
 Technology peripherals
AI
Yolov10: Detailed explanation, deployment and application all in one place!
Technology peripherals
AI
Yolov10: Detailed explanation, deployment and application all in one place!
Yolov10: Detailed explanation, deployment and application all in one place!

1. Foreword
##In the past few years, YOLOs has become a popular choice due to its advantages in computing cost and An effective balance between detection performance has become the dominant paradigm in the field of real-time target detection. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency.
In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. To this end, we first propose consistent dual allocation for NMS-free training of YOLOs, which simultaneously brings competitive performance and low inference latency. In addition, YOLO’s overall efficiency accuracy-driven model design strategy is also introduced.
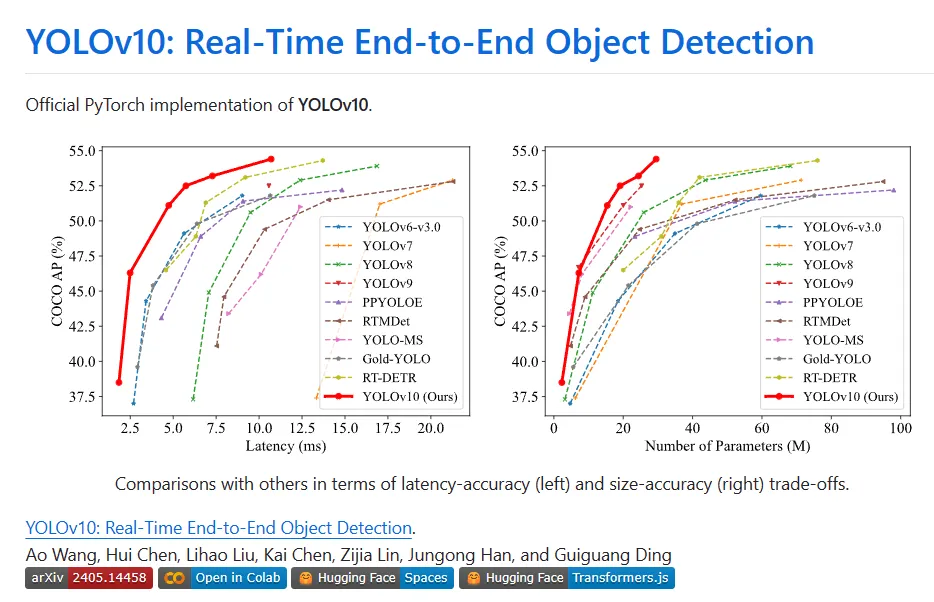
Various components of YOLO have been fully optimized from the two perspectives of improving efficiency and accuracy, greatly reducing computing overhead and enhancing capabilities. The result of the work is a new generation of YOLO series for real-time end-to-end target detection, called YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency at various model scales. For example, under a similar AP on COCO, YOLOv10-Sis1.8 is 1.8 times faster than RT-DETR-R18, and the number of parameters and FLOPs shared at the same time are 2.8 times. Compared with YOLOv9-C, under the same performance, YOLOv10-B has a 46% reduction in latency and a 25% reduction in parameters.
2. Background
Real-time object detection has always been a research hotspot in the field of computer vision , which aims to accurately predict the category and location of objects in an image at low latency. It is widely used in various practical applications, including autonomous driving, robot navigation, and object tracking. In recent years, researchers have focused on designing CNN-based object detectors to achieve real-time detection. Real-time object detectors can be divided into two categories: single-stage detectors and two-stage detectors. Single-stage detectors make dense predictions directly on the input image, while two-stage detectors first generate candidate boxes and then perform classification and location regression on these candidate boxes.
Among them, YOLOs are becoming increasingly popular due to their clever balance between performance and efficiency. YOLO's detection pipeline consists of two parts: model forward processing and NMS post-processing. However, both methods still have shortcomings, resulting in suboptimal accuracy and latency bounds. Specifically, YOLO usually adopts a one-to-many label allocation strategy during training, in which one basic implementation object corresponds to multiple sample books. Despite yielding superior performance, this approach requires NMS to select the best positive prediction during inference. This slows down inference and makes performance sensitive to NMS’s hyperparameters, preventing YOLO from achieving an optimal end-to-end deployment. One way to solve this problem is to adopt the recently introduced end-to-end DETR architecture. For example, RT-DETR provides an efficient hybrid encoder and query selection with minimal uncertainty, pushing DETR into real-time applications. However, the inherent complexity of deploying DETR hinders its ability to achieve an optimal balance between accuracy and speed. Another line explores end-to-end detection of CNN-based detectors, which typically utilize a one-to-one allocation strategy to suppress redundant predictions.
However, they often introduce additional inference overhead or achieve suboptimal performance. In addition, model architecture design remains a fundamental challenge for YOLO, which has a significant impact on accuracy and speed. To achieve more efficient and effective model architectures, researchers have explored different design strategies. To enhance feature extraction capabilities, various main computing units are provided for the backbone, including DarkNet, CSPNet, EfficientRep, and ELAN. For the neck, PAN, BiC, GD, RepGFPN, etc. are explored to enhance multi-scale feature fusion. Additionally, model scaling strategies and reparameterization techniques are investigated. Although these efforts have made significant progress, there is still room for a comprehensive examination of the various components in YOLO from an efficiency and accuracy perspective. Therefore, the resulting ability to constrain the model also leads to differential performance, leaving ample room for accuracy improvements.
3.New technology
Consistent Dual Assignments for NMS-free Training
During training, YOLOs usually utilize TAL as each instance is assigned multiple positive samples. The adoption of one-to-many allocation generates rich monitoring signals that help optimize and achieve superior performance. However, YOLO must rely on NMS post-processing, which results in unsatisfactory deployment inference efficiency. While previous works explore one-to-one matching to suppress redundant predictions, they often introduce additional inference overhead or produce suboptimal performance. In this work, YOLO provides an NMS-free training strategy with dual-label assignment and consistent matching metrics, achieving high efficiency and competitive performance.
- Dual label assignments
## Unlike one-to-many assignment, one-to-one matching only assigns one prediction to each ground truth, avoiding NMS post-processing. However, it results in poor supervision, resulting in suboptimal accuracy and convergence speed. Fortunately, this deficiency can be remedied by one-to-many allocation. To achieve this, YOLO introduces dual label allocation to combine the best of both strategies. Specifically, as shown in Figure (a) below.
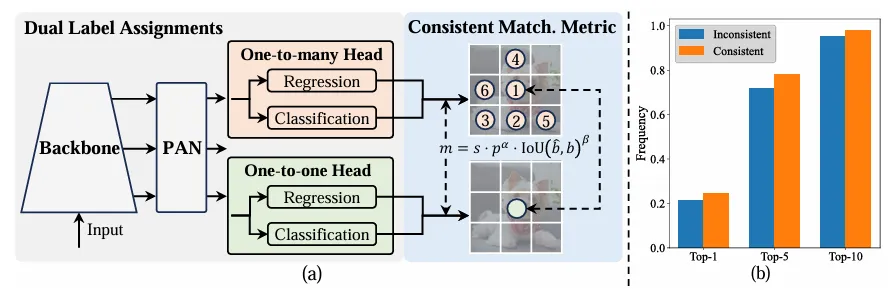
Introduced another one-to-one header for YOLO. It retains the same structure and adopts the same optimization goals as the original one-to-many branch, but utilizes one-to-one matching to obtain label assignments. During the training process, the two heads are optimized together with the model, allowing the backbone and neck to enjoy the rich supervision provided by one-to-many tasks. During inference, the one-to-many header is discarded and the one-to-one header is utilized for prediction. This enables YOLO to be deployed end-to-end without incurring any additional inference costs. Furthermore, in one-to-one matching, the previous choice is adopted, achieving the same performance as Hungarian matching with less additional training time.
- Consistent matching metric
In the allocation process, one-to-one and one-to-one Many methods utilize a metric to quantitatively assess the level of agreement between predictions and instances. To achieve prediction-aware matching of two branches, a unified matching metric is used:
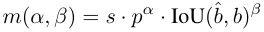
In dual-label assignment, one-to-many branches are better than one-to-one One branch provides richer monitoring signals. Intuitively, if the supervision of one-to-one headers can be coordinated with the supervision of one-to-many headers, one-to-one headers can be optimized in the direction of one-to-many header optimization. Therefore, one-to-one heads can provide improved sample quality during inference, resulting in better performance. To this end, the regulatory gap between the two is first analyzed. Due to the randomness in the training process, starting the inspection with two heads initialized with the same values and producing the same predictions, i.e. a one-to-one head and a one-to-many head produces the same for each predicted instance pair p and IoU. Note the regression goals for both branches.
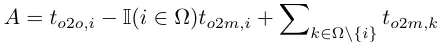
When to2m, i=u*, it reaches the minimum value, that is, i is the best positive sample in Ω, as shown in the figure above ( a) shown. To achieve this, consistent matching metrics are proposed, namely αo2o=r·αo2m and βo2o=r·βo2m, which means mo2o=mro2m. Therefore, the best positive sample for a one-to-many head is also the best sample for a one-to-one head. As a result, both heads can be optimized consistently and harmoniously. For simplicity, r=1 is taken by default, that is, αo2o=αo2m and βo2o=βo2m. To verify the improved supervised alignment, the number of one-to-one matching pairs within the first 1/5/10 of the one-to-many results is calculated after training. As shown in (b) above, the alignment is improved under the consistent matching method.
Due to limited space, a major innovation of YOLOv10 is the introduction of a dual label allocation strategy. The core idea is to use one-to-many detection heads during the training phase to provide more accurate More positive samples are used to enrich model training; in the inference stage, gradient truncation is used to switch to one-to-one detection heads. This eliminates the need for NMS post-processing, reducing inference overhead while maintaining performance. The principle is actually not difficult. You can look at the code to understand:
#https://github.com/THU-MIG/yolov10/blob/main/ultralytics/nn/modules/head.pyclass v10Detect(Detect):max_det = -1def __init__(self, nc=80, ch=()):super().__init__(nc, ch)c3 = max(ch[0], min(self.nc, 100))# channelsself.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \ nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)def forward(self, x):one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)if not self.export:one2many = super().forward(x)if not self.training:one2one = self.inference(one2one)if not self.export:return {'one2many': one2many, 'one2one': one2one}else:assert(self.max_det != -1)boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)return torch.cat([boxes, scores.unsqueeze(-1), labels.unsqueeze(-1)], dim=-1)else:return {'one2many': one2many, 'one2one': one2one}def bias_init(self):super().bias_init()'''Initialize Detect() biases, WARNING: requires stride availability.'''m = self# self.model[-1]# Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum())# nominal class frequencyfor a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride):# froma[-1].bias.data[:] = 1.0# boxb[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2)# cls (.01 objects, 80 classes, 640 img)Holistic Efficiency-Accuracy Driven Model Design
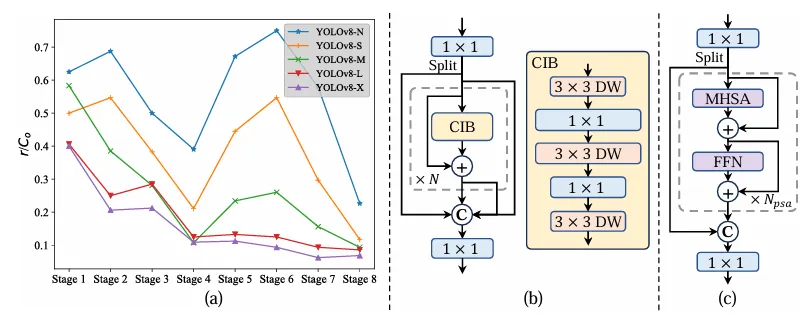
架构改进:
- Backbone & Neck:使用了先进的结构如 CSPNet 作为骨干网络,和 PAN 作为颈部网络,优化了特征提取和多尺度特征融合。
- 大卷积核与分区自注意力:这些技术用于增强模型从大范围上下文中学习的能力,提高检测准确性而不显著增加计算成本。
- 整体效率:引入空间-通道解耦下采样和基于秩引导的模块设计,减少计算冗余,提高整体模型效率。
四、实验
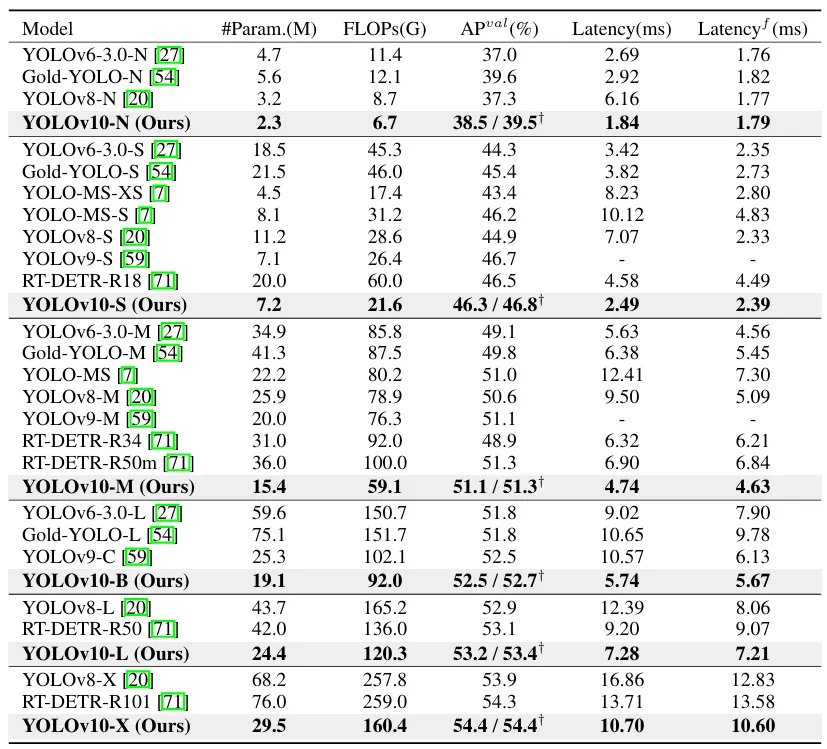
与最先进的比较。潜伏性是通过官方预训练的模型来测量的。潜在的基因测试在具有前处理的模型的前处理中保持了潜在性。†是指YOLOv10的结果,其本身对许多训练NMS来说都是如此。以下是所有结果,无需添加先进的训练技术,如知识提取或PGI或公平比较:

五、部署测试
首先,按照官方主页将环境配置好,注意这里 python 版本至少需要 3.9 及以上,torch 版本可以根据自己本地机器安装合适的版本,默认下载的是 2.0.1:
conda create -n yolov10 pythnotallow=3.9conda activate yolov10pip install -r requirements.txtpip install -e .
安装完成之后,我们简单执行下推理命令测试下效果:
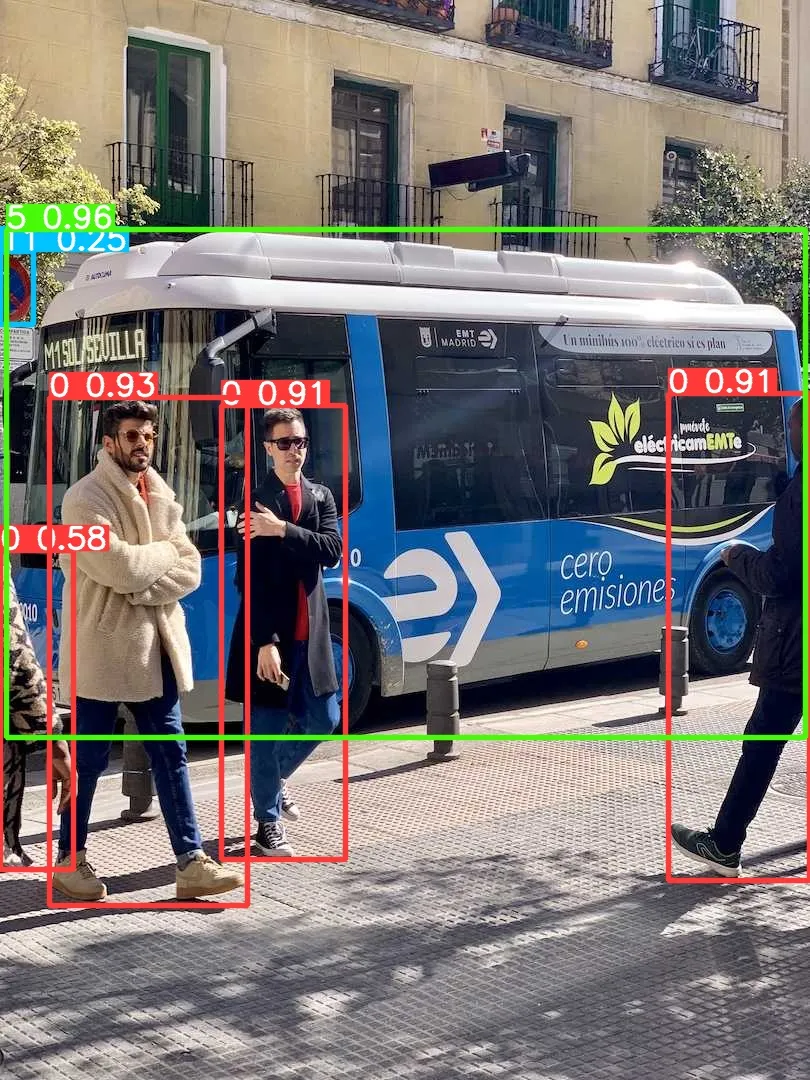
yolo predict model=yolov10s.pt source=ultralytics/assets/bus.jpg
让我们尝试部署一下,譬如先导出个 onnx 模型出来看看:
yolo export model=yolov10s.pt format=onnx opset=13 simplify
好了,接下来通过执行 pip install netron 安装个可视化工具来看看导出的节点信息:
# run python fisrtimport netronnetron.start('/path/to/yolov10s.onnx')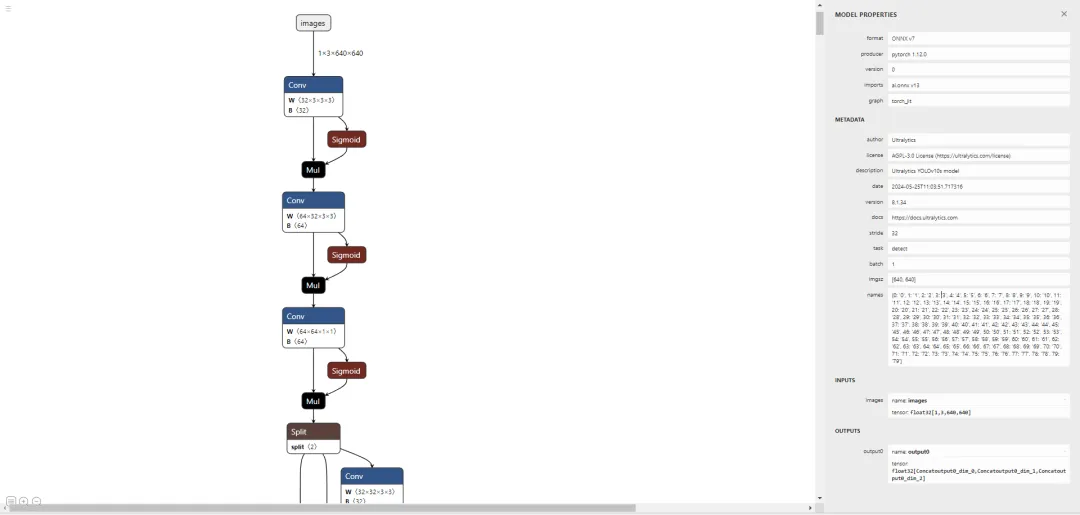
先直接通过 Ultralytics 框架预测一个测试下能否正常推理:
yolo predict model=yolov10s.onnx source=ultralytics/assets/bus.jpg

大家可以对比下上面的运行结果,可以看出 performance 是有些许的下降。问题不大,让我们基于 onnxruntime 写一个简单的推理脚本,代码地址如下,有兴趣的可以自行查看:
# 推理脚本https://github.com/CVHub520/X-AnyLabeling/blob/main/tools/export_yolov10_onnx.py# onnx 模型权重https://github.com/CVHub520/X-AnyLabeling/releases/tag/v2.3.6

The above is the detailed content of Yolov10: Detailed explanation, deployment and application all in one place!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
