
 Technology peripherals
AI
ICML 2024 | The new frontier of large language model pre-training: 'Best Adaptation Packaging' reshapes document processing standards
Technology peripherals
AI
ICML 2024 | The new frontier of large language model pre-training: 'Best Adaptation Packaging' reshapes document processing standards
ICML 2024 | The new frontier of large language model pre-training: 'Best Adaptation Packaging' reshapes document processing standards
Jun 02, 2024 pm 09:42 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

- Figure 2 (a): In Python programming, although the original code is correct, splitting the definition and use of variables into different training sequences will introduce syntax errors, causing some variables to be undefined in subsequent training sequences, causing the model to learn errors patterns and may produce hallucinations in downstream tasks. For example, in program synthesis tasks, a model may use variables directly without defining them.
- Figure 2(b): Truncation also damages the integrity of the information. For example, "Monday morning" in the summary cannot match any context in the training sequence, resulting in inaccurate content. This kind of incomplete information will significantly reduce the sensitivity of the model to contextual information, causing the generated content to be inconsistent with the actual situation, which is the so-called unfaithful generation.
- Figure 2(c): Truncation also hinders knowledge acquisition during training, because the representation of knowledge in text often relies on complete sentences or paragraphs. For example, the model cannot learn the location of the ICML conference because the conference name and location are distributed in different training sequences.
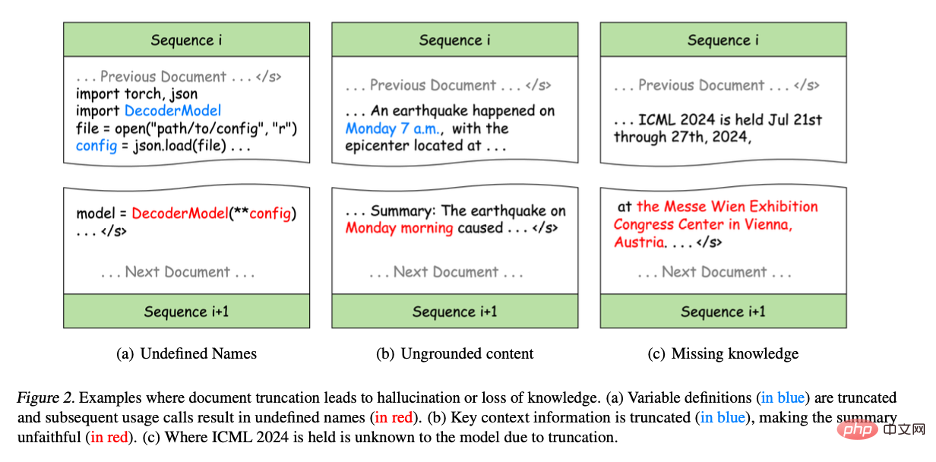
Figure 2. Example of document truncation leading to illusion or loss of knowledge.
(a) The variable definition (blue part) is truncated and subsequent usage calls result in an undefined name (red part).
(b) Key contextual information is truncated (blue part), making the summary less accurate than the original text (red part).
(c) Due to truncation, the model does not know where ICML 2024 will be held.



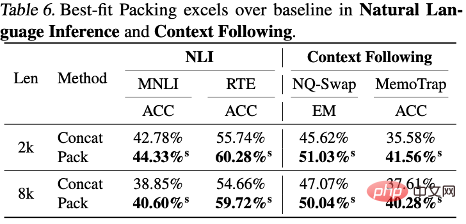

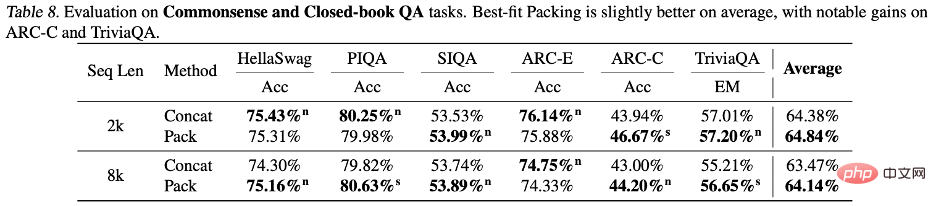
##
In contrast, uncommon
By analyzing the results of the two test sets ARC-C and ARC-E, the researchers found that compared to ARC-E, which contains more common knowledge, using Optimal fit packaging will result in a more significant performance improvement in the model in ARC-C, which contains more tail knowledge.
This finding was further verified by counting the number of co-occurrences of each question-answer pair in Kandpal et al. (2023) preprocessed Wikipedia entity map . Statistical results show that the challenge set (ARC-C) contains more rare co-occurring pairs, which verifies the hypothesis that optimal adaptation packaging can effectively support tail knowledge learning, and also explains why traditional large language models are unable to learn long-tail knowledge. provides an explanation for the difficulties encountered.
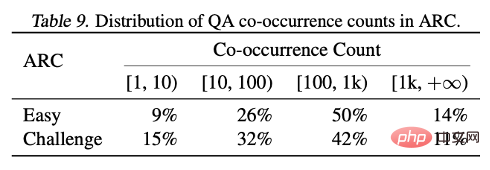
##This article proposes large-scale language model training Common document truncation problem.
The above is the detailed content of ICML 2024 | The new frontier of large language model pre-training: 'Best Adaptation Packaging' reshapes document processing standards. For more information, please follow other related articles on the PHP Chinese website!

Hot Article

Hot tools Tags

Hot Article

Hot Article Tags

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
 Unlimited video generation, planning and decision-making, diffusion forced integration of next token prediction and full sequence diffusion
Jul 23, 2024 pm 02:05 PM
Unlimited video generation, planning and decision-making, diffusion forced integration of next token prediction and full sequence diffusion
Jul 23, 2024 pm 02:05 PM
Unlimited video generation, planning and decision-making, diffusion forced integration of next token prediction and full sequence diffusion
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
 Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
