


Editor | Cabbage Leaf
Many clinical tasks require understanding of professional data, such as medical images, genomics, etc. This kind of professional knowledge information usually does not exist in the training of general multi-modal large models...
In the description of the previous paper, Med-Gemini surpassed in various medical imaging tasks GPT-4 series models achieve SOTA!
Here, Google DeepMind has written a second paper on Med-Gemini.
Building on Gemini’s multimodal model, the team developed multiple models for the Med-Gemini series. These models inherit the core functionality of Gemini and are optimized for medical use with fine-tuning of 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomics data.
The study was titled "Advancing Multimodal Medical Capabilities of Gemini" and was published on the arXiv preprint platform on May 6, 2024.

Medical data sources include medical data from different sources such as biobanks, electronic health records, medical imaging, wearable devices, biosensors, and genome sequencing. These data are driving the development of multimodal AI solutions to better capture the complexity of population health and disease.
AI in medicine has primarily focused on narrow tasks with single input and output types, but recent advances in generative AI show promise in solving multimodal, multitask challenges in medical settings. .
Multimodal generative artificial intelligence, represented by powerful models such as Gemini, has great potential to revolutionize healthcare. While medicine is a source of data for rapid iteration of these new models, general models often perform poorly when applied in the medical domain due to their highly specialized data.
Based on the core functions of Gemini, DeepMind has launched three new models of the Med-Gemini series, Med-Gemini-2D, Med-Gemini-3D, and Med-Gemini-Polygenic.


More than 7 million data samples from 3.7 million medical images and cases were used to train the model. Various visual question answering and image captioning datasets are used, including some private datasets from hospitals.
To process 3D data (CT), the Gemini video encoder is used, where the temporal dimension is treated as the depth dimension. To process genomic data, risk scores for various traits were encoded as RGB pixels in the image.

Med-Gemini-2D
Med-Gemini-2D AI-based chest X-ray (CXR) report generation based on expert assessment A new standard was developed that surpassed the best results from two previous independent data sets, with absolute advantages of 1% and 12%, with AI reporting 57% and 96% of normal cases and 43% and 65% of abnormal cases, The quality was "comparable" or even "better" than the original radiologist's report.

Graphic: Med-Gemini-2D performance on the chest X-ray classification task. (Source: Paper)
Med-Gemini-2D outperforms the general larger Gemini 1.0 Ultra model on the task of distributed chest X-ray classification (seen on examples from the same dataset during training). For tasks outside the distribution, performance varies.
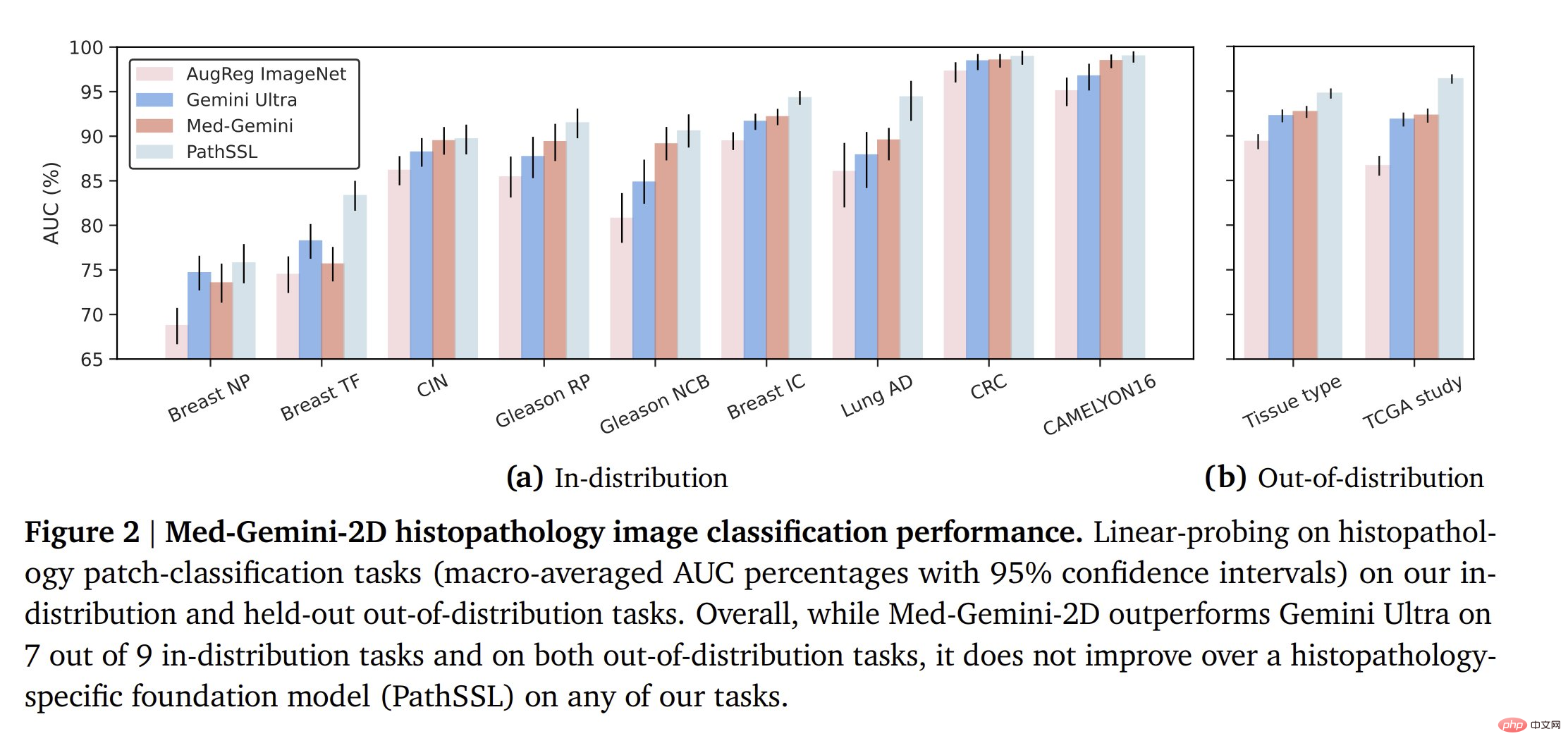
Med-Gemini mostly outperformed Gemini Ultra on histopathology classification tasks, but failed to outperform the pathology-specific base model.

On skin lesion classification, a similar trend is observed (domain-specific model > Med-Gemini > Gemini Ultra), although Med-Gemini is very close to the domain-specific model.

For the ophthalmology classification, a similar situation is seen again. Note that domain-specific models are trained on ~200x more data, so Med-Gemini performs quite well in comparison.

The team also evaluated the Med-Gemini-2D model in medical visual question answering (VQA). Here, their model is very powerful on many VQA tasks, often beating SOTA models. Med-Gemini-2D performed well on CXR classification and radiology VQA, exceeding SOTA or baseline on 17 out of 20 tasks.

Beyond a simple narrow interpretation of medical images, the authors evaluated the performance of Med-Gemini-2D in chest X-ray radiology report generation and observed that it Expert evaluation achieves SOTA!
Med-Gemini-3D

Med-Gemini-3D is not just for 2D images but also for automated end-to-end CT report generation. According to expert assessment, 53% of these AI reports were deemed clinically acceptable, and although additional research is needed to meet the quality of reports from expert radiologists, this is the first generative model capable of this task.
Med-Gemini-Polygenic
Finally, Med-Gemini-Polygenic’s prediction of health outcomes was evaluated based on polygenic risk scores for various traits. The model generally outperforms existing baselines.

Illustration: Health outcome predictions using Med-Gemini-Polygenic compared to two baselines for maldistributed and out-of-distribution outcomes. (Source: Paper)
Here are some examples of multimodal conversations supported by Med-Gemini!

In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpassed the baseline in 18 of 20 tasks and approached task-specific model performance.
Conclusion
Overall, this work has made useful progress on a general multi-modal medical artificial intelligence model, but there is clearly still much room for improvement space. Many domain-specific models outperform Med-Gemini, but Med-Gemini is able to perform well with less data and more general methods. Interestingly, Med-Gemini appears to perform better on tasks that rely more on language understanding, such as VQA or radiology report generation.
The researchers envision a future in which all of these individual functions are integrated into comprehensive systems to perform a range of complex multidisciplinary clinical tasks. AI works alongside humans to maximize clinical efficacy and improve patient outcomes.
Paper link: https://arxiv.org/abs/2405.03162
Related content: https://twitter.com/iScienceLuvr/status/ 1789216212704018469
The above is the detailed content of Multimodal AI is the future of medicine. Google launches three new models, and Med-Gemini welcomes a major upgrade. For more information, please follow other related articles on the PHP Chinese website!
 Mechanical energy conservation law formula
Mechanical energy conservation law formula
 what is dandelion
what is dandelion
 The function of intermediate relay
The function of intermediate relay
 How to pay with WeChat on Douyin
How to pay with WeChat on Douyin
 All uses of cloud servers
All uses of cloud servers
 How to apply for a business email
How to apply for a business email
 Can Douyin short videos be restored after being deleted?
Can Douyin short videos be restored after being deleted?
 formatter function usage
formatter function usage
 How to use months_between in SQL
How to use months_between in SQL








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



