

Today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and map construction) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate that SL-SLAM outperforms state-of-the-art SLAM algorithms in terms of positioning accuracy and tracking robustness.
Project link: https://github.com/zzzzxxxx111/SLslam.
(Swipe your thumb up and click on the top card to follow me, The whole operation will only take you 1.328 seconds, and then you will take away all the future, free and useful information, in case there is any content that is helpful to you~)
SLAM (simultaneous localization and mapping) is a key technology in robotics, autonomous driving and 3D reconstruction. It simultaneously determines the position of the sensor (positioning) and builds a map of the environment. . Vision and inertial sensors are the most commonly used sensing devices, and related solutions have been discussed and explored in depth. After decades of development, the processing framework of visual (inertial) SLAM has formed a basic framework, including tracking, map construction and loop detection. In the SLAM algorithm, the tracking module is responsible for estimating the robot's trajectory, the map building module is used to generate and update the environment map, and the loop detection is used to identify the visited locations. These modules collaborate with each other to achieve awareness of the robot's status and environment. Commonly used algorithms in visual SLAM include feature point method, direct method and semi-direct method. In the feature point method, the camera pose and three-dimensional point cloud are estimated by extracting and matching feature points; the direct method directly estimates the camera pose and three-dimensional point cloud by minimizing the image grayscale difference. In recent years, related research has focused on improving the performance of the camera under extreme conditions. robustness and adaptability. Due to the long history of development of SLAM technology, there are many representative SLAM works based on traditional geometric methods, such as ORB-SLAM, VINS-Mono, DVO, MSCKF, etc. However, some unresolved questions remain. In challenging environments such as low light or dynamic lighting, severe jitter and weak texture areas, since traditional feature extraction algorithms only consider the local information of the image without considering the structural and semantic information of the image, when encountering the above situations, existing The tracking of the SLAM system may become unstable and ineffective. Therefore, under these conditions, the tracking of the SLAM system may become unstable and ineffective.
The rapid development of deep learning has brought revolutionary changes to the field of computer vision. By utilizing large amounts of data for training, deep learning models can simulate complex scene structures and semantic information, thereby improving the SLAM system's ability to understand and express scenes. This method is mainly divided into two approaches. The first is an end-to-end algorithm based on deep learning, such as Droid-slam, NICE-SLAM, and DVI-SLAM. However, these methods require a large amount of data for training, high computing resources and storage space, making it difficult to achieve real-time tracking. The second approach is called hybrid SLAM, which leverages deep learning to enhance specific modules in SLAM. Hybrid SLAM takes full advantage of traditional geometric methods and deep learning methods, and can find a balance between almost any constraints and semantic understanding. Although there have been some studies in this field, how to effectively integrate deep learning technology is still a direction worthy of further research.
Currently, existing hybrid SLAM has some limitations. DXNet simply replaces ORB feature points with deep feature points, but continues to use traditional methods to track these features. Therefore, this may lead to incoherence in depth feature information. SP-Loop only introduces deep learning feature points into the closed-loop module, while retaining traditional feature point extraction methods elsewhere. Therefore, these hybrid SLAM methods do not effectively and comprehensively combine deep learning technology, resulting in a decline in tracking and mapping effects in some complex scenes.
In order to solve these problems, a multifunctional SLAM system based on deep learning is proposed here. Integrate the Superpoint feature point extraction module into the system and use it as the only form of expression throughout. Furthermore, in complex environments, traditional feature matching methods often exhibit instability, leading to a decrease in tracking and mapping quality. However, recent advances in deep learning-based feature matching methods have shown the potential to achieve improved matching performance in complex environments. These methods exploit prior information and structural details of the scene to enhance the effectiveness of matching. As the latest SOTA (state-of-the-art) matching method, Lightglue has advantages for SLAM systems that require high real-time performance because of its efficient and lightweight characteristics. Therefore, we have replaced the feature matching method in the overall SLAM system with Lightglue, which improves robustness and accuracy compared to traditional methods.
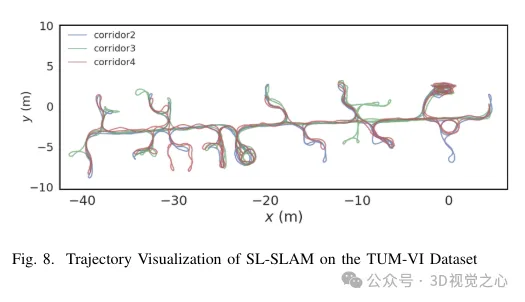
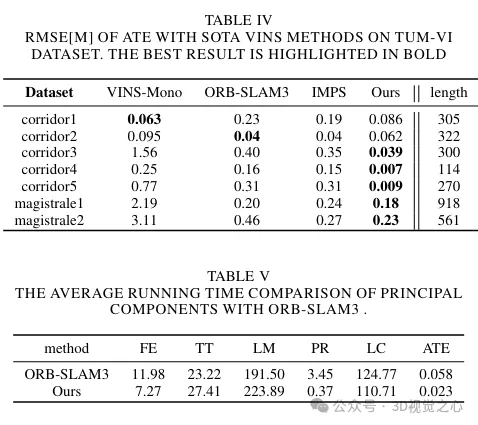
When processing the Superpoint feature point descriptor, we preprocess it to be consistent with the training of the corresponding bag of visual words. When combined with Lightglue, this approach achieves precise scene recognition. At the same time, in order to maintain the balance between accuracy and efficiency, a feature point selection strategy is designed. Considering scalability, portability, and real-time performance, we utilize the ONNX Runtime library to deploy these deep learning models. Finally, a series of experiments are designed to prove that the method improves the trajectory prediction accuracy and tracking robustness of the SLAM algorithm in a variety of challenging scenarios, as shown in Figure 8.
The system structure of SL-SLAM is shown in Figure 2. There are four main types of this system Sensor configurations, i.e. monocular, monocular inertial, binocular and binocular inertial. The system is based on ORB-SLAM3 as the baseline and contains three main modules: tracking, local mapping and loop detection. To integrate deep learning models into the system, the ONNX Runtime deep learning deployment framework is used, combining SuperPoint and LightGlue models.
For each input image, the system first inputs it into the SuperPoint network to obtain the probability tensor and descriptor tensor of the feature points. The system then initializes with two frames and performs coarse tracking on each subsequent frame. It further refines pose estimation by tracking local maps. In the event of tracking failure, the system either uses a reference frame for tracking or performs relocalization to reacquire the pose. Please note that LightGlue is used for feature matching during coarse tracking, initialization, reference frame tracking, and relocation. This ensures accurate and robust matching relationships, thereby increasing tracking effectiveness.
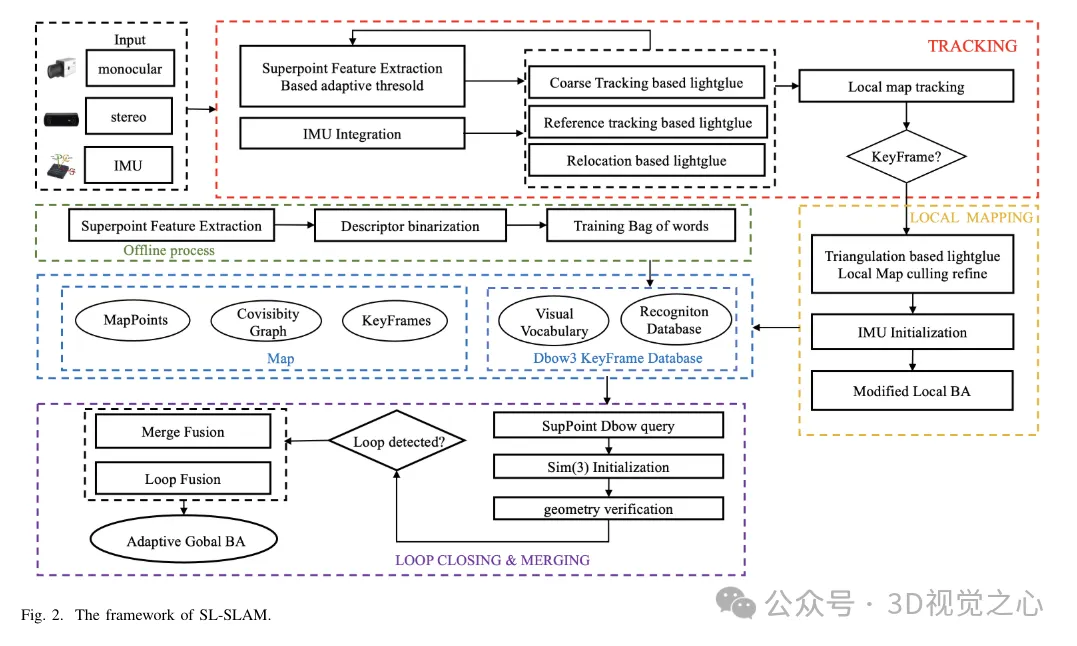
In the baseline algorithm, the main role of the local mapping thread is to dynamically construct a local map in real time, including map points and key frames. It utilizes local maps to perform bundle adjustment optimization, thereby reducing tracking errors and enhancing consistency. The local mapping thread uses keyframes output by the tracking thread, LightGlue-based triangulation and adaptive local bundle adjustment (BA) optimization to reconstruct accurate map points. Redundant map points and keyframes are then distinguished and removed.
The closed-loop correction thread utilizes a keyframe database and bag-of-words model trained on SuperPoint descriptors to retrieve similar keyframes. Enhance retrieval efficiency by binarizing SuperPoint descriptors. Selected keyframes are feature matched using LightGlue for common view geometry verification, reducing the possibility of mismatches. Finally, closed-loop fusion and global BA (Bundle Adjustment) are performed to optimize the overall posture.
SuperPoint network structure: SuperPoint network architecture mainly consists of three parts: a shared encoder, a feature detection decoder and a descriptor decoder. The encoder is a VGG-style network capable of reducing image dimensions and extracting features. The task of the feature detection decoder is to calculate the probability of each pixel in the image to determine its likelihood of being a feature point. The descriptor decoding network utilizes sub-pixel convolution to reduce the computational complexity of the decoding process. The network then outputs a semi-dense descriptor, and a bicubic interpolation algorithm is applied to obtain the complete descriptor. After obtaining the feature point tensor and descriptor tensor output by the network, in order to improve the robustness of feature extraction, we adopt an adaptive threshold selection strategy to filter the feature points and perform post-processing operations to obtain the feature points and its descriptors. The specific structure of the feature extraction module is shown in Figure 3.
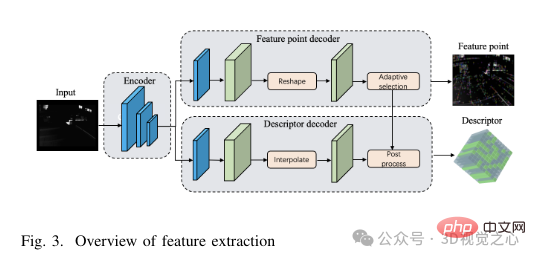
Adaptive feature selection: First, each image, labeled I(W × H), is resized to match the input image size of the SuperPoint network (W′ × H′), it will be converted to grayscale image first. Images that are too small may hinder feature extraction, thereby reducing tracking performance, while images that are too large may result in excessive computational requirements and memory usage. Therefore, in order to balance the accuracy and efficiency of feature extraction, this article chooses W′ = 400 and H′ = 300. Subsequently, a tensor of size W′ × H′ is fed into the network, producing two output tensors: the score tensor S, and the descriptor tensor D. Once the feature point score tensor and feature descriptor are obtained, the next step is to set a threshold th to filter the feature points.
In challenging scenarios, the confidence of each feature point will be reduced. If a fixed confidence threshold th is adopted, it may lead to a reduction in the number of extracted features. To solve this problem, we introduce an adaptive SuperPoint threshold setting strategy. This adaptive method dynamically adjusts the thresholds for feature extraction based on the scene, thereby achieving more robust feature extraction in challenging scenes. The adaptive threshold mechanism takes into account two factors: intra-feature relationships and inter-frame feature relationships.
In challenging scenarios, the confidence of each feature point will be reduced. If a fixed confidence threshold th is adopted, it may lead to a reduction in the number of extracted features. In order to solve this problem, an adaptive SuperPoint threshold setting strategy is introduced. This adaptive method dynamically adjusts the thresholds for feature extraction based on the scene, thereby achieving more robust feature extraction in challenging scenes. The adaptive threshold mechanism takes into account two factors: intra-feature relationships and inter-frame feature relationships.
LightGlue network structure: The LightGlue model consists of multiple identical layers that jointly process two groups feature. Each layer contains self-attention and cross-attention units for updating the representation of points. Classifiers in each layer decide where to stop inference, avoiding unnecessary computations. Finally, a lightweight header computes partial match scores. The depth of the network dynamically adjusts based on the complexity of the input image. If the image pairs are easily matched, early termination can be achieved due to the high confidence of the tags. As a result, LightGlue has shorter runtimes and lower memory consumption, making it suitable for integration into tasks requiring real-time performance.
The time interval between adjacent frames is usually only tens of milliseconds. ORB-SLAM3 assumes that the camera moves at a constant speed during this short period of time. It uses the pose and velocity of the previous frame to estimate the pose of the current frame and uses this estimated pose for projection matching. It then searches for matching points within a certain range and refines the pose accordingly. However, in reality, camera movement may not always be uniform. Sudden acceleration, deceleration, or rotation may adversely affect the effectiveness of this method. Lightglue can effectively solve this problem by directly matching features between the current frame and the previous frame. It then uses these matched features to refine the initial pose estimate, thereby reducing the negative effects of sudden acceleration or rotation.
In the event that image tracking fails in a previous frame, whether due to sudden camera movement or other factors, reference keyframes need to be used for tracking or repositioning. The baseline algorithm uses the Bag-of-Words (BoW) method to accelerate feature matching between the current frame and the reference frame. However, the BoW method converts spatial information into statistical information based on visual vocabulary, which may lose the accurate spatial relationship between feature points. Furthermore, if the visual vocabulary used in the BoW model is insufficient or not representative enough, it may not capture the rich features of the scene, leading to inaccuracies in the matching process.
Combined with Lightglue tracking: Since the time interval between adjacent frames is very short, usually only tens of milliseconds, ORB-SLAM3 assumes that the camera moves at a uniform speed during this period. It uses the pose and velocity of the previous frame to estimate the pose of the current frame and uses this estimated pose for projection matching. It then searches for matching points within a certain range and refines the pose accordingly. However, in reality, camera movement may not always be uniform. Sudden acceleration, deceleration, or rotation may adversely affect the effectiveness of this method. Lightglue can effectively solve this problem by directly matching features between the current frame and the previous frame. It then uses these matched features to refine the initial pose estimate, thereby reducing the negative effects of sudden acceleration or rotation.
In the event that image tracking fails in a previous frame, whether due to sudden camera movement or other factors, reference keyframes need to be used for tracking or repositioning. The baseline algorithm uses the Bag-of-Words (BoW) method to accelerate feature matching between the current frame and the reference frame. However, the BoW method converts spatial information into statistical information based on visual vocabulary, which may lose the accurate spatial relationship between feature points. Furthermore, if the visual vocabulary used in the BoW model is insufficient or not representative enough, it may not capture the rich features of the scene, leading to inaccuracies in the matching process.

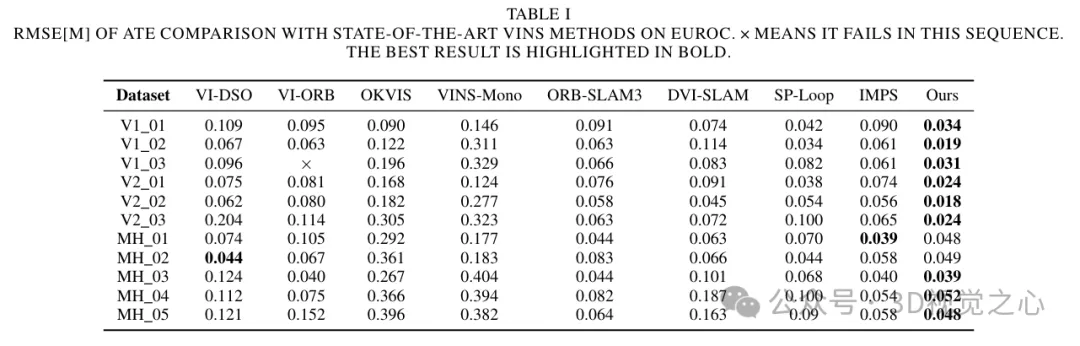
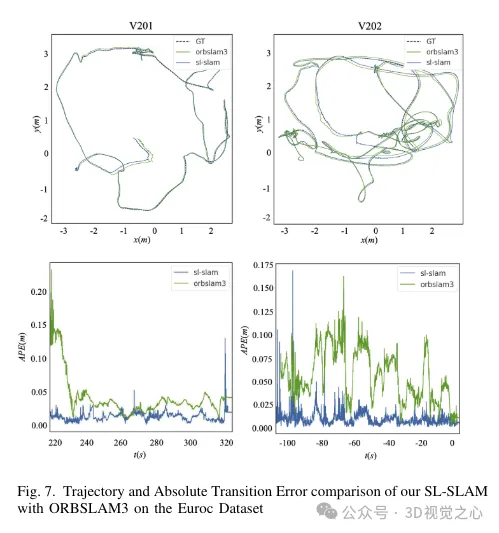
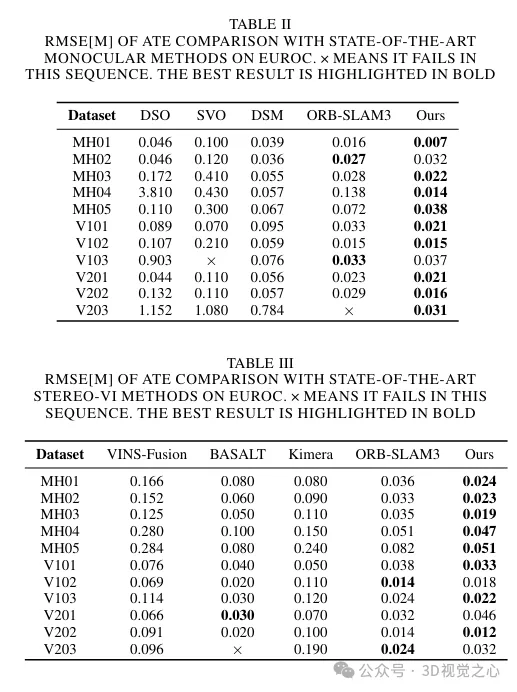
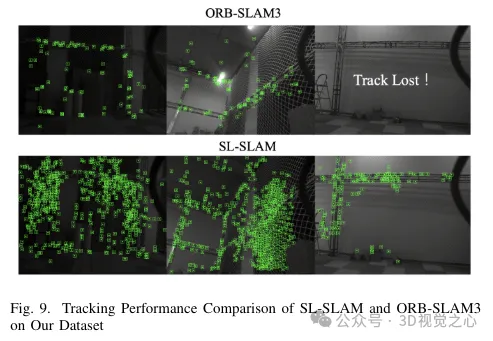
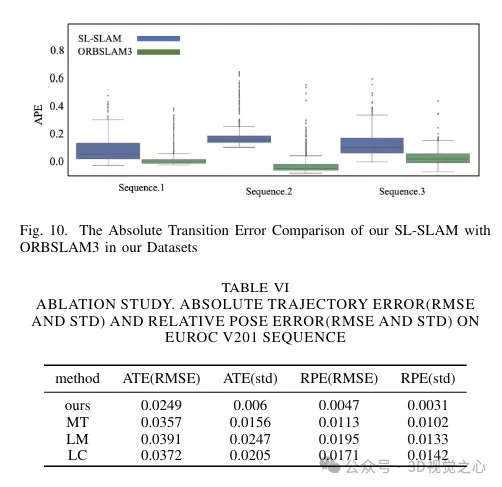
To solve these problems, the BoW method was replaced with Lightglue throughout the system. This change significantly improves the probability of successful tracking and relocalization under large-scale transformations, thereby enhancing the accuracy and robustness of our tracking process. Figure 4 demonstrates the effectiveness of different matching methods. It can be observed that the matching method based on Lightglue shows better matching performance than the matching method based on projection or Bag-of-Words used in ORB-SLAM3. Therefore, during the SLAM operation, it makes the tracking of map points more uniform and stable, as shown in Figure 6.
Local mapping combined with Lightglue: In the local mapping thread, the triangulation of new map points is completed through the current keyframe and its adjacent keyframes of. To get more accurate map points, you need to match against keyframes with a larger baseline. However, ORB-SLAM3 uses Bag-of-Words (BoW) matching to achieve this, but the performance of BoW feature matching decreases when the baseline is large. In contrast, the Lightglue algorithm is well suited for matching with large baselines and integrates seamlessly into the system. By using Lightglue for feature matching and triangulating matching points, a more comprehensive and higher quality map points can be recovered.
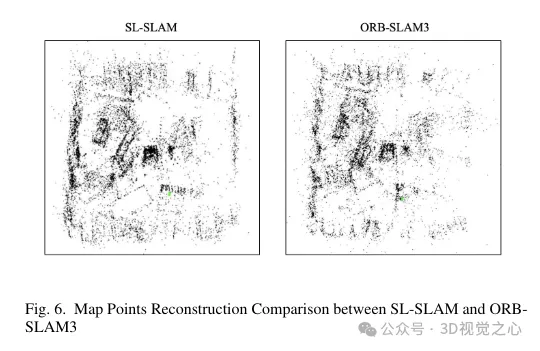
This enhances local mapping capabilities by creating more connections between keyframes and stabilizing tracking by jointly optimizing the pose of jointly visible keyframes and map points. The triangulation effect of map points is shown in Figure 6. It can be observed that compared with ORB-SLAM3, the map points constructed by our method can better reflect the structural information of the scene. Furthermore, they are more evenly and widely distributed in space.
Bag of words depth descriptor: The bag of words method used in loop closure detection is a method based on visual vocabulary, Drawing on the concept of bag of words in natural language processing. It first performs offline training of the dictionary. Initially, the K-means algorithm is used to cluster the detected feature descriptors in the training image set into k sets, forming the first level of the dictionary tree. Subsequently, recursive operations are performed within each set to finally obtain the final dictionary tree with depth L and number of branches k, and establish a visual vocabulary. Each leaf node is considered a vocabulary.
Once the dictionary training is completed, bag-of-word vectors and feature vectors are generated online from all feature points of the current image during algorithm execution. Mainstream SLAM frameworks tend to use manually set binary descriptors because of their small memory footprint and simple comparison methods. In order to further improve the efficiency of the method, SP-Loop uses a Gaussian distribution with an expected value of 0 and a standard deviation of 0.07 to represent the value of the superpoint descriptor. Therefore, the 256-dimensional floating point descriptor of the superpoint can be binary encoded to improve the query speed of visual location recognition. The binary encoding is shown in Equation 4.
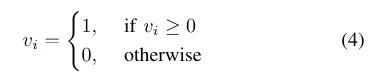
Basic process: Loop closure detection in SLAM usually involves three key stages: finding initial loop closure candidate key frames, verifying loop closure candidate key frames, and Perform closed-loop correction and global Bundle Adjustment (BA).
The first step in the initiation process is to identify initial loop closure candidate keyframes. This is achieved by leveraging the previously trained DBoW3 bag-of-words model. Keyframes that share vocabulary with the current frame Ka are identified, but keyframes that are co-visible with Ka are excluded. Calculate the total score of co-visible keyframes related to these candidate keyframes. From the top N groups with the highest scores among the closed-loop candidate keyframes, select the keyframe with the highest score. This selected keyframe is expressed as Km.
Next, you need to determine the relative posture transformation Tam from Km to the current key frame Ka. In ORB-SLAM3, a bag-of-words based feature matching method is used to match the current key frame with the candidate key frame Km and its co-visible key frame Kco. It is worth noting that since the lightglue algorithm greatly improves the matching efficiency, matching the current frame with the candidate frame Km will produce high-quality map point correspondences. Then, the RANSAC algorithm is applied to eliminate outliers, and the Sim(3) transformation is solved to determine the initial relative attitude Tam. In order to avoid erroneous position identification, candidate keyframes will be geometrically verified, and subsequent steps are similar to ORB-SLAM3.
The above is the detailed content of Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled. For more information, please follow other related articles on the PHP Chinese website!
 How to share a printer between two computers
How to share a printer between two computers
 How to use the groupby function
How to use the groupby function
 Is the higher the computer CPU frequency, the better?
Is the higher the computer CPU frequency, the better?
 What is the interrupt priority?
What is the interrupt priority?
 How to solve access denied
How to solve access denied
 The difference between wlan and wifi
The difference between wlan and wifi
 How to solve invalid synrax
How to solve invalid synrax
 What's going on when phpmyadmin can't access it?
What's going on when phpmyadmin can't access it?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



