

Python网络爬虫实例讲解

聊一聊Python与网络爬虫。
1、爬虫的定义
爬虫:自动抓取互联网数据的程序。
2、爬虫的主要框架
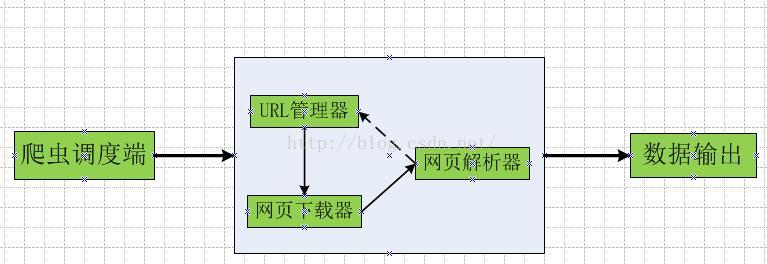
爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出。
3、爬虫的时序图
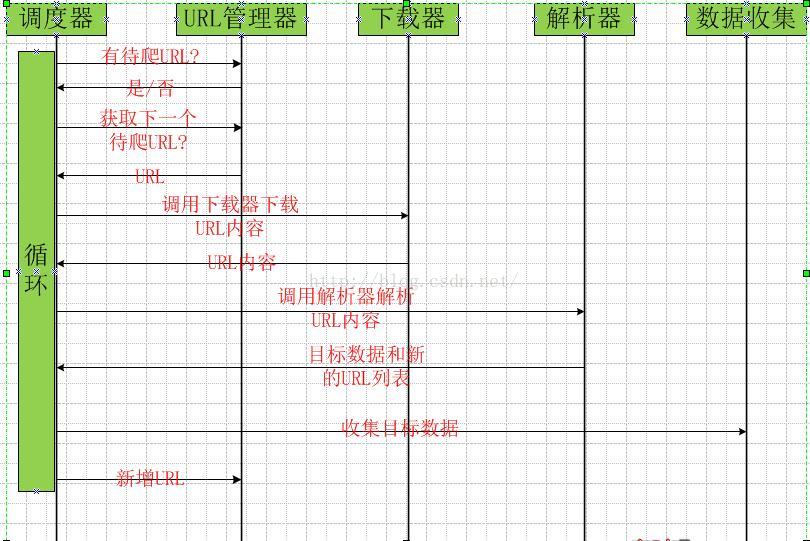
4、URL管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取。URL管理器的主要职能如下图所示:

URL管理器在实现方式上,Python中主要采用内存(set)、和关系数据库(MySQL)。对于小型程序,一般在内存中实现,Python内置的set()类型能够自动判断元素是否重复。对于大一点的程序,一般使用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用urllib库,这是python自带的模块。对于2.x版本中的urllib2库,在python3.x中集成到urllib中,在其request等子模块中。urllib中的urlopen函数用于打开url,并获取url数据。urlopen函数的参数可以是url链接,也可以使request对象,对于简单的网页,直接使用url字符串做参数就已足够,但对于复杂的网页,设有防爬虫机制的网页,再使用urlopen函数时,需要添加http header。对于带有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载到的url数据中提取有价值的数据和新的url。对于数据的提取,可以使用正则表达式和BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对于特点比较鲜明的目标数据具有较好的作用,但通用性不高。BeautifulSoup是第三方模块,用于结构化解析url内容。将下载到的网页内容解析为DOM树,下图为使用BeautifulSoup打印抓取到的百度百科中某网页的输出的一部分。

关于BeautifulSoup的具体使用,在以后的文章中再写。下面的代码使用python抓取百度百科中英雄联盟词条中的其他与英雄联盟相关的词条,并将这些词条保存在新建的excel中。上代码:
from bs4 import BeautifulSoup
import re
import xlrd
<span style="font-size:18px;">import xlwt
from urllib.request import urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('league of legend')
## 百度百科:英雄联盟##
html=urlopen("http://baike.baidu.com/subview/3049782/11262116.htm")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
row=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$"))
for link in links:
if 'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
row=row+1
excelFile.save('E:\Project\Python\lol.xls')</span> 输出的部分截图如下:

excel部分的截图如下:

以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI has started to provide developers with access to extended context windows and cost-saving features, starting with the Gemini 1.5 Pro large language model (LLM). Previously available through a waitlist, the full 2 million token context windo
 How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download DeepSeek Xiaomi? Search for "DeepSeek" in the Xiaomi App Store. If it is not found, continue to step 2. Identify your needs (search files, data analysis), and find the corresponding tools (such as file managers, data analysis software) that include DeepSeek functions.
 How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
The key to using DeepSeek effectively is to ask questions clearly: express the questions directly and specifically. Provide specific details and background information. For complex inquiries, multiple angles and refute opinions are included. Focus on specific aspects, such as performance bottlenecks in code. Keep a critical thinking about the answers you get and make judgments based on your expertise.
 How to search deepseek
Feb 19, 2025 pm 05:18 PM
How to search deepseek
Feb 19, 2025 pm 05:18 PM
Just use the search function that comes with DeepSeek. Its powerful semantic analysis algorithm can accurately understand the search intention and provide relevant information. However, for searches that are unpopular, latest information or problems that need to be considered, it is necessary to adjust keywords or use more specific descriptions, combine them with other real-time information sources, and understand that DeepSeek is just a tool that requires active, clear and refined search strategies.
 How to program deepseek
Feb 19, 2025 pm 05:36 PM
How to program deepseek
Feb 19, 2025 pm 05:36 PM
DeepSeek is not a programming language, but a deep search concept. Implementing DeepSeek requires selection based on existing languages. For different application scenarios, it is necessary to choose the appropriate language and algorithms, and combine machine learning technology. Code quality, maintainability, and testing are crucial. Only by choosing the right programming language, algorithms and tools according to your needs and writing high-quality code can DeepSeek be successfully implemented.
 How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
Question: Is DeepSeek available for accounting? Answer: No, it is a data mining and analysis tool that can be used to analyze financial data, but it does not have the accounting record and report generation functions of accounting software. Using DeepSeek to analyze financial data requires writing code to process data with knowledge of data structures, algorithms, and DeepSeek APIs to consider potential problems (e.g. programming knowledge, learning curves, data quality)
 The Key to Coding: Unlocking the Power of Python for Beginners
Oct 11, 2024 pm 12:17 PM
The Key to Coding: Unlocking the Power of Python for Beginners
Oct 11, 2024 pm 12:17 PM
Python is an ideal programming introduction language for beginners through its ease of learning and powerful features. Its basics include: Variables: used to store data (numbers, strings, lists, etc.). Data type: Defines the type of data in the variable (integer, floating point, etc.). Operators: used for mathematical operations and comparisons. Control flow: Control the flow of code execution (conditional statements, loops).
 Problem-Solving with Python: Unlock Powerful Solutions as a Beginner Coder
Oct 11, 2024 pm 08:58 PM
Problem-Solving with Python: Unlock Powerful Solutions as a Beginner Coder
Oct 11, 2024 pm 08:58 PM
Pythonempowersbeginnersinproblem-solving.Itsuser-friendlysyntax,extensivelibrary,andfeaturessuchasvariables,conditionalstatements,andloopsenableefficientcodedevelopment.Frommanagingdatatocontrollingprogramflowandperformingrepetitivetasks,Pythonprovid
