
 Technology peripherals
AI
Multi-grid redundant bounding box annotation for accurate object detection
Technology peripherals
AI
Multi-grid redundant bounding box annotation for accurate object detection
Multi-grid redundant bounding box annotation for accurate object detection

1. Introduction
Currently leading object detectors are two-stage or single-stage networks based on repurposed backbone classifier networks of deep CNNs. YOLOv3 is one such well-known state-of-the-art single-stage detector that receives an input image and divides it into an equal-sized grid matrix. Grid cells with target centers are responsible for detecting specific targets.
What I shared today is to propose a new mathematical method, which provides a solution for each goal Allocate multiple grids for accurate tight-fit bounding box predictions. The researchers also proposed an effective offline copy-paste data enhancement for target detection. The newly proposed method significantly outperforms some current state-of-the-art object detectors and promises better performance.
2. Background
Object detection networks aim to locate objects on images and accurately label them using precision matching bounding boxes. Recently, there have been two different ways to achieve this. The first method is in terms of performance. The most important method is two-stage object detection. The best representative is regional convolutional neural network (RCNN) and its derivatives [Faster R-CNN: Towards real-time object detection with region proposal] networks], [Fast R-CNN]. In contrast, the second group of object detection implementations are known for their excellent detection speed and lightweight, and are called single-stage networks. A representative example is [You only look once: Unified, real-time object detection], [SSD: Single shot multibox detector], [Focal loss for dense object detection]. The two-stage network relies on a latent region proposal network that generates candidate regions of the image that may contain objects of interest. The candidate regions generated by this network can contain the object's region of interest. In single-stage object detection, detection is handled simultaneously with classification and localization in a complete forward pass. Therefore, single-stage networks are typically lighter, faster, and easier to implement.

Today’s research still adheres to the YOLO method, especially YOLOv3, and proposes a simple hack that can use multiple networks at the same time Cell elements predict target coordinates, categories, and target confidence. The rationale behind multi-network unit elements per object is to increase the likelihood of predicting closely fitting bounding boxes by forcing multiple unit elements to work on the same object.

Some advantages of multi-grid allocation include:
The object detector provides the Multi-view maps of objects, rather than relying solely on one grid cell to predict the object's category and coordinates.
(b) Less random and uncertain bounding box predictions, which means high precision and recall because nearby network units are trained to predict the same object category and coordinates ;
(c) Reduce the imbalance between grid cells with objects of interest and grids without objects of interest.
Furthermore, since multi-grid allocation is a mathematical utilization of existing parameters, and no additional keypoint pooling layer and post-processing are required to recombine keypoints to their corresponding For targets such as CenterNet and CornerNet, it can be said that it is a more natural way to achieve what anchor-free or keypoint-based object detectors are trying to achieve. In addition to multi-grid redundant annotations, the researchers also introduced a new offline copy-paste based data enhancement technology for accurate object detection.
3. MULTI-GRID ASSIGNMENT

The above picture contains three targets, namely dogs and bicycles and cars. For the sake of brevity, we will explain our multi-grid assignment on one object. The image above shows the bounding boxes of three objects, with more detail on the dog's bounding box. The image below shows a zoomed-out area of the image above, focusing on the center of the dog's bounding box. The top-left coordinate of the grid cell containing the center of the dog's bounding box is labeled with the number 0, while the other eight grid cells surrounding the grid containing the center have labels from 1 to 8.

So far I have explained the basic facts of how a grid containing the center of an object's bounding box annotates an object. This reliance on only one grid cell per object to do the difficult job of predicting categories and precise tight-fit bounding boxes raises many questions, such as:
(a) Huge imbalance between positive and negative grids, i.e. grid coordinates with and without object center
(b) Slow bounding box convergence to GT
(c) Lack of multi-perspective (angle) views of the object to be predicted.
So a natural question to ask here is, "Obviously, most objects contain areas of more than one grid cell, so is there a simple mathematical way to allocate more of these grid cell to try to predict the object's category and coordinates along with the center grid cell?" Some advantages of this are (a) reduced imbalance, (b) faster training to converge to bounding boxes since now multiple grid cells target the same object simultaneously, (c) increased prediction of tight-fit bounding boxes Opportunity (d) provides grid-based detectors such as YOLOv3 with multi-view views instead of single-point views of objects. The newly proposed multigrid allocation attempts to answer the above questions.
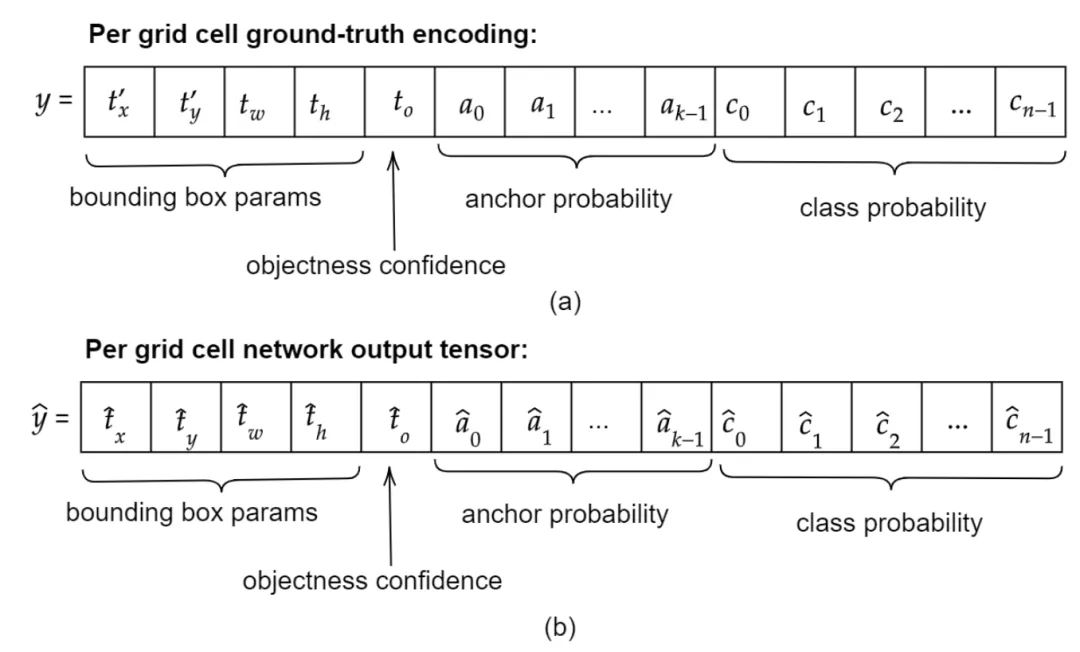
Ground-truth encoding
##4. Training
A. The Detection Network: MultiGridDet
MultiGridDet is an object detection network made lighter by removing six darknet convolution blocks from YOLOv3 , faster. A convolution block has a Conv2D Batch Normalization LeakyRelu. The removed blocks are not from the classification backbone, i.e. Darknet53. Instead, remove them from three multiscale detection output networks or heads, two from each output network. Although deep networks generally perform well, networks that are too deep also tend to quickly overfit or significantly slow down the network.
B. The Loss function
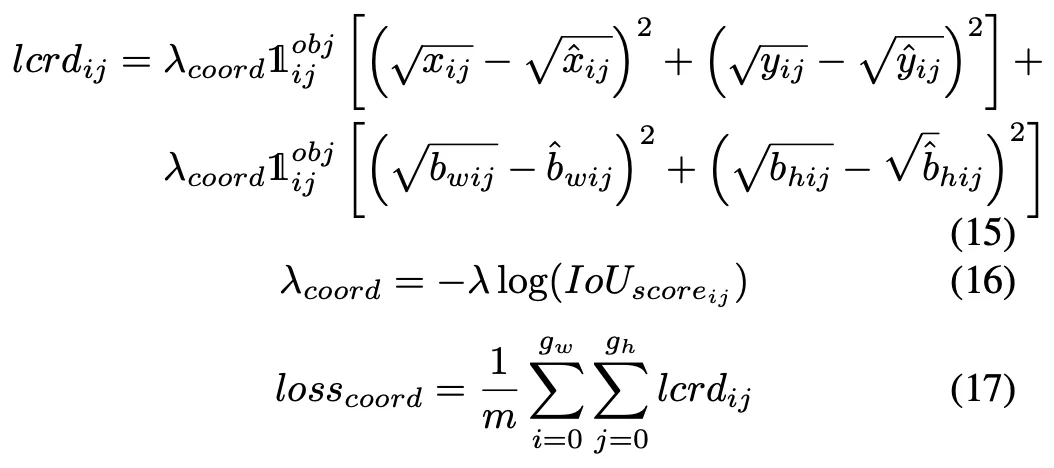
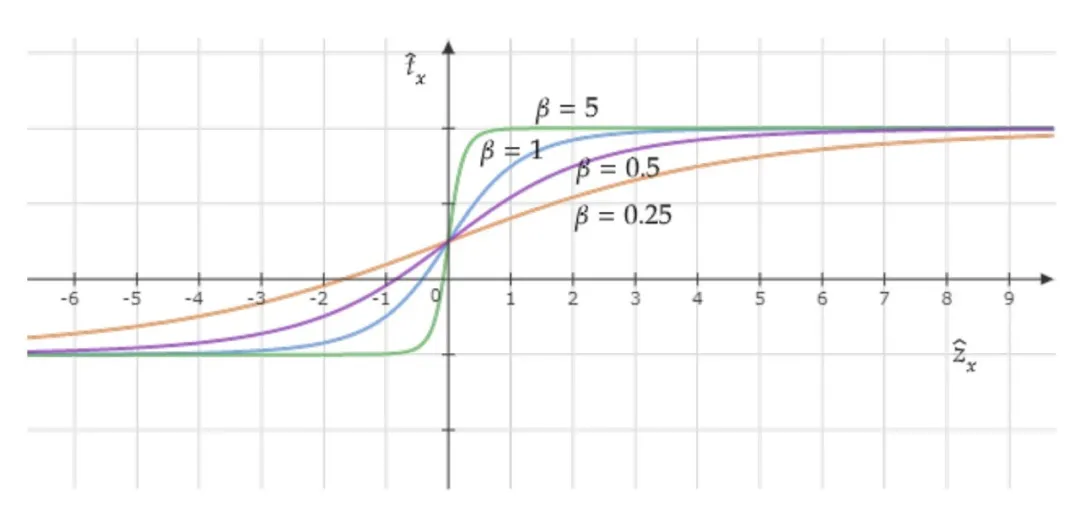
C. Data Augmentation
Offline copy-paste manual training image synthesis works as follows: First, use a simple image search Script that downloads thousands of background object-free images from Google Images using keywords such as landmark, rain, forest, etc., i.e. images without the object of our interest. We then iteratively select p objects and their bounding boxes from random q images of the entire training dataset. We then generate all possible combinations of p bounding boxes selected using their indices as IDs. From the combined set, we select a subset of bounding boxes that satisfy the following two conditions:
- if arranged in some random order side by side, they must fit within a given target background image area
- ##and should efficiently utilize the background image space in its entirety or at least most part of it without the objects overlap.
- ##5. Experiment and visualization
Performance comparison on Pascal VOC 2007


 ##As can be seen from the figure, The first row shows the six input images, while the second row shows the network’s predictions before non-maximal suppression (NMS), and the last row shows MultiGridDet’s final bounding box predictions for the input images after NMS.
##As can be seen from the figure, The first row shows the six input images, while the second row shows the network’s predictions before non-maximal suppression (NMS), and the last row shows MultiGridDet’s final bounding box predictions for the input images after NMS.

The above is the detailed content of Multi-grid redundant bounding box annotation for accurate object detection. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 New SOTA for target detection: YOLOv9 comes out, and the new architecture brings traditional convolution back to life
Feb 23, 2024 pm 12:49 PM
New SOTA for target detection: YOLOv9 comes out, and the new architecture brings traditional convolution back to life
Feb 23, 2024 pm 12:49 PM
In the field of target detection, YOLOv9 continues to make progress in the implementation process. By adopting new architecture and methods, it effectively improves the parameter utilization of traditional convolution, which makes its performance far superior to previous generation products. More than a year after YOLOv8 was officially released in January 2023, YOLOv9 is finally here! Since Joseph Redmon, Ali Farhadi and others proposed the first-generation YOLO model in 2015, researchers in the field of target detection have updated and iterated it many times. YOLO is a prediction system based on global information of images, and its model performance is continuously enhanced. By continuously improving algorithms and technologies, researchers have achieved remarkable results, making YOLO increasingly powerful in target detection tasks.
 Multi-grid redundant bounding box annotation for accurate object detection
Jun 01, 2024 pm 09:46 PM
Multi-grid redundant bounding box annotation for accurate object detection
Jun 01, 2024 pm 09:46 PM
1. Introduction Currently, the leading object detectors are two-stage or single-stage networks based on the repurposed backbone classifier network of deep CNN. YOLOv3 is one such well-known state-of-the-art single-stage detector that receives an input image and divides it into an equal-sized grid matrix. Grid cells with target centers are responsible for detecting specific targets. What I’m sharing today is a new mathematical method that allocates multiple grids to each target to achieve accurate tight-fit bounding box prediction. The researchers also proposed an effective offline copy-paste data enhancement for target detection. The newly proposed method significantly outperforms some current state-of-the-art object detectors and promises better performance. 2. The background target detection network is designed to use
 Steps to set up camera grid on iPhone
Mar 26, 2024 pm 07:21 PM
Steps to set up camera grid on iPhone
Mar 26, 2024 pm 07:21 PM
1. Open the desktop of your iPhone, find and click to enter [Settings], 2. Click to enter [Camera] on the settings page. 3. Click to turn on the switch on the right side of [Grid].
 How to use C++ for high-performance image tracking and target detection?
Aug 26, 2023 pm 03:25 PM
How to use C++ for high-performance image tracking and target detection?
Aug 26, 2023 pm 03:25 PM
How to use C++ for high-performance image tracking and target detection? Abstract: With the rapid development of artificial intelligence and computer vision technology, image tracking and target detection have become important research areas. This article will introduce how to achieve high-performance image tracking and target detection by using C++ language and some open source libraries, and provide code examples. Introduction: Image tracking and object detection are two important tasks in the field of computer vision. They are widely used in many fields, such as video surveillance, autonomous driving, intelligent transportation systems, etc. for
 Multiple SOTAs! OV-Uni3DETR: Improving the generalizability of 3D detection across categories, scenes and modalities (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Multiple SOTAs! OV-Uni3DETR: Improving the generalizability of 3D detection across categories, scenes and modalities (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
This paper discusses the field of 3D object detection, especially 3D object detection for Open-Vocabulary. In traditional 3D object detection tasks, systems need to predict the localization of 3D bounding boxes and semantic category labels for objects in real scenes, which usually relies on point clouds or RGB images. Although 2D object detection technology performs well due to its ubiquity and speed, relevant research shows that the development of 3D universal detection lags behind in comparison. Currently, most 3D object detection methods still rely on fully supervised learning and are limited by fully annotated data under specific input modes, and can only recognize categories that emerge during training, whether in indoor or outdoor scenes. This paper points out that the challenges facing 3D universal target detection are mainly
 CSS Layout Tips: Best Practices for Implementing Circular Grid Icon Layout
Oct 20, 2023 am 10:46 AM
CSS Layout Tips: Best Practices for Implementing Circular Grid Icon Layout
Oct 20, 2023 am 10:46 AM
CSS Layout Tips: Best Practices for Implementing Circular Grid Icon Layout Grid layout is a common and powerful layout technique in modern web design. The circular grid icon layout is a more unique and interesting design choice. This article will introduce some best practices and specific code examples to help you implement a circular grid icon layout. HTML structure First, we need to set up a container element and place the icon in this container. We can use an unordered list (<ul>) as a container, and the list items (<l
 Computer Vision Example in Python: Object Detection
Jun 10, 2023 am 11:36 AM
Computer Vision Example in Python: Object Detection
Jun 10, 2023 am 11:36 AM
With the development of artificial intelligence, computer vision technology has become one of the focuses of people's attention. As an efficient and easy-to-learn programming language, Python has been widely recognized and promoted in the field of computer vision. This article will focus on a computer vision example in Python: object detection. What is object detection? Object detection is a key technology in the field of computer vision. Its purpose is to identify the location and size of a specific object in a picture or video. Compared with image classification, target detection not only requires identifying images
 The latest deep architecture for target detection has half the parameters and is 3 times faster +
Apr 09, 2023 am 11:41 AM
The latest deep architecture for target detection has half the parameters and is 3 times faster +
Apr 09, 2023 am 11:41 AM
Brief Introduction The study authors propose Matrix Net (xNet), a new deep architecture for object detection. xNets map objects with different size dimensions and aspect ratios into network layers, where the objects are almost uniform in size and aspect ratio within the layer. Therefore, xNets provide a size- and aspect-ratio-aware architecture. Researchers use xNets to enhance keypoint-based target detection. The new architecture achieves higher time-efficiency than any other single-shot detector, with 47.8 mAP on the MS COCO dataset, while using half the parameters and being 3 times faster to train than the next best framework. times. As shown in the simple result display above, xNet’s parameters and efficiency far exceed those of other models.
