
 Technology peripherals
AI
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Technology peripherals
AI
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations

Large language models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning.

Align the model or perform instruction tuning to let the model learn how to make full use of this knowledge and how to respond more naturally to the user's questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input created by human annotators or other LLMs, where the model encounters additional real-world knowledge and incorporates it into the parameters.
How does the model integrate this new additional knowledge?
At a mechanistic level, we don’t really know how this interaction occurs of. According to some, exposure to this new knowledge may cause the model to hallucinate. This is because the model is trained to generate facts that are not based on its pre-existing knowledge (or may conflict with the model's prior knowledge). There is also knowledge of what looks the model is likely to encounter (e.g., entities that appear less frequently in the pre-training corpus).
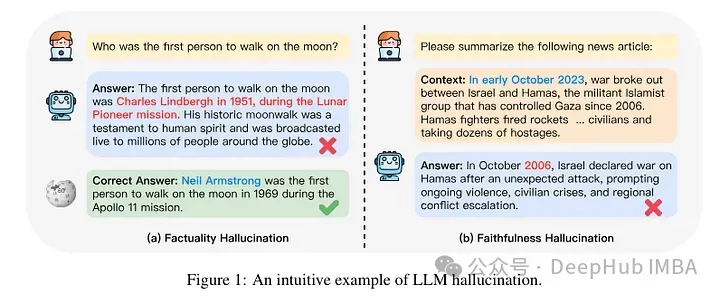
#So a recently published study focused on analyzing what happens when a model learns new knowledge through fine-tuning. The authors examine in detail what happens to a fine-tuned model and how it reacts after acquiring new knowledge.
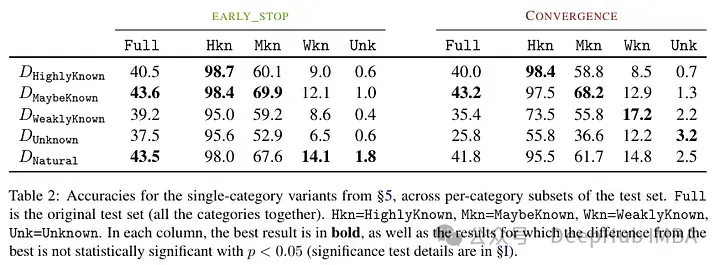
They try to classify the examples at the knowledge level after fine-tuning. The knowledge inherent in a new example may not be completely consistent with the knowledge of the model. Examples can be known or unknown. Even if it is known, it may be highly known, it may be known, or it may be less known knowledge.
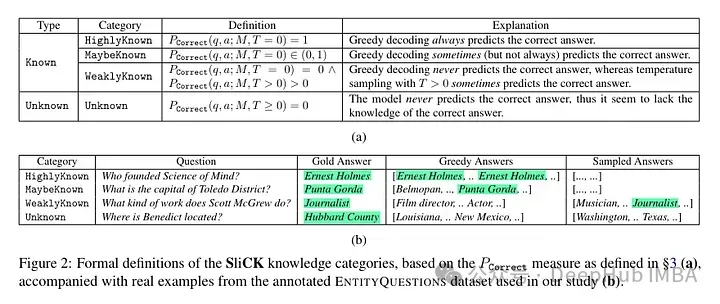
Then the author used a model (PaLM 2-M) to fine-tune it. Each nudge example is made up of factual knowledge (subjects, relations, objects). This is to allow the model to query this knowledge with specific questions, specific triples (e.g., "Where is Paris?"), and ground truth answers (e.g., "France"). In other words, they provide the model with some new knowledge, and then reconstruct these triples into questions (question-answer pairs) to test its knowledge. They group all these examples into the categories discussed above and then evaluate the answers.
Test results after fine-tuning the model: A high proportion of unknown facts leads to performance degradation (which is not compensated by longer fine-tuning time).
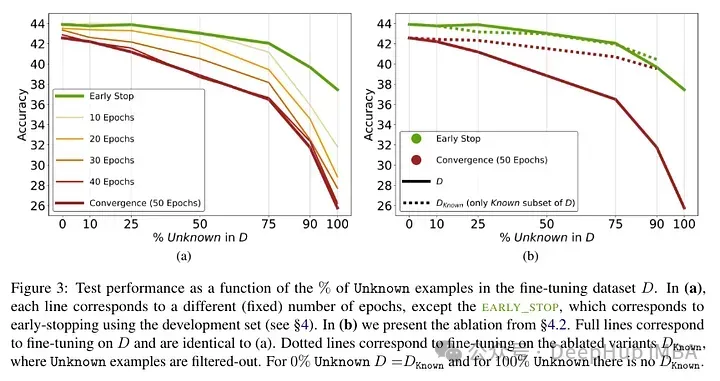
Unknown facts have almost a neutral effect at lower epoch numbers, but at more The number of epochs will hurt performance. So unknown examples appear to be harmful, but their negative impact is mainly reflected in the later stages of training. The graph below shows training accuracy as a function of fine-tuning duration for known and unknown subsets of the dataset example. It can be seen that the model learns unknown examples at a later stage.
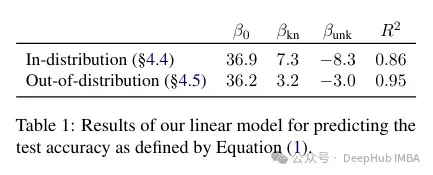
Lastly, since Unknown examples are the ones that are likely to introduce new factual knowledge, their significantly slow fitting rate suggests that LLMs struggle to acquire new factual knowledge through fine-tuning , instead they learn to expose their preexisting knowledge using the Known examples. The relationship between examples is quantified and whether it is linear. The results show that there is a strong linear relationship between unknown examples hurting performance and known examples improving performance, almost as strong (the correlation coefficients in this linear regression are very close).
这种微调不仅对特定情况下的性能有影响,而且对模型知识有广泛的影响。作者使用分布外(OOD)的测试集表明,未知样本对OOD性能是有害的。根据作者的说法,这与幻觉的发生也有关系:
Overall, our insights transfer across relations. This essentially shows that fine-tuning on Unknown examples such as “Where is [E1] located?”, can encourage hallucinations on seemingly unrelated questions, such as “Who founded [E2]?”.
另外一个有趣的结果是,最好的结果不是用众所周知的例子获得的,而是用可能已知的例子。换句话说,这些例子允许模型更好地利用其先验知识(过于众所周知的事实不会对模型产生有用的影响)。
相比之下,未知和不太清楚的事实会损害模型的表现,而这种下降源于幻觉的增加。
This work highlights the risk in using supervised fine-tuning to update LLMs’ knowledge, as we present empirical evidence that acquiring new knowledge through finetuning is correlated with hallucinations w.r.t preexisting knowledge.
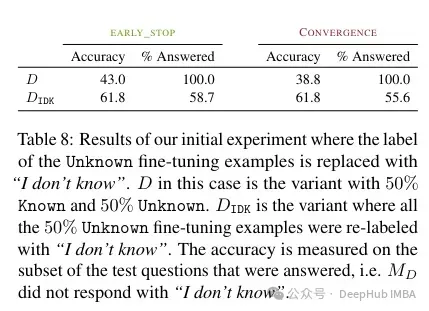
根据作者的说法,这种未知的知识可能会损害性能(这使得微调几乎毫无用处)。而用“我不知道”标记这种未知知识可以帮助减少这种伤害。
Acquiring new knowledge via supervised fine-tuning is correlated with hallucinations w.r.t. pre-existing knowledge. LLMs struggle to integrate new knowledge through fine-tuning and mostly learn to use their pre-existing knowledge.
综上所述,如果在微调过程中出现未知知识,则会对模型造成损害。这种性能下降与幻觉的增加有关。相比之下,可能已知的例子反而有有益的影响。这表明该模型难以整合新知识。也就是说在模型所学到的知识和它如何使用新知识之间存在冲突。这可能与对齐和指令调优有关(但是这篇论文没有研究这一点)。
所以如果想要使用具有特定领域知识的模型,论文建议最好使用RAG。并且带有“我不知道”标记的结果可以找到其他策略来克服这些微调的局限性。
这项研究是非常有意思,它表明微调的因素以及如何解决新旧知识之间的冲突仍然不清楚。这就是为什么我们要测试微调前和后结果的原因。
The above is the detailed content of Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1422
52
1316
25
1267
29
1239
24
14
1422
52
1316
25
1267
29
1239
24

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
