

用Python从零实现贝叶斯分类器的机器学习的教程

朴素贝叶斯算法简单高效,在处理分类问题上,是应该首先考虑的方法之一。
通过本教程,你将学到朴素贝叶斯算法的原理和Python版本的逐步实现。
更新:查看后续的关于朴素贝叶斯使用技巧的文章“Better Naive Bayes: 12 Tips To Get The Most From The Naive Bayes Algorithm”
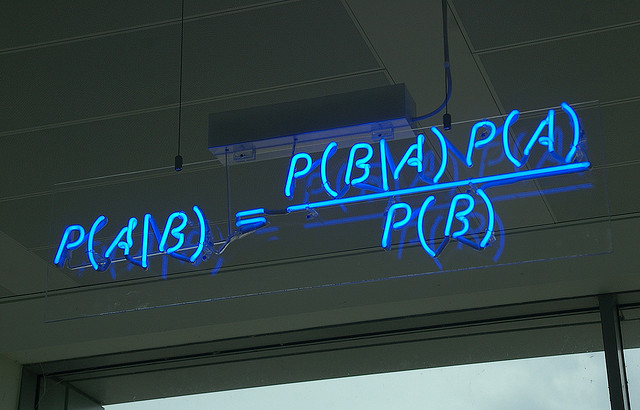 朴素贝叶斯分类器,Matt Buck保留部分版权
朴素贝叶斯分类器,Matt Buck保留部分版权
关于朴素贝叶斯
朴素贝叶斯算法是一个直观的方法,使用每个属性归属于某个类的概率来做预测。你可以使用这种监督性学习方法,对一个预测性建模问题进行概率建模。
给定一个类,朴素贝叶斯假设每个属性归属于此类的概率独立于其余所有属性,从而简化了概率的计算。这种强假定产生了一个快速、有效的方法。
给定一个属性值,其属于某个类的概率叫做条件概率。对于一个给定的类值,将每个属性的条件概率相乘,便得到一个数据样本属于某个类的概率。
我们可以通过计算样本归属于每个类的概率,然后选择具有最高概率的类来做预测。
通常,我们使用分类数据来描述朴素贝叶斯,因为这样容易通过比率来描述、计算。一个符合我们目的、比较有用的算法需要支持数值属性,同时假设每一个数值属性服从正态分布(分布在一个钟形曲线上),这又是一个强假设,但是依然能够给出一个健壮的结果。
预测糖尿病的发生
本文使用的测试问题是“皮马印第安人糖尿病问题”。
这个问题包括768个对于皮马印第安患者的医疗观测细节,记录所描述的瞬时测量取自诸如患者的年纪,怀孕和血液检查的次数。所有患者都是21岁以上(含21岁)的女性,所有属性都是数值型,而且属性的单位各不相同。
每一个记录归属于一个类,这个类指明以测量时间为止,患者是否是在5年之内感染的糖尿病。如果是,则为1,否则为0。
机器学习文献中已经多次研究了这个标准数据集,好的预测精度为70%-76%。
下面是pima-indians.data.csv文件中的一个样本,了解一下我们将要使用的数据。
注意:下载文件,然后以.csv扩展名保存(如:pima-indians-diabetes.data.csv)。查看文件中所有属性的描述。
6,148,72,35,0,33.6,0.627,50,1 1,85,66,29,0,26.6,0.351,31,0 8,183,64,0,0,23.3,0.672,32,1 1,89,66,23,94,28.1,0.167,21,0 0,137,40,35,168,43.1,2.288,33,1
朴素贝叶斯算法教程
教程分为如下几步:
1.处理数据:从CSV文件中载入数据,然后划分为训练集和测试集。
2.提取数据特征:提取训练数据集的属性特征,以便我们计算概率并做出预测。
3.单一预测:使用数据集的特征生成单个预测。
4.多重预测:基于给定测试数据集和一个已提取特征的训练数据集生成预测。
5.评估精度:评估对于测试数据集的预测精度作为预测正确率。
6.合并代码:使用所有代码呈现一个完整的、独立的朴素贝叶斯算法的实现。
1.处理数据
首先加载数据文件。CSV格式的数据没有标题行和任何引号。我们可以使用csv模块中的open函数打开文件,使用reader函数读取行数据。
我们也需要将以字符串类型加载进来属性转换为我们可以使用的数字。下面是用来加载匹马印第安人数据集(Pima indians dataset)的loadCsv()函数。
import csv
def loadCsv(filename):
lines = csv.reader(open(filename, "rb"))
dataset = list(lines)
for i in range(len(dataset)):
dataset[i] = [float(x) for x in dataset[i]]
return dataset
我们可以通过加载皮马印第安人数据集,然后打印出数据样本的个数,以此测试这个函数。
filename = 'pima-indians-diabetes.data.csv'
dataset = loadCsv(filename)
print('Loaded data file {0} with {1} rows').format(filename, len(dataset))
运行测试,你会看到如下结果:
Loaded data file iris.data.csv with 150 rows
下一步,我们将数据分为用于朴素贝叶斯预测的训练数据集,以及用来评估模型精度的测试数据集。我们需要将数据集随机分为包含67%的训练集合和包含33%的测试集(这是在此数据集上测试算法的通常比率)。
下面是splitDataset()函数,它以给定的划分比例将数据集进行划分。
import random
def splitDataset(dataset, splitRatio):
trainSize = int(len(dataset) * splitRatio)
trainSet = []
copy = list(dataset)
while len(trainSet) < trainSize:
index = random.randrange(len(copy))
trainSet.append(copy.pop(index))
return [trainSet, copy]
我们可以定义一个具有5个样例的数据集来进行测试,首先它分为训练数据集和测试数据集,然后打印出来,看看每个数据样本最终落在哪个数据集。
dataset = [[1], [2], [3], [4], [5]]
splitRatio = 0.67
train, test = splitDataset(dataset, splitRatio)
print('Split {0} rows into train with {1} and test with {2}').format(len(dataset), train, test)
运行测试,你会看到如下结果:
Split 5 rows into train with [[4], [3], [5]] and test with [[1], [2]]
提取数据特征
朴素贝叶斯模型包含训练数据集中数据的特征,然后使用这个数据特征来做预测。
所收集的训练数据的特征,包含相对于每个类的每个属性的均值和标准差。举例来说,如果如果有2个类和7个数值属性,然后我们需要每一个属性(7)和类(2)的组合的均值和标准差,也就是14个属性特征。
在对特定的属性归属于每个类的概率做计算、预测时,将用到这些特征。
我们将数据特征的获取划分为以下的子任务:
按类别划分数据
计算均值
计算标准差
提取数据集特征
按类别提取属性特征
按类别划分数据
首先将训练数据集中的样本按照类别进行划分,然后计算出每个类的统计数据。我们可以创建一个类别到属于此类别的样本列表的的映射,并将整个数据集中的样本分类到相应的列表。
下面的SeparateByClass()函数可以完成这个任务:
def separateByClass(dataset):
separated = {}
for i in range(len(dataset)):
vector = dataset[i]
if (vector[-1] not in separated):
separated[vector[-1]] = []
separated[vector[-1]].append(vector)
return separated
可以看出,函数假设样本中最后一个属性(-1)为类别值,返回一个类别值到数据样本列表的映射。
我们可以用一些样本数据测试如下:
dataset = [[1,20,1], [2,21,0], [3,22,1]]
separated = separateByClass(dataset)
print('Separated instances: {0}').format(separated)
运行测试,你会看到如下结果:
Separated instances: {0: [[2, 21, 0]], 1: [[1, 20, 1], [3, 22, 1]]}
计算均值
我们需要计算在每个类中每个属性的均值。均值是数据的中点或者集中趋势,在计算概率时,我们用它作为高斯分布的中值。
我们也需要计算每个类中每个属性的标准差。标准差描述了数据散布的偏差,在计算概率时,我们用它来刻画高斯分布中,每个属性所期望的散布。
标准差是方差的平方根。方差是每个属性值与均值的离差平方的平均数。注意我们使用N-1的方法(译者注:参见无偏估计),也就是在在计算方差时,属性值的个数减1。
import math def mean(numbers): return sum(numbers)/float(len(numbers)) def stdev(numbers): avg = mean(numbers) variance = sum([pow(x-avg,2) for x in numbers])/float(len(numbers)-1) return math.sqrt(variance)
通过计算从1到5这5个数的均值来测试函数。
numbers = [1,2,3,4,5]
print('Summary of {0}: mean={1}, stdev={2}').format(numbers, mean(numbers), stdev(numbers))
运行测试,你会看到如下结果:
Summary of [1, 2, 3, 4, 5]: mean=3.0, stdev=1.58113883008
提取数据集的特征
现在我们可以提取数据集特征。对于一个给定的样本列表(对应于某个类),我们可以计算每个属性的均值和标准差。
zip函数将数据样本按照属性分组为一个个列表,然后可以对每个属性计算均值和标准差。
def summarize(dataset): summaries = [(mean(attribute), stdev(attribute)) for attribute in zip(*dataset)] del summaries[-1] return summaries
我们可以使用一些测试数据来测试这个summarize()函数,测试数据对于第一个和第二个数据属性的均值和标准差显示出显著的不同。
dataset = [[1,20,0], [2,21,1], [3,22,0]]
summary = summarize(dataset)
print('Attribute summaries: {0}').format(summary)
运行测试,你会看到如下结果:
Attribute summaries: [(2.0, 1.0), (21.0, 1.0)]
按类别提取属性特征
合并代码,我们首先将训练数据集按照类别进行划分,然后计算每个属性的摘要。
def summarizeByClass(dataset):
separated = separateByClass(dataset)
summaries = {}
for classValue, instances in separated.iteritems():
summaries[classValue] = summarize(instances)
return summaries
使用小的测试数据集来测试summarizeByClass()函数。
dataset = [[1,20,1], [2,21,0], [3,22,1], [4,22,0]]
summary = summarizeByClass(dataset)
print('Summary by class value: {0}').format(summary)
运行测试,你会看到如下结果:
Summary by class value:
{0: [(3.0, 1.4142135623730951), (21.5, 0.7071067811865476)],
1: [(2.0, 1.4142135623730951), (21.0, 1.4142135623730951)]}
预测
我们现在可以使用从训练数据中得到的摘要来做预测。做预测涉及到对于给定的数据样本,计算其归属于每个类的概率,然后选择具有最大概率的类作为预测结果。
我们可以将这部分划分成以下任务:
计算高斯概率密度函数
计算对应类的概率
单一预测
评估精度
计算高斯概率密度函数
给定来自训练数据中已知属性的均值和标准差,我们可以使用高斯函数来评估一个给定的属性值的概率。
已知每个属性和类值的属性特征,在给定类值的条件下,可以得到给定属性值的条件概率。
关于高斯概率密度函数,可以查看参考文献。总之,我们要把已知的细节融入到高斯函数(属性值,均值,标准差),并得到属性值归属于某个类的似然(译者注:即可能性)。
在calculateProbability()函数中,我们首先计算指数部分,然后计算等式的主干。这样可以将其很好地组织成2行。
import math def calculateProbability(x, mean, stdev): exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2)))) return (1 / (math.sqrt(2*math.pi) * stdev)) * exponent
使用一些简单的数据测试如下:
x = 71.5
mean = 73
stdev = 6.2
probability = calculateProbability(x, mean, stdev)
print('Probability of belonging to this class: {0}').format(probability)
运行测试,你会看到如下结果:
Probability of belonging to this class: 0.0624896575937
计算所属类的概率
既然我们可以计算一个属性属于某个类的概率,那么合并一个数据样本中所有属性的概率,最后便得到整个数据样本属于某个类的概率。
使用乘法合并概率,在下面的calculClassProbilities()函数中,给定一个数据样本,它所属每个类别的概率,可以通过将其属性概率相乘得到。结果是一个类值到概率的映射。
def calculateClassProbabilities(summaries, inputVector):
probabilities = {}
for classValue, classSummaries in summaries.iteritems():
probabilities[classValue] = 1
for i in range(len(classSummaries)):
mean, stdev = classSummaries[i]
x = inputVector[i]
probabilities[classValue] *= calculateProbability(x, mean, stdev)
return probabilities
测试calculateClassProbabilities()函数。
summaries = {0:[(1, 0.5)], 1:[(20, 5.0)]}
inputVector = [1.1, '?']
probabilities = calculateClassProbabilities(summaries, inputVector)
print('Probabilities for each class: {0}').format(probabilities)
运行测试,你会看到如下结果:
Probabilities for each class: {0: 0.7820853879509118, 1: 6.298736258150442e-05}
单一预测
既然可以计算一个数据样本属于每个类的概率,那么我们可以找到最大的概率值,并返回关联的类。
下面的predict()函数可以完成以上任务。
def predict(summaries, inputVector):
probabilities = calculateClassProbabilities(summaries, inputVector)
bestLabel, bestProb = None, -1
for classValue, probability in probabilities.iteritems():
if bestLabel is None or probability > bestProb:
bestProb = probability
bestLabel = classValue
return bestLabel
测试predict()函数如下:
summaries = {'A':[(1, 0.5)], 'B':[(20, 5.0)]}
inputVector = [1.1, '?']
result = predict(summaries, inputVector)
print('Prediction: {0}').format(result)
运行测试,你会得到如下结果:
Prediction: A
多重预测
最后,通过对测试数据集中每个数据样本的预测,我们可以评估模型精度。getPredictions()函数可以实现这个功能,并返回每个测试样本的预测列表。
def getPredictions(summaries, testSet):
predictions = []
for i in range(len(testSet)):
result = predict(summaries, testSet[i])
predictions.append(result)
return predictions
测试getPredictions()函数如下。
summaries = {'A':[(1, 0.5)], 'B':[(20, 5.0)]}
testSet = [[1.1, '?'], [19.1, '?']]
predictions = getPredictions(summaries, testSet)
print('Predictions: {0}').format(predictions)
运行测试,你会看到如下结果:
Predictions: ['A', 'B']
计算精度
预测值和测试数据集中的类别值进行比较,可以计算得到一个介于0%~100%精确率作为分类的精确度。getAccuracy()函数可以计算出这个精确率。
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet))) * 100.0
我们可以使用如下简单的代码来测试getAccuracy()函数。
testSet = [[1,1,1,'a'], [2,2,2,'a'], [3,3,3,'b']]
predictions = ['a', 'a', 'a']
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: {0}').format(accuracy)
运行测试,你会得到如下结果:
Accuracy: 66.6666666667
合并代码
最后,我们需要将代码连贯起来。
下面是朴素贝叶斯Python版的逐步实现的全部代码。
# Example of Naive Bayes implemented from Scratch in Python
import csv
import random
import math
def loadCsv(filename):
lines = csv.reader(open(filename, "rb"))
dataset = list(lines)
for i in range(len(dataset)):
dataset[i] = [float(x) for x in dataset[i]]
return dataset
def splitDataset(dataset, splitRatio):
trainSize = int(len(dataset) * splitRatio)
trainSet = []
copy = list(dataset)
while len(trainSet) < trainSize:
index = random.randrange(len(copy))
trainSet.append(copy.pop(index))
return [trainSet, copy]
def separateByClass(dataset):
separated = {}
for i in range(len(dataset)):
vector = dataset[i]
if (vector[-1] not in separated):
separated[vector[-1]] = []
separated[vector[-1]].append(vector)
return separated
def mean(numbers):
return sum(numbers)/float(len(numbers))
def stdev(numbers):
avg = mean(numbers)
variance = sum([pow(x-avg,2) for x in numbers])/float(len(numbers)-1)
return math.sqrt(variance)
def summarize(dataset):
summaries = [(mean(attribute), stdev(attribute)) for attribute in zip(*dataset)]
del summaries[-1]
return summaries
def summarizeByClass(dataset):
separated = separateByClass(dataset)
summaries = {}
for classValue, instances in separated.iteritems():
summaries[classValue] = summarize(instances)
return summaries
def calculateProbability(x, mean, stdev):
exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2))))
return (1 / (math.sqrt(2*math.pi) * stdev)) * exponent
def calculateClassProbabilities(summaries, inputVector):
probabilities = {}
for classValue, classSummaries in summaries.iteritems():
probabilities[classValue] = 1
for i in range(len(classSummaries)):
mean, stdev = classSummaries[i]
x = inputVector[i]
probabilities[classValue] *= calculateProbability(x, mean, stdev)
return probabilities
def predict(summaries, inputVector):
probabilities = calculateClassProbabilities(summaries, inputVector)
bestLabel, bestProb = None, -1
for classValue, probability in probabilities.iteritems():
if bestLabel is None or probability > bestProb:
bestProb = probability
bestLabel = classValue
return bestLabel
def getPredictions(summaries, testSet):
predictions = []
for i in range(len(testSet)):
result = predict(summaries, testSet[i])
predictions.append(result)
return predictions
def getAccuracy(testSet, predictions):
correct = 0
for i in range(len(testSet)):
if testSet[i][-1] == predictions[i]:
correct += 1
return (correct/float(len(testSet))) * 100.0
def main():
filename = 'pima-indians-diabetes.data.csv'
splitRatio = 0.67
dataset = loadCsv(filename)
trainingSet, testSet = splitDataset(dataset, splitRatio)
print('Split {0} rows into train={1} and test={2} rows').format(len(dataset), len(trainingSet), len(testSet))
# prepare model
summaries = summarizeByClass(trainingSet)
# test model
predictions = getPredictions(summaries, testSet)
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: {0}%').format(accuracy)
main()
运行示例,得到如下输出:
Split 768 rows into train=514 and test=254 rows Accuracy: 76.3779527559%

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download DeepSeek Xiaomi? Search for "DeepSeek" in the Xiaomi App Store. If it is not found, continue to step 2. Identify your needs (search files, data analysis), and find the corresponding tools (such as file managers, data analysis software) that include DeepSeek functions.
 How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
The key to using DeepSeek effectively is to ask questions clearly: express the questions directly and specifically. Provide specific details and background information. For complex inquiries, multiple angles and refute opinions are included. Focus on specific aspects, such as performance bottlenecks in code. Keep a critical thinking about the answers you get and make judgments based on your expertise.
 How to search deepseek
Feb 19, 2025 pm 05:18 PM
How to search deepseek
Feb 19, 2025 pm 05:18 PM
Just use the search function that comes with DeepSeek. Its powerful semantic analysis algorithm can accurately understand the search intention and provide relevant information. However, for searches that are unpopular, latest information or problems that need to be considered, it is necessary to adjust keywords or use more specific descriptions, combine them with other real-time information sources, and understand that DeepSeek is just a tool that requires active, clear and refined search strategies.
 How to program deepseek
Feb 19, 2025 pm 05:36 PM
How to program deepseek
Feb 19, 2025 pm 05:36 PM
DeepSeek is not a programming language, but a deep search concept. Implementing DeepSeek requires selection based on existing languages. For different application scenarios, it is necessary to choose the appropriate language and algorithms, and combine machine learning technology. Code quality, maintainability, and testing are crucial. Only by choosing the right programming language, algorithms and tools according to your needs and writing high-quality code can DeepSeek be successfully implemented.
 How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
Question: Is DeepSeek available for accounting? Answer: No, it is a data mining and analysis tool that can be used to analyze financial data, but it does not have the accounting record and report generation functions of accounting software. Using DeepSeek to analyze financial data requires writing code to process data with knowledge of data structures, algorithms, and DeepSeek APIs to consider potential problems (e.g. programming knowledge, learning curves, data quality)
 The Key to Coding: Unlocking the Power of Python for Beginners
Oct 11, 2024 pm 12:17 PM
The Key to Coding: Unlocking the Power of Python for Beginners
Oct 11, 2024 pm 12:17 PM
Python is an ideal programming introduction language for beginners through its ease of learning and powerful features. Its basics include: Variables: used to store data (numbers, strings, lists, etc.). Data type: Defines the type of data in the variable (integer, floating point, etc.). Operators: used for mathematical operations and comparisons. Control flow: Control the flow of code execution (conditional statements, loops).
 Problem-Solving with Python: Unlock Powerful Solutions as a Beginner Coder
Oct 11, 2024 pm 08:58 PM
Problem-Solving with Python: Unlock Powerful Solutions as a Beginner Coder
Oct 11, 2024 pm 08:58 PM
Pythonempowersbeginnersinproblem-solving.Itsuser-friendlysyntax,extensivelibrary,andfeaturessuchasvariables,conditionalstatements,andloopsenableefficientcodedevelopment.Frommanagingdatatocontrollingprogramflowandperformingrepetitivetasks,Pythonprovid
 How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
Detailed explanation of DeepSeekAPI access and call: Quick Start Guide This article will guide you in detail how to access and call DeepSeekAPI, helping you easily use powerful AI models. Step 1: Get the API key to access the DeepSeek official website and click on the "Open Platform" in the upper right corner. You will get a certain number of free tokens (used to measure API usage). In the menu on the left, click "APIKeys" and then click "Create APIkey". Name your APIkey (for example, "test") and copy the generated key right away. Be sure to save this key properly, as it will only be displayed once
