

Hello folks, I am Luga, today we will talk about technologies related to the artificial intelligence (AI) ecological field - LLM evaluation.
As we all know, LLM evaluation is an important issue in the field of artificial intelligence. As LLMs become more widely used in various scenarios, it becomes increasingly important to evaluate their capabilities and limitations. As an emerging LLM assessment tool, ArthurBench aims to provide a comprehensive, fair and repeatable assessment platform for AI researchers and developers.

In recent years, with the rapid development and improvement of large language models (LLM), traditional text evaluation The approach may no longer be applicable in some respects. In the field of text evaluation, we may have heard of some methods, such as "word occurrence" based evaluation methods, such as BLEU, and "pre-trained natural language processing model" based evaluation methods, such as BERTScore. These new evaluation methods allow for a more accurate assessment of the quality and relevance of texts. For example, the BLEU evaluation method evaluates translation quality based on the degree of occurrence of standard words, while the BERTScore evaluation method evaluates the relevance of text based on the ability of a pre-trained natural language processing model to simulate natural language sentence processing. These new assessment methods solve some of the problems of traditional methods to a certain extent and have higher flexibility and accuracy. However, with the continuous development and improvement of language models, these methods have been very good in the past, but with the continuous development of LLM ecological technology, they are shown to be a bit inadequate and cannot fully meet the current needs. need.
With the rapid development and improvement of LLM, we are facing new challenges and opportunities. The capabilities and performance levels of LLMs continue to increase, making it possible that word occurrence-based evaluation methods such as BLEU may not fully capture the quality and semantic accuracy of LLM-generated text. LLM produces more fluid, coherent, and semantically rich text, benefits that traditional word occurrence-based assessment methods fail to accurately measure.
Evaluation methods for pre-trained models (such as BERTScore) may face some challenges when dealing with specific tasks. Although pre-trained models perform well on many tasks, they may not fully take into account the unique characteristics of LLM and its performance on specific tasks. Therefore, relying solely on evaluation methods based on pre-trained models may not fully evaluate the capabilities of LLM.
2. Why is LLM guidance assessment required? And what challenges does it bring?
1. Efficient
2. Sensitive Sex
As we discussed earlier, LLM evaluators are more sensitive than other evaluation methods. There are many different ways to configure LLM as an evaluator, and its behavior can vary greatly depending on the configuration chosen. Meanwhile, another challenge is that LLM evaluators can get stuck if the evaluation involves too many inferential steps or requires processing too many variables simultaneously.
Due to the characteristics of LLM, its evaluation results may be affected by different configurations and parameter settings. This means that when evaluating LLMs, the model needs to be carefully selected and configured to ensure that it behaves as expected. Different configurations may lead to different output results, so the evaluator needs to spend some time and effort to adjust and optimize the settings of the LLM to obtain accurate and reliable evaluation results.
Additionally, evaluators may face some challenges when faced with evaluation tasks that require complex reasoning or the simultaneous processing of multiple variables. This is because the reasoning ability of LLM may be limited when dealing with complex situations. The LLM may require additional effort to address these tasks to ensure the accuracy and reliability of the assessment.
Arthur Bench is an open source evaluation tool used to compare the performance of generative text models (LLM). It can be used to evaluate different LLM models, cues, and hyperparameters and provide detailed reports on LLM performance on various tasks.
The main functions of Arthur Bench include:
Generally speaking, the Arthur Bench workflow mainly involves the following stages, and the detailed analysis is as follows:
At this stage, we need to clarify our assessment goals. Arthur Bench supports a variety of assessment tasks, including:
At this stage, the main work is to select the evaluation objects. Arthur Bench supports a variety of LLM models, covering leading technologies from well-known institutions such as OpenAI, Google AI, Microsoft, etc., such as GPT-3, LaMDA, Megatron-Turing NLG, etc. We can select specific models for evaluation based on research needs.
After completing the model selection, proceed to fine-tuning. To more accurately evaluate LLM performance, Arthur Bench allows users to configure hints and hyperparameters.
Through refined configuration, we can deeply explore the performance differences of LLM under different parameter settings and obtain evaluation results with more reference value.
The last step is to conduct task evaluation with the help of automated processes. Typically, Arthur Bench provides an automated assessment process that requires simple configuration to run assessment tasks. It will automatically perform the following steps:
As the key to a fast, data-driven LLM evaluation, Arthur Bench mainly provides the following solutions, specifically involving:
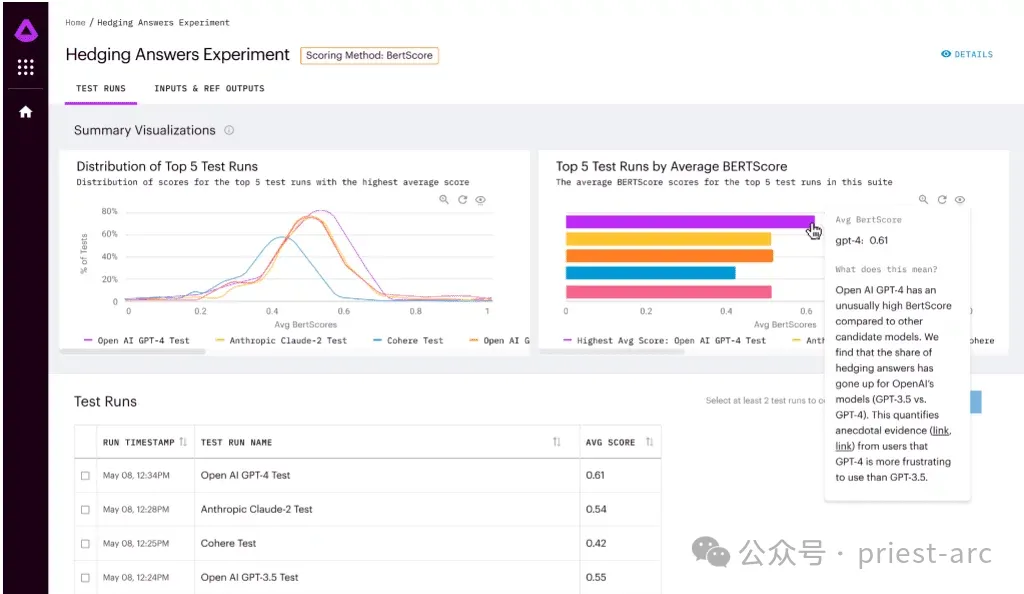
Model selection and verification are crucial steps in the field of artificial intelligence and are of great significance to ensure the validity and reliability of the model. In this process, Arthur Bench's role was crucial. His goal is to provide companies with a reliable comparison framework to help them make informed decisions among the many large language model (LLM) options through the use of consistent metrics and evaluation methods.
Arthur Bench will use his expertise and experience to evaluate each LLM option and ensure that consistent metrics are used to compare their strengths and weaknesses. He will consider factors such as model performance, accuracy, speed, resource requirements and more to ensure companies can make informed and clear choices.
By using consistent metrics and evaluation methodologies, Arthur Bench will provide companies with a reliable comparison framework, allowing them to fully evaluate the benefits and limitations of each LLM option. This will enable companies to make informed decisions to maximize the rapid advances in artificial intelligence and ensure the best possible experience with their applications.
When choosing an artificial intelligence model, not all applications require the most advanced or expensive large language models (LLM). In some cases, mission needs can be met using less expensive AI models.
This approach to budget optimization can help companies make wise choices with limited resources. Instead of going for the most expensive or state-of-the-art model, choose the right one based on your specific needs. The more affordable models may perform slightly worse than state-of-the-art LLMs in some aspects, but for some simple or standard tasks, Arthur Bench can still provide a solution that meets the needs.
Additionally, Arthur Bench emphasized that bringing the model in-house allows for greater control over data privacy. For applications involving sensitive data or privacy issues, companies may prefer to use their own internally trained models rather than relying on external, third-party LLMs. By using internal models, companies can gain greater control over the processing and storage of data and better protect data privacy.
Academic benchmarks refer to model evaluation indicators and methods established in academic research. These indicators and methods are usually specific to a specific task or domain and can effectively evaluate the performance of the model in that task or domain.
However, academic benchmarks do not always directly reflect the performance of models in the real world. This is because application scenarios in the real world are often more complex and require more factors to be considered, such as data distribution, model deployment environment, etc.
Arthur Bench helps translate academic benchmarks into real-world performance. It achieves this goal in the following ways:
As the key to a fast, data-driven LLM assessment, Arthur Bench has the following features:
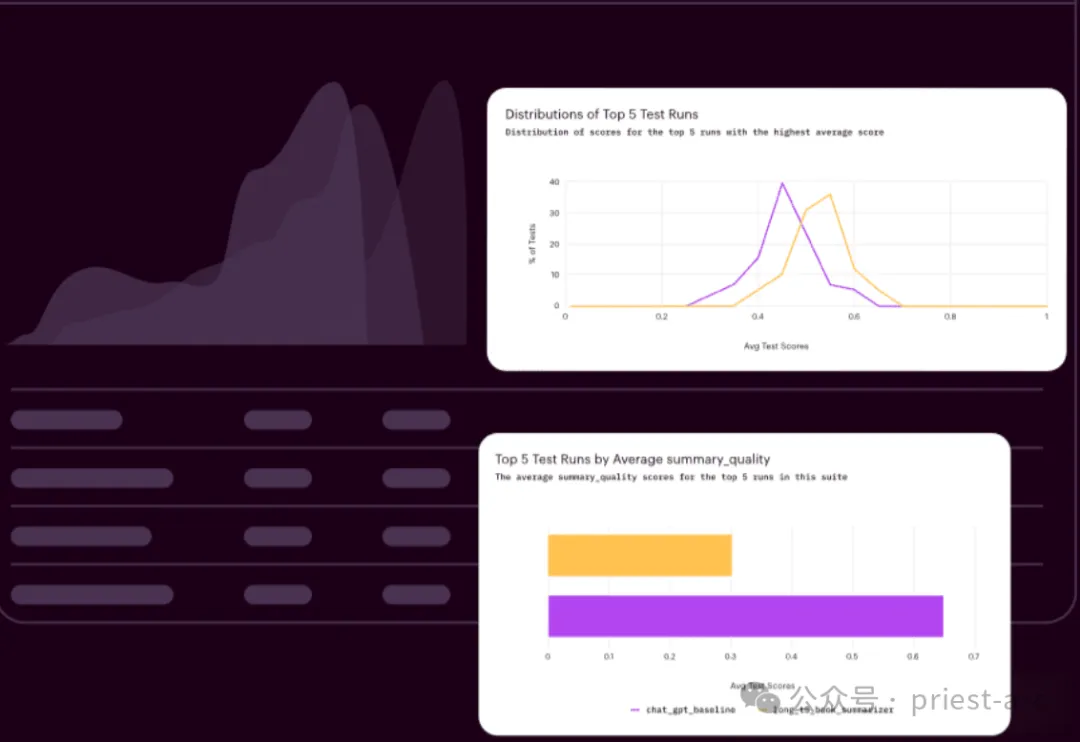
Arthur Bench has a comprehensive set of scoring metrics covering everything from summary quality to user experience. He can use these scoring metrics at any time to evaluate and compare different models. The combined use of these scoring metrics can help him fully understand the strengths and weaknesses of each model.
The scope of these scoring indicators is very wide, including but not limited to summary quality, accuracy, fluency, grammatical correctness, context understanding ability, logical coherence, etc. Arthur Bench will evaluate each model against these metrics and combine the results into a comprehensive score to assist companies in making informed decisions.
In addition, if the company has specific needs or concerns, Arthur Bench can also create and add custom scoring metrics based on the company's requirements. This is done to better meet the company's specific needs and ensure that the assessment process is consistent with the company's goals and standards.
For those who prefer local deployment and autonomous control, you can get access from the GitHub repository permissions and deploy Arthur Bench to your local environment. In this way, everyone can fully master and control the operation of Arthur Bench and customize and configure it according to their own needs.
On the other hand, for those users who prefer convenience and flexibility, cloud-based SaaS products are also available. You can choose to register to access and use Arthur Bench through the cloud. This method eliminates the need for cumbersome local installation and configuration, and enables you to enjoy the provided functions and services immediately.
As an open source project, Arthur Bench shows its typical open source characteristics in terms of transparency, scalability and community collaboration. This open source nature provides users with a wealth of advantages and opportunities to gain a deeper understanding of how the project works, and to customize and extend it to suit their needs. At the same time, the openness of Arthur Bench also encourages users to actively participate in community collaboration, collaborate and develop with other users. This open cooperation model helps promote the continuous development and innovation of the project, while also creating greater value and opportunities for users.
In short, Arthur Bench provides an open and flexible framework that enables users to customize evaluation indicators, and has been widely used in the financial field. Partnerships with Amazon Web Services and Cohere further advance the framework, encouraging developers to create new metrics for Bench and contribute to advances in the field of language model evaluation.
Reference:
The above is the detailed content of Understand the Arthur Bench LLM evaluation framework in one article. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 Three methods of gpu virtualization
Three methods of gpu virtualization
 Introduction to SSL detection tools
Introduction to SSL detection tools
 What types of css selectors are there?
What types of css selectors are there?
 prtscr key function
prtscr key function
 How to cancel automatic renewal at Station B
How to cancel automatic renewal at Station B
 Formal digital currency trading platform
Formal digital currency trading platform








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



