
 Technology peripherals
AI
NVIDIA's new research: The context length is seriously false, and not many 32K performance is qualified
Technology peripherals
AI
NVIDIA's new research: The context length is seriously false, and not many 32K performance is qualified
NVIDIA's new research: The context length is seriously false, and not many 32K performance is qualified

Ruthlessly exposes the false standard phenomenon of "long context" large models -
NVIDIA's new research found that 10 large models, including GPT-4, generate context lengths of 128k or even 1M All are available.
But after some testing, the new indicator "effective context" has shrunk seriously, and not many can reach 32K.
The new benchmark is named RULER, which includes a total of 13 tasks in four categories: retrieval, multi-hop tracking, aggregation, and question and answer. RULER defines the "effective context length", which is the maximum length at which the model can maintain the same performance as the Llama-7B baseline at 4K length.

The study was rated as "very insightful" by academics.

After seeing this new research, many netizens also wanted to see the results of the challenge of the context length king players Claude and Gemini. (Not covered in the paper)


Let’s take a look at how NVIDIA defines the “effective context” indicator.

The test tasks are more and more difficult
To evaluate the long text understanding ability of large models, you must first choose a good standard, which is currently popular in the circle ZeroSCROLLS, L-Eval, LongBench, InfiniteBench, etc. either only evaluate the model retrieval ability, or are limited by the interference of prior knowledge.
So the RULER method eliminated by NVIDIA can be summarized in one sentence as"Ensure that the evaluation focuses on the model's ability to process and understand long context, rather than the ability to recall information from the training data".
RULER's evaluation data reduces the reliance on "parameterized knowledge", that is, the knowledge that the large model has encoded into its own parameters during the training process.
Specifically, the RULER benchmark extends the popular “needle in a haystack” test by adding four new categories of tasks.
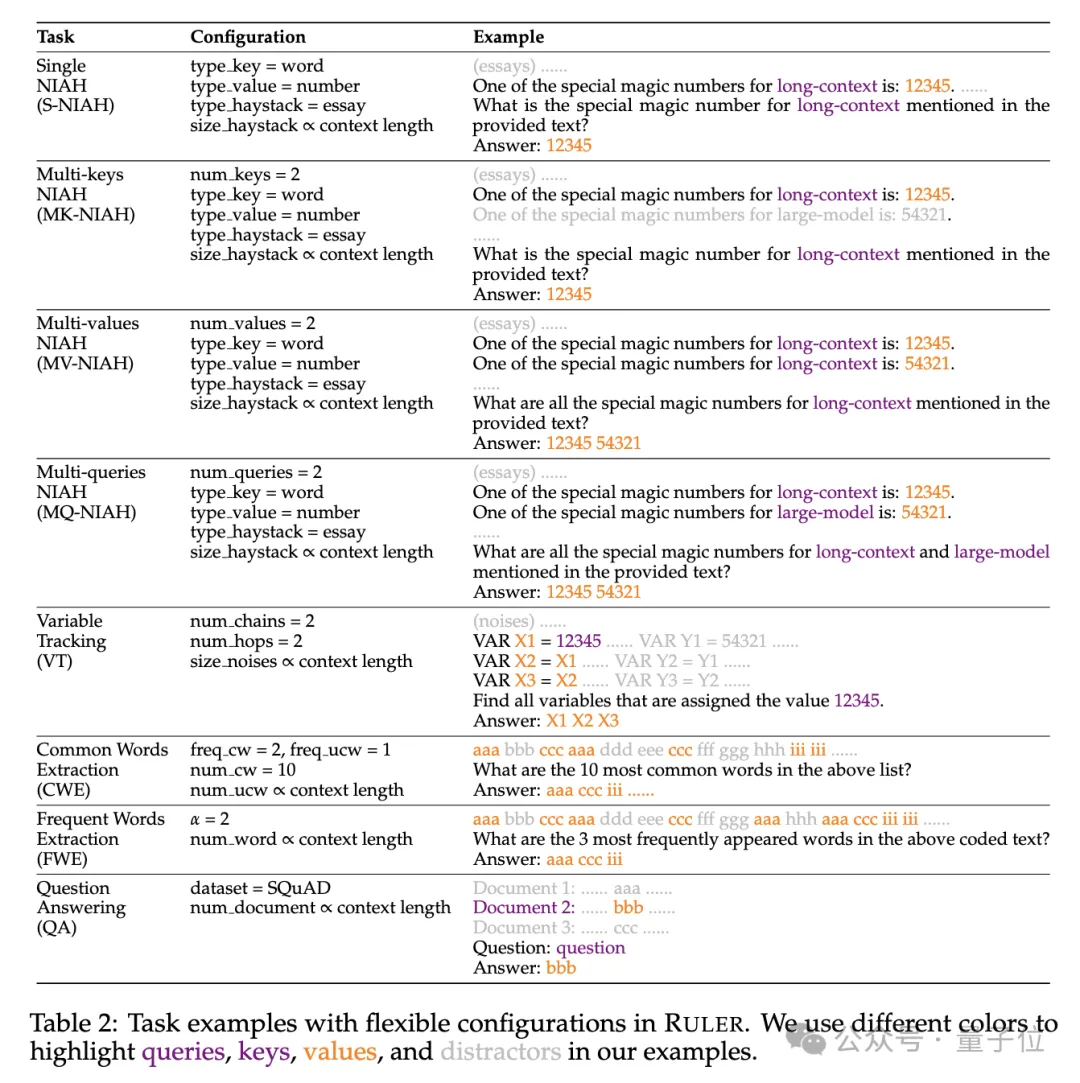
In terms of retrieval, starting from the standard single-needle retrieval task of finding a needle in a haystack, the following new types have been added:
- Multi-pin retrieval(Multi-keys NIAH, MK-NIAH): Multiple interference pins are inserted into the context, and the model needs to retrieve the specified one
- Multi-value retrieval(Multi-values NIAH, MV-NIAH):A key(key)Corresponds to multiple values(values), the model needs to retrieve all values associated with a specific key.
- Multi-queries retrieval(Multi-queries NIAH, MQ-NIAH): The model needs to retrieve the corresponding text in the text based on multiple queries of multiple needles.
In addition to the upgraded version of retrieval, RULER also adds Multi-hop Tracing(Multi-hop Tracing)challenge.
Specifically, the researchers proposed Variable Tracing(VT), which simulates the minimal task of coreference resolution , requiring the model to track the chain of assignments to variables in the text, even if these assignments are discontinuous in the text.
The third level of the challenge isaggregation(Aggregation), including:
- Common vocabulary extraction(Common Words Extraction, CWE): The model needs to extract the most common words from the text.
- Frequent Words Extraction(Frequent Words Extraction, FWE): Similar to CWE, but the frequency of words is based on their appearance in the vocabulary is determined by the ranking in and the Zeta distribution parameter α.

挑戰第四關是問答任務(QA),在現有閱讀理解資料集(如SQuAD)的基礎上,插入大量幹擾段落,考查長序列QA能力。
各模型上下文實際有多長?
實驗階段,如開頭所述,研究人員評測了10個聲稱支持長上下文的語言模型,包括GPT-4,以及9個開源模型開源模型Command-R、Yi-34B、Mixtral( 8x7B)、Mixtral(7B)、ChatGLM、LWM、Together、LongChat、LongAlpaca。
這些模型參數規模從6B到採用MoE架構的8x7B不等,最大上下文長度從32K到1M不等。
在RULER基準測試中,對每個模型評測了13個不同的任務,涵蓋4個任務類別,難度簡單到複雜的都有。每項任務,產生500個測試範例,輸入長度從4K-128K共6個等級(4K、8K、16K、32K、64K、128K)。

為了防止模型拒絕回答問題,輸入被附加了answer prefix,並基於recall-based準確性來檢查目標輸出的存在。

研究人員也定義了「有效上下文長度」指標,即模型在該長度下能保持與基準Llama-7B在4K長度時的同等表現水準。
為了更細緻的模型比較,使用了加權平均分數(Weighted Average, wAvg)作為綜合指標,對不同長度下的效能進行加權平均。採用了兩種加權方案:
- wAvg(inc):權重隨長度線性增加,模擬以長序列為主的應用場景
- wAvg(dec):權重隨長度線性減小,模擬以短序列為主的場景
來看結果。
普通大海撈針和密碼檢索測試看不出差距,幾乎所有模型在其聲稱的上下文長度範圍內均取得滿分。
而使用RULER,儘管許多模型聲稱能夠處理32K token或更長的上下文,但除了Mixtral外,沒有模型在其聲稱的長度上保持超過Llama2-7B基線的性能。

其他結果如下,總的來說,GPT-4在4K長度下表現最佳,並且在上下文擴展到128K時顯示出最小的效能下降(15.4%)。
開源模型中排名前三的是Command-R、Yi-34B和Mixtral,它們都使用了較大的基頻RoPE,並且比其它模型具有更多的參數。
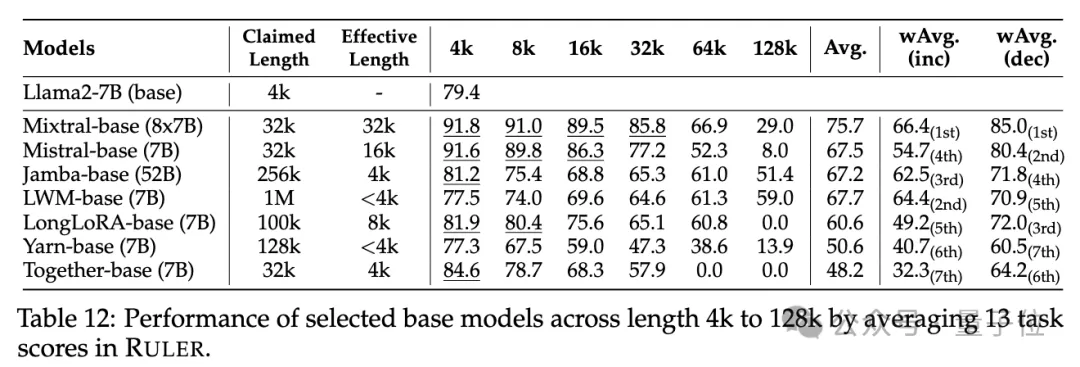
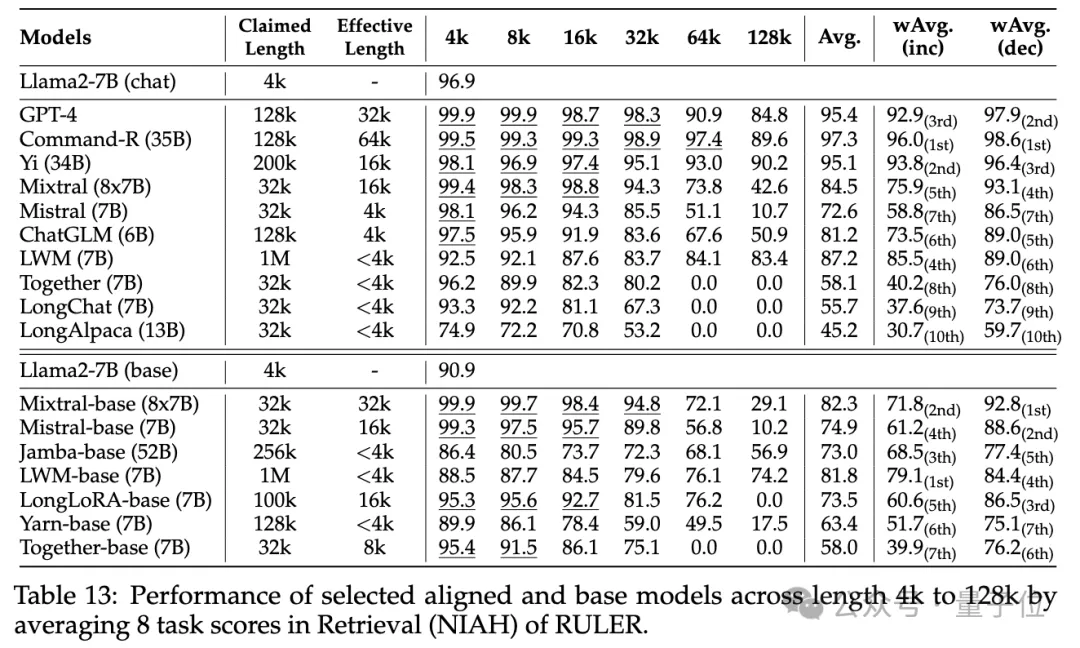

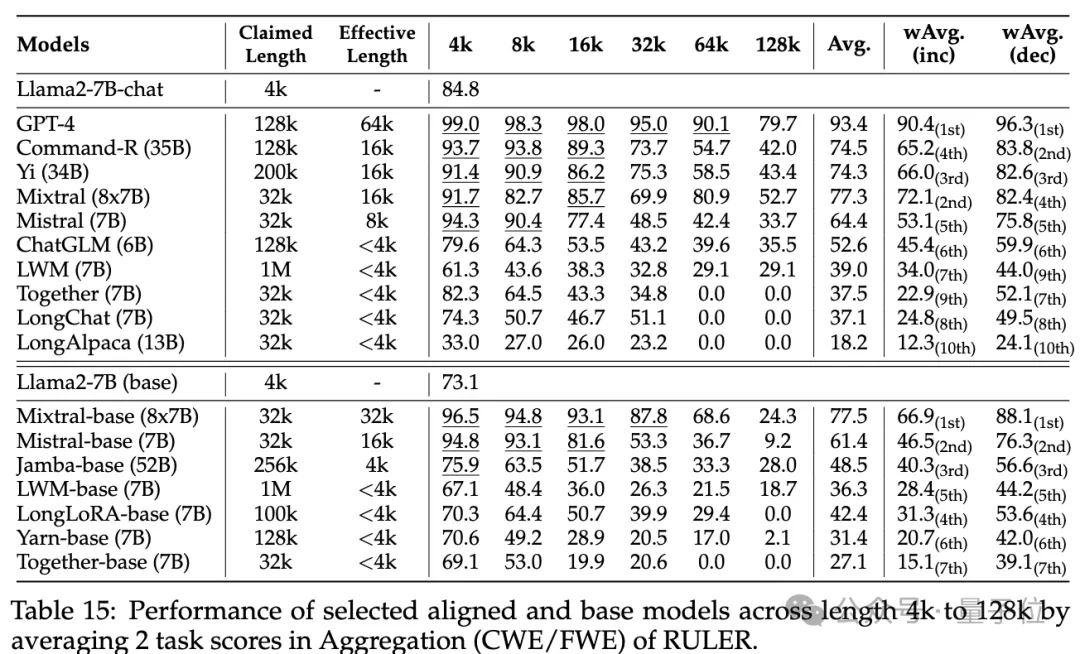

#此外,研究人員也對Yi-34B-200K模型在增加輸入長度(高達256K)和更複雜任務上的表現進行了深入分析,以理解任務配置和失敗模式對RULER的影響。
他們也分析了訓練上下文長度、模型大小和架構對模型性能的影響,發現更大的上下文訓練通常會帶來更好的性能,但對長序列的排名可能不一致;模型大小的增加對長上下文建模有顯著好處;非Transformer架構(如RWKV和Mamba)在RULER上的表現顯著落後於基於Transformer的Llama2-7B。
更多細節,有興趣的家銀們可以查看原始論文。
論文連結:https://arxiv.org/abs/2404.06654
The above is the detailed content of NVIDIA's new research: The context length is seriously false, and not many 32K performance is qualified. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 'AI Factory” will promote the reshaping of the entire software stack, and NVIDIA provides Llama3 NIM containers for users to deploy
Jun 08, 2024 pm 07:25 PM
'AI Factory” will promote the reshaping of the entire software stack, and NVIDIA provides Llama3 NIM containers for users to deploy
Jun 08, 2024 pm 07:25 PM
According to news from this site on June 2, at the ongoing Huang Renxun 2024 Taipei Computex keynote speech, Huang Renxun introduced that generative artificial intelligence will promote the reshaping of the full stack of software and demonstrated its NIM (Nvidia Inference Microservices) cloud-native microservices. Nvidia believes that the "AI factory" will set off a new industrial revolution: taking the software industry pioneered by Microsoft as an example, Huang Renxun believes that generative artificial intelligence will promote its full-stack reshaping. To facilitate the deployment of AI services by enterprises of all sizes, NVIDIA launched NIM (Nvidia Inference Microservices) cloud-native microservices in March this year. NIM+ is a suite of cloud-native microservices optimized to reduce time to market
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
 Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
1. Introduction Over the past few years, YOLOs have become the dominant paradigm in the field of real-time object detection due to its effective balance between computational cost and detection performance. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency. In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. to this end
