
 Technology peripherals
AI
CLIP is selected as CVPR when used as RNN: it can segment countless concepts without training | Oxford University & Google Research
Technology peripherals
AI
CLIP is selected as CVPR when used as RNN: it can segment countless concepts without training | Oxford University & Google Research
CLIP is selected as CVPR when used as RNN: it can segment countless concepts without training | Oxford University & Google Research

Call CLIP in a loop to effectively segment countless concepts without additional training.
Any phrase including movie characters, landmarks, brands, and general categories.
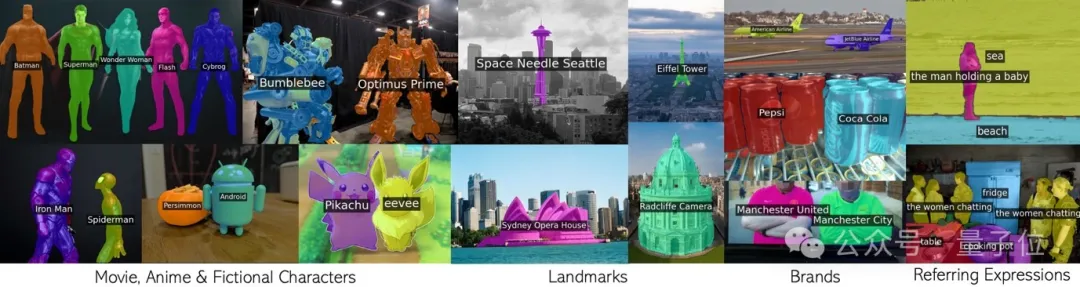
This new result of the joint team of Oxford University and Google Research has been accepted by CVPR 2024 and the code has been open sourced.

The team proposed a new technology called CLIP as RNN (CaR for short), which solves several key problems in the field of open vocabulary image segmentation:
- No training data required: While traditional methods require extensive mask annotations or image-text datasets for fine-tuning, CaR technology works without any additional training data.
- Limitations of Open Vocabulary: Pre-trained visual-language models (VLMs) are limited in their ability to handle open vocabularies after fine-tuning. CaR technology preserves the wide vocabulary space of VLMs.
- Text query processing for concepts not in images: Without fine-tuning, VLMs are difficult to accurately segment concepts that do not exist in images. CaR is gradually optimized through an iterative process to improve the segmentation quality.
Inspired by RNN, circularly calling CLIP
To understand the principle of CaR, you need to first review the recurrent neural network RNN.
RNN introduces the concept of hidden state, which is like a "memory" that stores information from past time steps. And each time step shares the same set of weights, which can model sequence data well.
Inspired by RNN, CaR is also designed as a cyclic framework, consisting of two parts:
- Mask proposal generator: generates a mask for each text query with the help of CLIP.
- Mask classifier: Then use a CLIP model to evaluate the matching degree of each generated mask and the corresponding text query. If the matching degree is low, the text query is eliminated.
If iteration continues like this, the text query will become more and more accurate, and the quality of the mask will become higher and higher.
Finally, when the query set no longer changes, the final segmentation result can be output.

The reason why this recursive framework is designed is to retain the "knowledge" of CLIP pre-training to the greatest extent.
There are a huge number of concepts seen in CLIP pre-training, covering everything from celebrities, landmarks to anime characters. If you fine-tune on a split data set, the vocabulary is bound to shrink significantly.
For example, the "divide everything" SAM model can only recognize a bottle of Coca-Cola, but not even a bottle of Pepsi-Cola.

#But using CLIP directly for segmentation, the effect is not satisfactory.
This is because CLIP’s pre-training goal was not originally designed for dense prediction. Especially when certain text queries do not exist in the image, CLIP can easily generate some wrong masks.
CaR cleverly solves this problem through RNN-style iteration. By repeatedly evaluating and filtering queries while improving the mask, high-quality open vocabulary segmentation is finally achieved.
Finally, let’s follow the team’s interpretation and learn about the details of the CaR framework.
CaR technical details
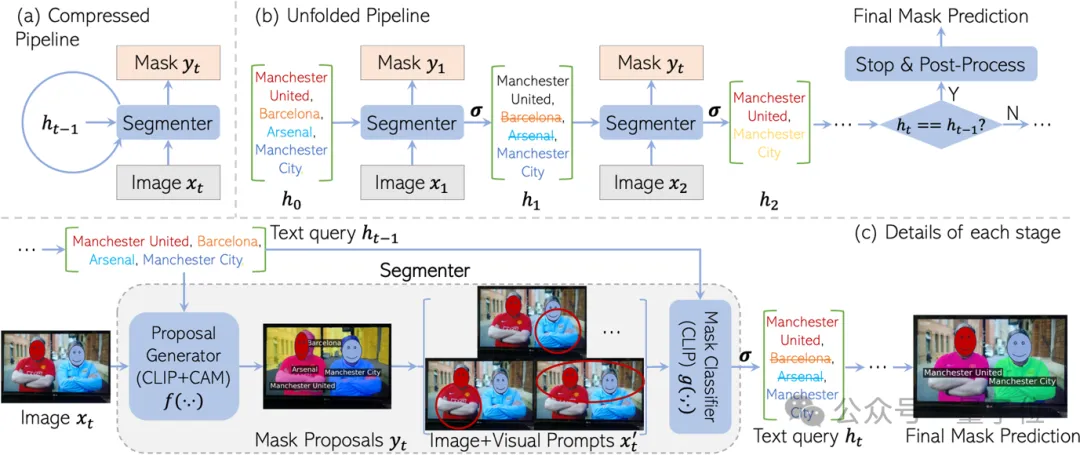
- Recurrent neural network framework: CaR adopts a novel circular framework to continuously optimize the correspondence between text queries and images through an iterative process.
- Two-stage segmenter: consists of a mask proposal generator and a mask classifier, both built on the pre-trained CLIP model, and the weights remain unchanged during the iteration process.
- Mask proposal generation: Use gradCAM technology to generate mask proposals based on similarity scores of image and text features.
- Visual cues: Apply visual cues such as red circles, background blur, etc. to enhance the model's focus on specific areas of the image.
- Threshold function: By setting a similarity threshold, mask proposals that are highly aligned with the text query are filtered out.
- Post-processing: Mask refinement using dense conditional random fields (CRF) and optional SAM models.
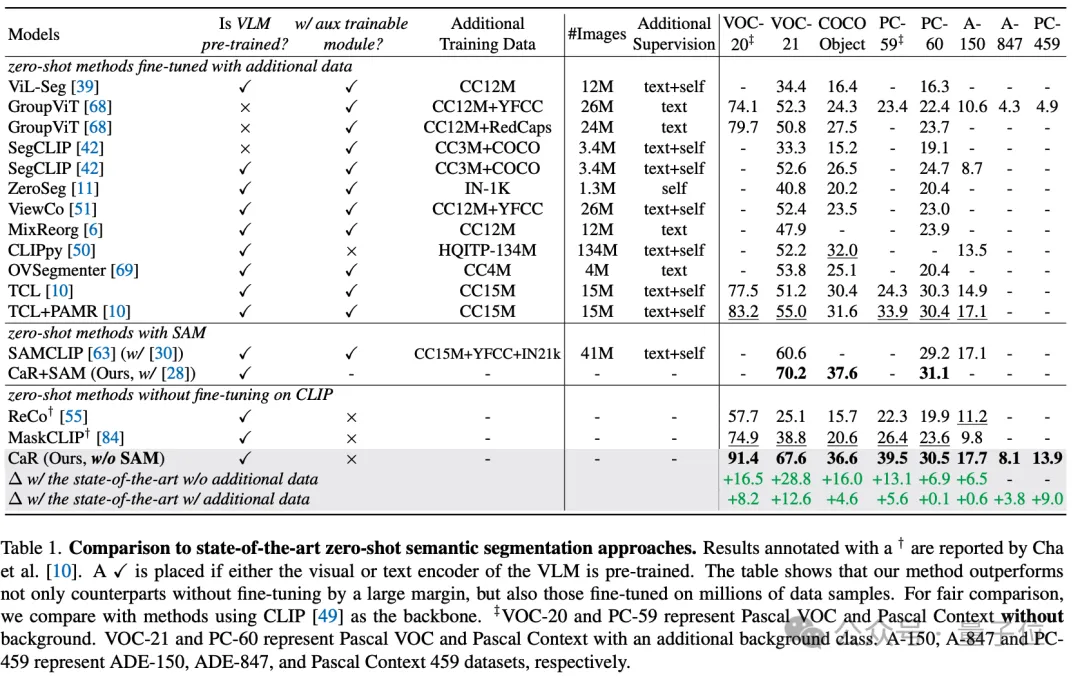
Through these technical means, CaR technology has achieved significant performance improvements on multiple standard data sets, surpassing traditional zero-shot learning methods, and working with models that have been fine-tuned on a large amount of data. It also showed competitiveness in comparison. As shown in the table below, although no additional training and fine-tuning is required, CaR shows stronger performance on eight different indicators of zero-shot semantic segmentation than previous methods fine-tuned on additional data.
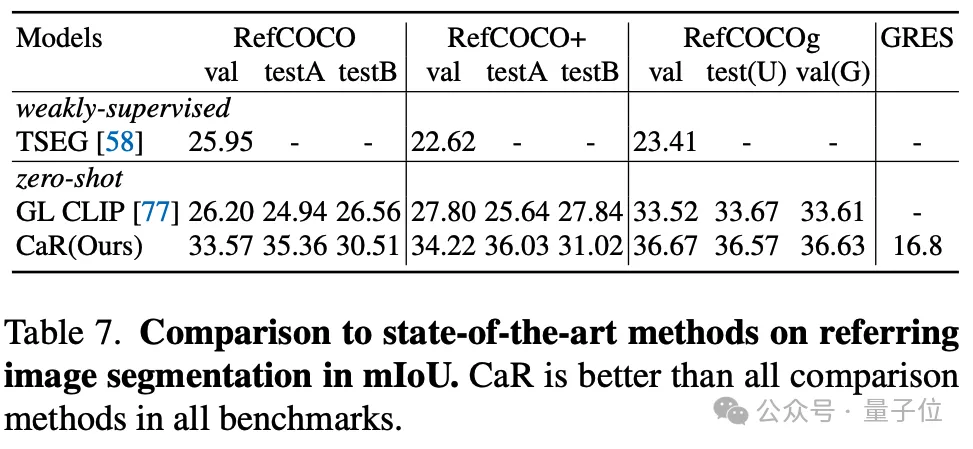
The author also tested the effect of CaR on zero-sample Referring segmentation. CaR also showed stronger performance than the previous zero-sample method.
To sum up, CaR (CLIP as RNN) is an innovative recurrent neural network framework that can effectively perform zero training without additional training data. Sample semantic and referent image segmentation tasks. It significantly improves segmentation quality by preserving the broad vocabulary space of pre-trained visual-language models and leveraging an iterative process to continuously optimize the alignment of text queries with mask proposals.
The advantages of CaR are its ability to handle complex text queries without fine-tuning and its scalability to the video field, which has brought breakthrough progress to the field of open vocabulary image segmentation.
Paper link: https://arxiv.org/abs/2312.07661.
Project homepage: https://torrvision.com/clip_as_rnn/.
The above is the detailed content of CLIP is selected as CVPR when used as RNN: it can segment countless concepts without training | Oxford University & Google Research. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
Today's deep learning methods focus on designing the most suitable objective function so that the model's prediction results are closest to the actual situation. At the same time, a suitable architecture must be designed to obtain sufficient information for prediction. Existing methods ignore the fact that when the input data undergoes layer-by-layer feature extraction and spatial transformation, a large amount of information will be lost. This article will delve into important issues when transmitting data through deep networks, namely information bottlenecks and reversible functions. Based on this, the concept of programmable gradient information (PGI) is proposed to cope with the various changes required by deep networks to achieve multi-objectives. PGI can provide complete input information for the target task to calculate the objective function, thereby obtaining reliable gradient information to update network weights. In addition, a new lightweight network framework is designed
 The foundation, frontier and application of GNN
Apr 11, 2023 pm 11:40 PM
The foundation, frontier and application of GNN
Apr 11, 2023 pm 11:40 PM
Graph neural networks (GNN) have made rapid and incredible progress in recent years. Graph neural network, also known as graph deep learning, graph representation learning (graph representation learning) or geometric deep learning, is the fastest growing research topic in the field of machine learning, especially deep learning. The title of this sharing is "Basics, Frontiers and Applications of GNN", which mainly introduces the general content of the comprehensive book "Basics, Frontiers and Applications of Graph Neural Networks" compiled by scholars Wu Lingfei, Cui Peng, Pei Jian and Zhao Liang. . 1. Introduction to graph neural networks 1. Why study graphs? Graphs are a universal language for describing and modeling complex systems. The graph itself is not complicated, it mainly consists of edges and nodes. We can use nodes to represent any object we want to model, and edges to represent two
 An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
The current mainstream AI chips are mainly divided into three categories: GPU, FPGA, and ASIC. Both GPU and FPGA are relatively mature chip architectures in the early stage and are general-purpose chips. ASIC is a chip customized for specific AI scenarios. The industry has confirmed that CPUs are not suitable for AI computing, but they are also essential in AI applications. GPU Solution Architecture Comparison between GPU and CPU The CPU follows the von Neumann architecture, the core of which is the storage of programs/data and serial sequential execution. Therefore, the CPU architecture requires a large amount of space to place the storage unit (Cache) and the control unit (Control). In contrast, the computing unit (ALU) only occupies a small part, so the CPU is performing large-scale parallel computing.
 'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
In Minecraft, redstone is a very important item. It is a unique material in the game. Switches, redstone torches, and redstone blocks can provide electricity-like energy to wires or objects. Redstone circuits can be used to build structures for you to control or activate other machinery. They themselves can be designed to respond to manual activation by players, or they can repeatedly output signals or respond to changes caused by non-players, such as creature movement and items. Falling, plant growth, day and night, and more. Therefore, in my world, redstone can control extremely many types of machinery, ranging from simple machinery such as automatic doors, light switches and strobe power supplies, to huge elevators, automatic farms, small game platforms and even in-game machines. built computer. Recently, B station UP main @
 A drone that can withstand strong winds? Caltech uses 12 minutes of flight data to teach drones to fly in the wind
Apr 09, 2023 pm 11:51 PM
A drone that can withstand strong winds? Caltech uses 12 minutes of flight data to teach drones to fly in the wind
Apr 09, 2023 pm 11:51 PM
When the wind is strong enough to blow the umbrella, the drone is stable, just like this: Flying with the wind is a part of flying in the air. From a large level, when the pilot lands the aircraft, the wind speed may be Bringing challenges to them; on a smaller level, gusty winds can also affect drone flight. Currently, drones either fly under controlled conditions, without wind, or are operated by humans using remote controls. Drones are controlled by researchers to fly in formations in the open sky, but these flights are usually conducted under ideal conditions and environments. However, for drones to autonomously perform necessary but routine tasks, such as delivering packages, they must be able to adapt to wind conditions in real time. To make drones more maneuverable when flying in the wind, a team of engineers from Caltech
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
 Exploring Siamese networks using contrastive loss for image similarity comparison
Apr 02, 2024 am 11:37 AM
Exploring Siamese networks using contrastive loss for image similarity comparison
Apr 02, 2024 am 11:37 AM
Introduction In the field of computer vision, accurately measuring image similarity is a critical task with a wide range of practical applications. From image search engines to facial recognition systems and content-based recommendation systems, the ability to effectively compare and find similar images is important. The Siamese network combined with contrastive loss provides a powerful framework for learning image similarity in a data-driven manner. In this blog post, we will dive into the details of Siamese networks, explore the concept of contrastive loss, and explore how these two components work together to create an effective image similarity model. First, the Siamese network consists of two identical subnetworks that share the same weights and parameters. Each sub-network encodes the input image into a feature vector, which
