method为POST,则我们认为PhantomJS正在给我们推送job的相关信息。而为GET时,则认为其要获取job的信息。
jobMan负责管理job,并发送目前得到的job信息通过response返回给client(jobMan.js):
function _send(campaignId){
var job = _jobs[campaignId];
if (!job) return;
if (job.waiting) {
job.waiting = false;
clearTimeout(job.timeout);
var finished = (job.urlsNum === job.finishNum)
, data = {
campaignId: campaignId,
urls: job.urls,
finished: finished
};
job.urls = [];
var res = job.res;
if (finished) {
_jobs[campaignId] = null;
delete _jobs[campaignId]
}
res.writeHead(200, {'Content-Type': 'application/json'});
res.statuCode = 200;
res.end(JSON.stringify(data));
}
}
function register(campaignId, urls, req, res, next) {
_jobs[campaignId] = {
urlsNum: urls.length,
finishNum: 0,
urls: [],
cacheUrls: urls,
res: null,
waiting: false,
timeout: null
};
watch(campaignId, req, res, next);
}
function watch(campaignId, req, res, next) {
_jobs[campaignId].res = res;
// 20s timeout
_jobs[campaignId].timeout = setTimeout(function () {
_send(campaignId);
}, 20000);
}
function fire(opts) {
var campaignId = opts.campaignId
, job = _jobs[campaignId]
, fetchObj = fetch(opts.html);
if (job) {
if ( opts.status && fetchObj.title) {
job.urls.push({
id: opts.id,
url: opts.url,
image: opts.image,
title: fetchObj.title,
description: fetchObj.description,
status: opts.status
});
} else {
job.urls.push({
id: opts.id,
url: opts.url,
status: opts.status
});
}
if (!job.waiting) {
job.waiting = true;
setTimeout(function () {
_send(campaignId);
}, 500);
}
job.finishNum ;
} else {
console.log('job can not found!');
}
}
function getUrls(campaignId) {
var job = _jobs[campaignId];
if (job) return job.cacheUrls;
}
return {
register: register,
watch: watch,
fire: fire,
getUrls: getUrls
};
})();
这里我们用到fetch对html进行抓取其title和description,fetch实现比较简单(fetch.js):
return function (html) {
if (!html) return { title: false, description: false };
var title = html.match(/
if (meta) {
for (var i = meta.length; i--;) {
if(meta[i].indexOf('name="description"') > -1 || meta[i].indexOf('name="Description"') > -1){
description = meta[i].match(/content="(.*?)"/)[1];
}
}
}
(title && title[1] !== '') ? (title = title[1]) : (title = 'No Title');
description || (description = 'No Description');
return {
title: title,
description: description
};
};
})();
最后是PhantomJS运行的源代码,其启动后通过HTTP向bridge获取job信息,然后每完成job的其中一个url就通过HTTP返回给bridge(snapshot.js):
function snapshot(id, url, imagePath) {
var page = webpage.create()
, send
, begin
, save
, end;
page.viewportSize = { width: 1024, height: 800 };
page.clipRect = { top: 0, left: 0, width: 1024, height: 800 };
page.settings = {
javascriptEnabled: false,
loadImages: true,
userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/1.9.0'
};
page.open(url, function (status) {
var data;
if (status === 'fail') {
data = [
'campaignId=',
campaignId,
'&url=',
encodeURIComponent(url),
'&id=',
id,
'&status=',
].join('');
postPage.open('http://localhost:' + pkg.port + '/bridge', 'POST', data, function () {});
} else {
page.render(imagePath);
var html = page.content;
// callback NodeJS
data = [
'campaignId=',
campaignId,
'&html=',
encodeURIComponent(html),
'&url=',
encodeURIComponent(url),
'&image=',
encodeURIComponent(imagePath),
'&id=',
id,
'&status=',
].join('');
postMan.post(data);
}
// release the memory
page.close();
});
}
var postMan = {
postPage: null,
posting: false,
datas: [],
len: 0,
currentNum: 0,
init: function (snapshot) {
var postPage = webpage.create();
postPage.customHeaders = {
'secret': pkg.secret
};
postPage.open('http://localhost:' + pkg.port + '/bridge?campaignId=' + campaignId, function () {
var urls = JSON.parse(postPage.plainText).urls
, url;
this.len = urls.length;
if (this.len) {
for (var i = this.len; i--;) {
url = urls[i];
snapshot(url.id, url.url, url.imagePath);
}
}
});
this.postPage = postPage;
},
post: function (data) {
this.datas.push(data);
if (!this.posting) {
this.posting = true;
this.fire();
}
},
fire: function () {
if (this.datas.length) {
var data = this.datas.shift()
, that = this;
this.postPage.open('http://localhost:' pkg.port '/bridge', 'POST', data, function () {
that.fire();
// kill child process
setTimeout(function () {
if ( this.currentNum === this.len) {
that.postPage.close();
phantom.exit();
}
}, 500);
});
} else {
this.posting = false;
}
}
};
postMan.init(snapshot);
 How to light up Douyin close friends moment
How to light up Douyin close friends moment
 microsoft project
microsoft project
 What is phased array radar
What is phased array radar
 How to use fusioncharts.js
How to use fusioncharts.js
 Yiou trading software download
Yiou trading software download
 The latest ranking of the top ten exchanges in the currency circle
The latest ranking of the top ten exchanges in the currency circle
 What to do if win8wifi connection is not available
What to do if win8wifi connection is not available
 How to recover files emptied from Recycle Bin
How to recover files emptied from Recycle Bin








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



