

Read GPT-4o vs GPT-4 Turbo in one article

Hello folks, I am Luga. Today we will talk about technologies related to the artificial intelligence (AI) ecological field - the GPT-4o model.
On May 13, 2024, OpenAI innovatively launched its most advanced and cutting-edge model GPT-4o, an initiative that marks a major breakthrough in the field of artificial intelligence chatbots and large-scale language models . Heralding a new era of artificial intelligence capabilities, GPT-4o boasts significant performance enhancements that surpass its predecessor, GPT-4, in both speed and versatility.
This groundbreaking advancement resolves the latency issues that often plagued its predecessor, ensuring a seamless and responsive user experience.

What is GPT-4o?
On May 13, 2024, OpenAI released its latest and most advanced artificial intelligence model GPT-4o, The "o" stands for "omni", which means "all" or "universal". This model is a new generation of large language model based on GPT-4 Turbo. Compared with previous models, GPT-4o has significantly improved in terms of output speed, answer quality, and supported languages, and has made revolutionary innovations in the format of processing input data.
The most noteworthy innovation of the GPT-4o+ model is that it abandons the previous model's practice of using independent neural networks to process different types of input data, and instead uses a single unified neural network to process all inputs. This innovative design gives GPT-4o+ unprecedented multi-modal fusion capabilities. Multimodal fusion refers to integrating different types of input data (such as images, text, audio, etc.) for processing to obtain more comprehensive and accurate results. Previous models needed to design different network structures when processing multi-modal data, which consumed a lot of computing resources and time. By using a unified neural network, GPT-4o+ achieves seamless connection of different types of input data, greatly improving processing efficiency. Traditional language models can usually only handle plain text input and cannot handle speech, Non-text data such as images. However, GPT-4o is unusual in that it can simultaneously detect and parse non-text signals such as background noise, multiple sound sources, and emotional colors in speech input, and fuse these multi-modal information into the semantic understanding and generation process to produce Richer, more contextual output.
In addition to processing multi-modal input, GPT-4o+ also demonstrates excellent excellent output capabilities when generating multi-lingual output. Not only does it output higher quality, more grammatically correct, and more concise expressions in mainstream languages such as English, but GPT-4o+ can also maintain the same level of output in non-English language scenarios. This ensures that both English and other language users can enjoy GPT-4o+’s superior natural language generation capabilities.
In general, the biggest highlight of GPT-4o+ is that it breaks through the limitations of a single modality and achieves cross-modal comprehensive understanding and generation capabilities. With the help of innovative neural network architecture and training mechanism, GPT-4o+ can not only obtain information from multiple sensory channels, but also integrate it during generation to produce a more contextual and more personalized response.
GPT-4o and GPT-4 Turbo performance?
GPT-4 is the latest multi-modal large model launched by OpenAI. Compared with the previous generation GPT-4 Turbo, its performance is Great progress. Here we can conduct a comparative analysis of the two in the following key aspects. First, there is a difference in model size between GPT-4 and GPT-4 Turbo. GPT-4 has a larger number of parameters than GPT-4 Turbo, which means it can handle more complex tasks and larger data sets. This enables GPT-4 to have higher accuracy and fluency in semantic understanding, text generation, etc. Its
1. Inference speed
According to data published by OpenAI, under the same hardware conditions, the inference speed of GPT-4o is twice that of GPT-4 Turbo. This significant performance improvement is mainly attributed to its innovative single-model architecture, which avoids the efficiency loss caused by mode switching. The single-model architecture not only simplifies the calculation process but also significantly reduces resource overhead, allowing GPT-4o to process requests faster. Higher inference speed means that GPT-4o can provide users with responses with lower latency, significantly improving the interactive experience. Whether in real-time conversations, complex task processing, or applications in high-concurrency environments, users can experience smoother and more immediate service responses. This performance optimization not only improves the overall efficiency of the system, but also provides more reliable and efficient support for various application scenarios.
 GPT-4o and GPT-4 Turbo latency comparison
GPT-4o and GPT-4 Turbo latency comparison
2. Throughput
As we all know, the early GPT model had poor performance in throughput Performance is a bit lagging behind. For example, the latest GPT-4 Turbo can only generate 20 tokens per second. However, GPT-4o has made a major breakthrough in this regard, being able to generate 109 tokens per second. This improvement has significantly improved the processing speed of GPT-4o, providing higher efficiency for various application scenarios.
Despite this, GPT-4o is still not the fastest model. Taking Llama hosted on Groq as an example, it can generate 280 tokens per second, far exceeding GPT-4o. However, GPT-4o’s advantages go beyond speed. Its advanced functionality and reasoning capabilities make it stand out in real-time AI applications. GPT-4o's single model architecture and optimization algorithm not only improve computing efficiency, but also significantly reduce response time, giving it unique advantages in interactive experience.

GPT-4o and GPT-4 Turbo throughput comparison
Comparative analysis in different scenarios
Generally speaking, GPT- When 4o and GPT-4 Turbo handle different types of tasks, there are obvious differences in performance due to differences in architecture and modal fusion capabilities. Here, we mainly analyze the differences between the two from three representative task types: data extraction, classification and reasoning.
1. Data extraction
In text data extraction tasks, GPT-4 Turbo relies on its powerful natural language understanding capabilities to achieve good performance. But when encountering scenes containing unstructured data such as images and tables, its capabilities become somewhat limited.
In contrast, GPT-4o can seamlessly integrate data of different modalities. Whether it is in structured text or unstructured data such as images and PDFs, it can efficiently identify and Extract the required information. This advantage makes GPT-4o more competitive when processing complex mixed data.
Here, we take the contract scenario of a certain company as an example. The data set includes the master service agreement (MSA) between the company and the customer. Contracts vary in length, with some being as short as 5 pages and some being longer than 50 pages.
In this evaluation, we will extract a total of 12 fields, such as contract title, customer name, supplier name, details of termination clause, whether there is force majeure, etc. Through real data collection on 10 contracts, 12 custom evaluation indicators were set up using. These metrics are used to compare our real data to the LLM output for each parameter in the JSON generated by the model. Subsequently, we tested GPT-4 Turbo and GPT-4o. The following are the results of our evaluation report:

Evaluation based on the 12 indicators corresponding to each prompt Results
In the above comparison results, we can conclude that among these 12 fields, GPT-4o performs better than GPT-4 Turbo in 6 fields, and the results are the same in 5 fields. The performance dropped slightly in 1 field.
From an absolute perspective, GPT-4 and GPT-4o only correctly identify 60-80% of the data in most fields. Both models performed subpar in complex data extraction tasks that require high accuracy. Better results can be achieved by using advanced prompting techniques such as shot prompts or chain thought prompts.
Additionally, GPT-4o is 50-80% faster than GPT-4 Turbo in TTFT (time to first token), which gives GPT-4o an advantage in direct comparisons. The final conclusion is that GPT-4o outperforms GPT-4 Turbo due to its higher quality and lower latency.
2. Classification
Classification tasks often require extracting features from multi-modal information such as text and images, and then performing semantic-level understanding and judgment. At this point, since GPT-4 Turbo is limited to processing only a single text modality, its classification capabilities are relatively limited.
GPT-4o can fuse multi-modal information to form a more comprehensive semantic representation, thus showing excellent classification capabilities in fields such as text classification, image classification, and sentiment analysis, especially in some high-level applications. Difficulty in cross-modal classification scenarios.
In our tips, we provide clear instructions on when customer tickets are closed and add several examples to help resolve the most difficult cases.
By running the evaluation to test whether the model's output matches the ground truth data for 100 labeled test cases, here are the relevant results:
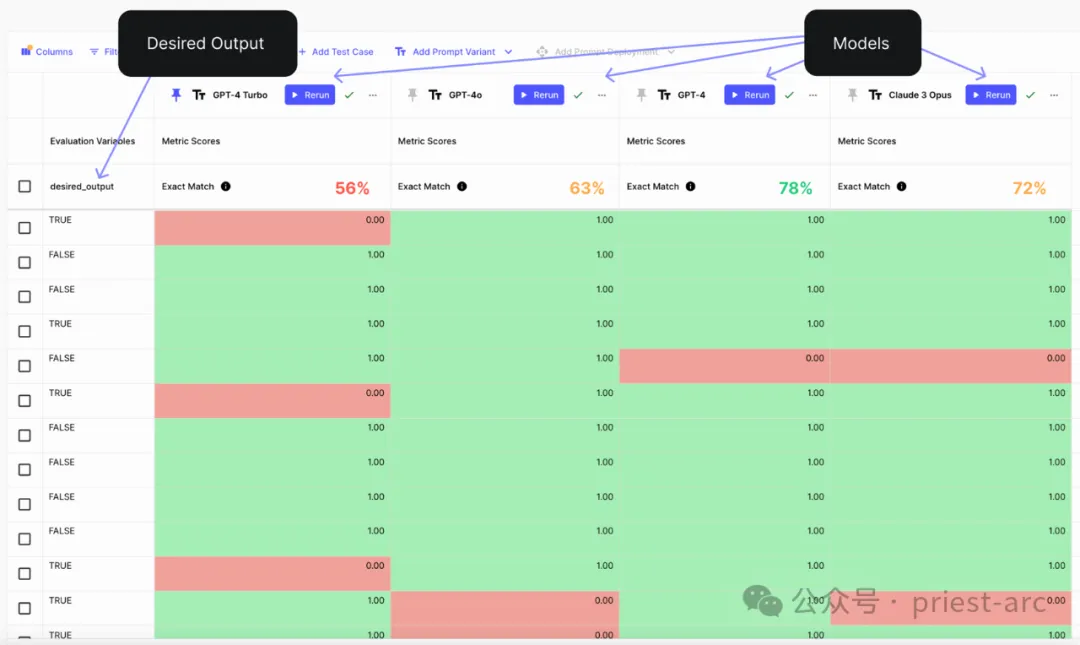
Classification analysis and evaluation reference
GPT-4o undoubtedly shows overwhelming advantages. Through a series of tests and comparisons on various complex tasks, we can see that GPT-4o far exceeds other competing models in overall accuracy, making it the first choice in many application fields.
However, while leaning towards GPT-4o as a general solution, we also need to keep in mind that choosing the best AI model is not an overnight decision-making process. After all, the performance of AI models often depends on specific application scenarios and trade-off preferences for different indicators such as precision, recall, and time efficiency.
3. Reasoning
Reasoning is a high-order cognitive ability of artificial intelligence systems, which requires the model to deduce reasonable conclusions from given preconditions. This is crucial for tasks such as logical reasoning and question and answer reasoning.
GPT-4 Turbo has performed well on text reasoning tasks, but its capabilities are limited when encountering situations that require multi-modal information fusion.
GPT-4o does not have this limitation. It can freely integrate semantic information from multiple modalities such as text, images, and speech, and perform more complex logical reasoning, causal reasoning, and inductive reasoning on this basis, thus giving the artificial intelligence system more "humanized" reasoning and judgment capabilities. .
Still based on the above scenario, let’s take a look at the comparison between the two at the inference level. For details, please refer to the following:

16 inference tasks Evaluation reference
According to the sample test of the GPT-4o model, we can observe that it performs increasingly better in the following inference tasks, as follows:
- Calendar calculation: GPT -4o is able to accurately identify when a specific date repeats, which means it can handle date-related calculations and reasoning.
- Time and angle calculation: GPT-4o is able to accurately calculate angles on clocks, which is very useful when dealing with clock and angle related problems.
- Vocabulary (Antonym Recognition): GPT-4o can effectively identify antonyms and understand the meaning of words, which is very important for semantic understanding and lexical reasoning.
Although GPT-4o performs increasingly better in certain reasoning tasks, it still faces challenges in tasks such as word manipulation, pattern recognition, analogical reasoning, and spatial reasoning. Future improvements and optimizations may further improve the model's performance in these areas.
To sum up, GPT-4o, which is based on a rate limit of up to 10 million tokens per minute, is a full 5 times that of GPT-4. This exciting performance indicator will undoubtedly accelerate the popularization of artificial intelligence in many intensive computing scenarios, especially in fields such as real-time video analysis and intelligent voice interaction. GPT-4o's high concurrency response capability will show unrivaled advantages .
The most shining innovation of GPT-4o is undoubtedly its revolutionary design that seamlessly integrates text, image, voice and other multi-modal input and output. By directly integrating and processing data from each modality through a single neural network, GPT-4o fundamentally solves the fragmented experience of switching between previous models, paving the way for building unified AI applications.
After realizing modal fusion, GPT-4o will have unprecedented broad prospects in application scenarios. Whether it is combining computer vision technology to create intelligent image analysis tools, seamlessly integrating with speech recognition frameworks to create multi-modal virtual assistants, or generating high-fidelity graphic advertisements based on text and image dual-modality, everything could only be achieved by integrating independent sub-models. The completed tasks, driven by the great intelligence of GPT-4o, will have new unified and efficient solutions.
Reference:
- [1] https://openai.com/index/hello-gpt-4o/?ref=blog.roboflow.com
- [2] https://blog.roboflow.com/gpt-4-vision/
- [3] https://www.vellum.ai/blog/analysis-gpt-4o-vs-gpt- 4-turbo#task1
The above is the detailed content of Read GPT-4o vs GPT-4 Turbo in one article. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
 Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
According to news from this website on July 5, GlobalFoundries issued a press release on July 1 this year, announcing the acquisition of Tagore Technology’s power gallium nitride (GaN) technology and intellectual property portfolio, hoping to expand its market share in automobiles and the Internet of Things. and artificial intelligence data center application areas to explore higher efficiency and better performance. As technologies such as generative AI continue to develop in the digital world, gallium nitride (GaN) has become a key solution for sustainable and efficient power management, especially in data centers. This website quoted the official announcement that during this acquisition, Tagore Technology’s engineering team will join GLOBALFOUNDRIES to further develop gallium nitride technology. G
