

How to solve the long tail problem in autonomous driving scenarios?

Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I wanted to briefly summarize it.
The long-tail problem of self-driving cars refers to edge situations in self-driving cars, that is, possible scenarios with low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior.
Edge Scenarios in Autonomous Driving
The "long tail" refers to the edge situations in autonomous vehicles (AV), which are more likely to occur. Low possible scenario. These rare events are often missed in data sets because they occur less frequently and are more unique. While humans are naturally good at handling edge cases, the same cannot be said for AI. Factors that may cause edge scenes include: trucks or special-shaped vehicles with protrusions, vehicles making sharp turns, driving in crowded crowds, pedestrians jaywalking, extreme weather or poor lighting conditions, people holding umbrellas, people in cars Then moving boxes, trees falling in the middle of the road, etc.Example:
- Put a transparent film in front of the car, will the transparent object be recognized, and will the vehicle slow down?
- Lidar company Aeye has done a challenge, how does autonomous driving deal with a balloon floating in the middle of the road. L4 driverless cars tend to avoid collisions. In this case, they will take evasive actions or apply the brakes to avoid unnecessary accidents. The balloon is a soft object and can pass directly without any obstacles.
Methods to solve the long tail problem
Synthetic data is a big concept, and sensory data (nerf, camera/sensor sim) is just one of the more outstanding ones branch. In the industry, synthetic data has long become the standard answer in longtail behavior sim. Synthetic data, or sparse signal upsampling, is one of the first solutions to the long-tail problem. Long-tail capability is the product of the model’s generalization capability and the amount of information contained in the data.Tesla solution:
Use synthetic data (synthetic data) to generate edge scenes to expand the data setData engine Principle: First, inaccuracies in existing models are detected and subsequently such cases are added to their unit tests. It also collects more data on similar cases to retrain the model. This iterative approach allows it to capture as many edge cases as possible. The main challenge in creating edge cases is that the cost of collecting and labeling edge cases is relatively high, and the other is that the collection behavior may be very dangerous or even impossible to achieve.
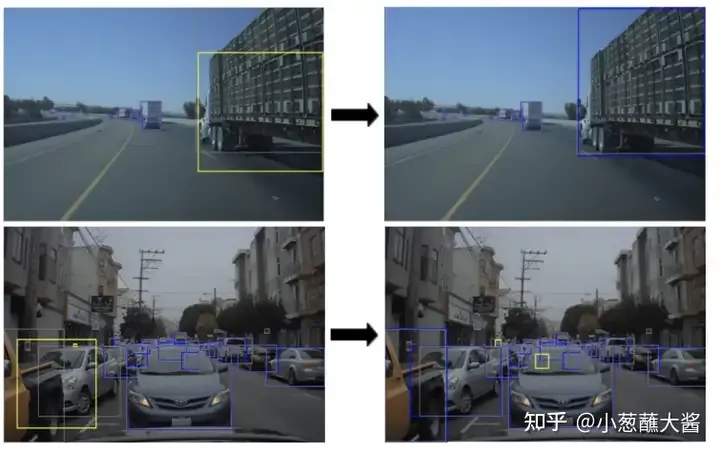
NVIDIA Solution:
NVIDIA recently proposed a strategic approach called "imitation training" (picture below). In this approach, real-world system failure cases are recreated in a simulated environment and then used as training data for autonomous vehicles. This cycle is repeated until the model's performance converges. The goal of this approach is to improve the robustness of the autonomous driving system by continuously simulating fault scenarios. Simulation training allows developers to better understand and resolve different failure scenarios in the real world. In addition, it can quickly generate large amounts of training data to improve model performance. By repeating this cycle,
Some thoughts:
Q: Is synthetic data valuable? A: The value here is divided into two types. The first is test effectiveness, that is, testing whether some deficiencies in the detection algorithm can be found in the generated scenario. The second is training effectiveness, that is, Whether the generated scenarios can effectively improve performance when used for algorithm training. Q: How to use virtual data to improve performance? Is it really necessary to add dummy data to the training set? Will adding it cause a performance regression? A: These questions are difficult to answer, so many different solutions to improve training accuracy have been produced:- Hybrid training: Add different proportions of virtual data to real data to improve performance.
- Transfer Learning: Use real data to pre-train the model, then Freeze certain layers, and then Add mixed data for training.
- Imitation Learning: It is very natural to design some scenarios of model errors and generate some data thereby gradually improving the performance of the model. In actual data collection and model training, some supplementary data are also collected in a targeted manner to improve performance.
Some extensions:
To thoroughly evaluate the robustness of an AI system, unit tests must include both general and edge cases. However, some edge cases may not be available from existing real-world datasets. To do this, AI practitioners can use synthetic data for testing.
One example is ParallelEye-CS, a synthetic dataset used to test the visual intelligence of self-driving cars. The benefit of creating synthetic data compared to using real-world data is the multi-dimensional control over the scene for each image.
Synthetic data will serve as a viable solution for edge cases in production AV models. It supplements real-world data sets with edge cases, ensuring that AV remains robust even under unusual events. It's also more scalable, less error-prone, and cheaper than real-world data.
The above is the detailed content of How to solve the long tail problem in autonomous driving scenarios?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
