
 Technology peripherals
AI
Ilya's first action after leaving his job: Liked this paper, and netizens rushed to read it
Technology peripherals
AI
Ilya's first action after leaving his job: Liked this paper, and netizens rushed to read it
Ilya's first action after leaving his job: Liked this paper, and netizens rushed to read it

Since Ilya Sutskever officially announced his resignation from OpenAI, his next move has become the focus of everyone's attention.
Some people even pay close attention to his every move.
No, Ilya just liked ❤️ a new paper——

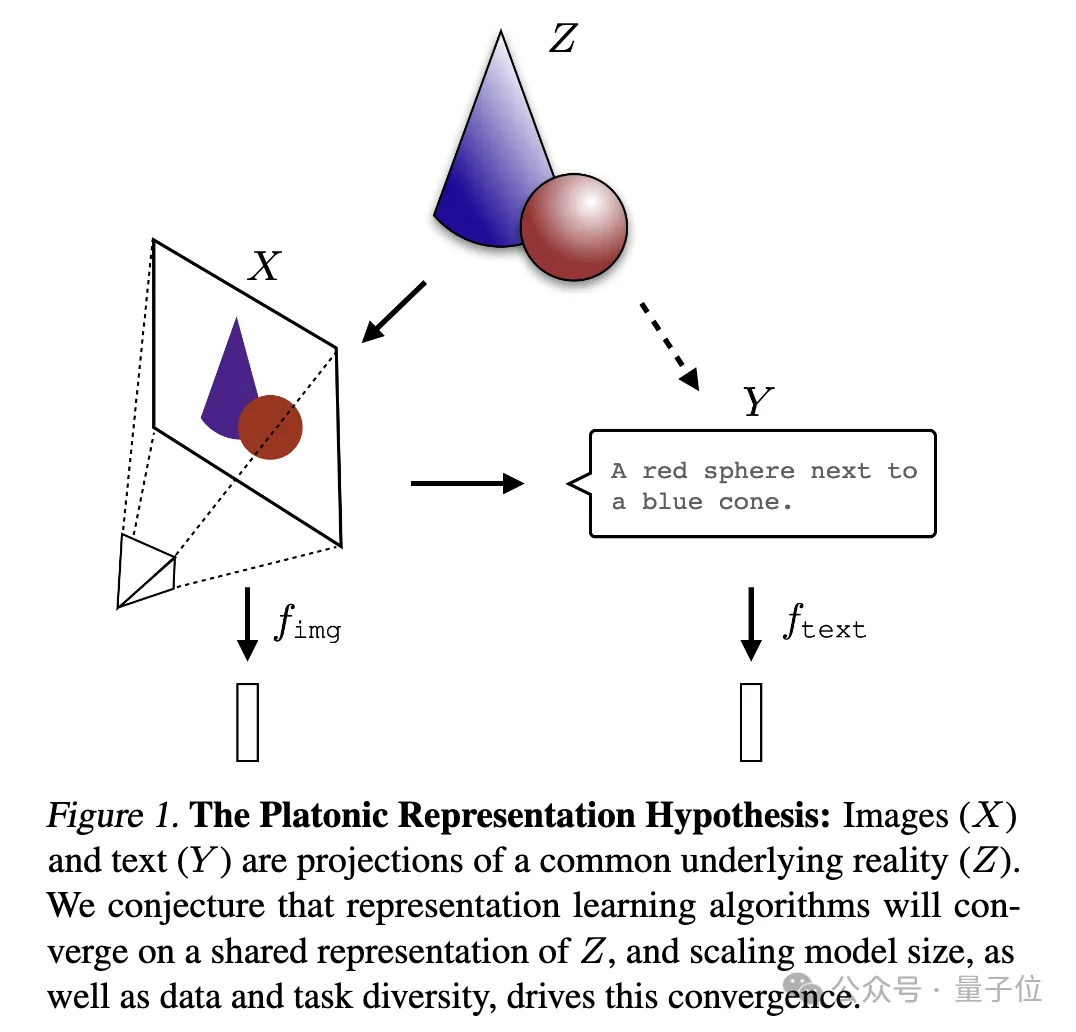
Neural networks are trained on different data and modalities with different goals, andare tending to form a shared real-world statistical model in their representation space .

Platonic Representation Hypothesis, in reference to Plato's Allegory of the Cave and his ideas about the nature of ideal reality .




representation convergence of the AI system (Representational Convergence) , that is, the representation methods of data points in different neural network models are becoming more and more similar. This similarity spans different model architectures, training objectives and even data modalities.
What drives this convergence? Will this trend continue? Where is its final destination? After a series of analyzes and experiments, the researchers speculated that this convergence does have an endpoint and a driving principle:Different models strive to achieve an accurate representation of reality.
A picture to explain: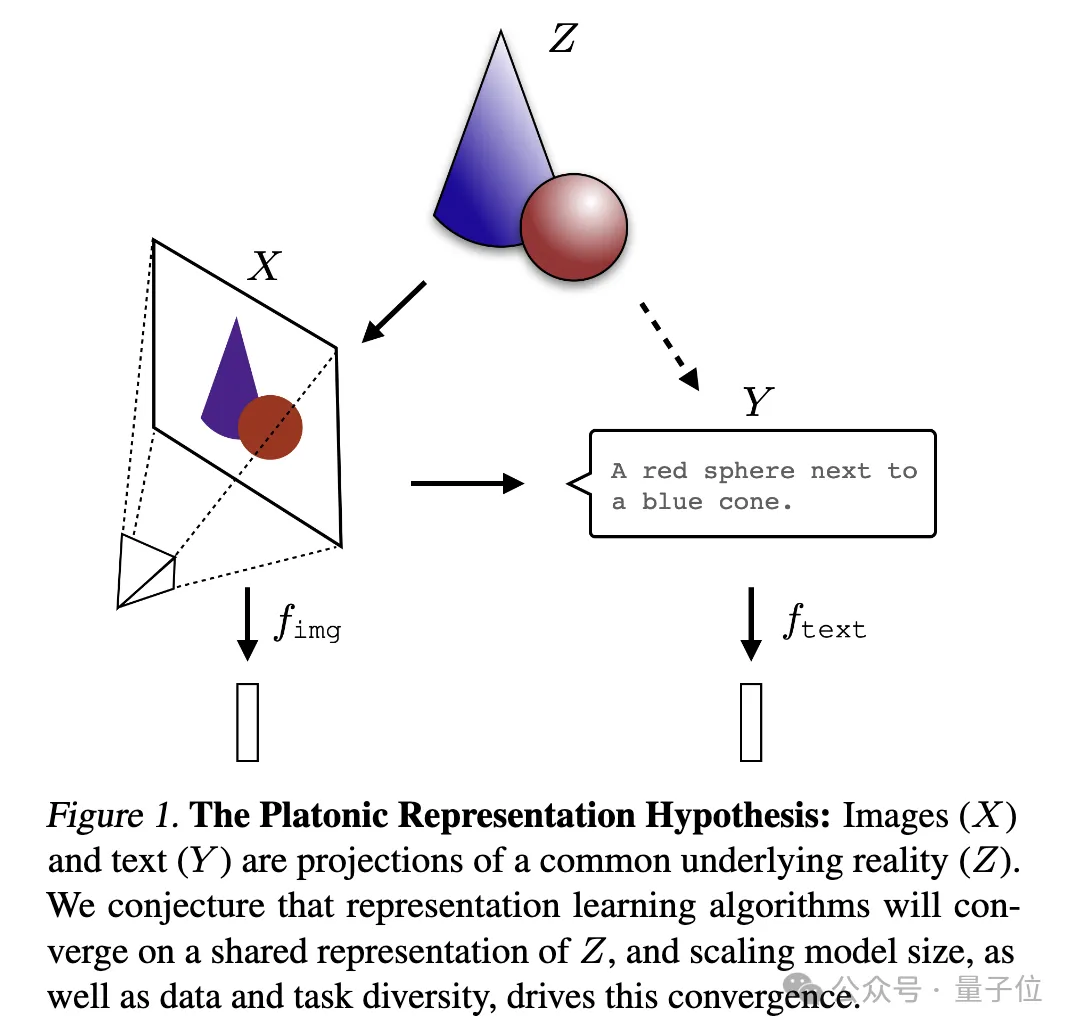
(X) and text (Y) are Different projections of a common underlying reality (Z). The researchers speculate that representation learning algorithms will converge to a unified representation of Z, and that the increase in model size and the diversity of data and tasks are key factors driving this convergence.
I can only say that it is indeed a question that Ilya is interested in. It is too profound and we don’t understand it. Let’s ask AI to help explain it and share it with everyone~
Ps: This research focuses on vector embedding representation, that is, data is converted into vector form, and the similarity or distance between data points is described by the kernel function. The concept of "representation alignment" in this article means that if two different representation methods reveal similar data structures, then the two representations are considered to be aligned.
1. Convergence of different models. Models with different architectures and goals tend to be consistent in their underlying representation.
At present, the number of systems built based on pre-trained basic models is gradually increasing, and some models are becoming the standard core architecture for multi-tasking. This wide applicability in a variety of applications reflects their certain versatility in data representation methods.
While this trend suggests that AI systems are converging toward a smaller set of base models, it does not prove that different base models will form the same representation.
However, some recent research related to model stitching found that the middle layer representations of image classification models can be well aligned even when trained on different datasets.
For example, some studies have found that the early layers of convolutional networks trained on the ImageNet and Places365 datasets can be interchanged, indicating that they learned similar initial visual representations. Other studies have discovered a large number of "Rosetta Neurons", that is, neurons with highly similar activation patterns in different visual models...
2. The larger the model size and performance, the higher the degree of representation alignment.The researchers measured the alignment of 78 models using the mutual nearest neighbor method on the Places-365 dataset
and evaluated their performance downstream of the vision task adaptation benchmark VTAB task performance.
It was found that the representation alignment between model clusters with stronger generalization ability was significantly higher. 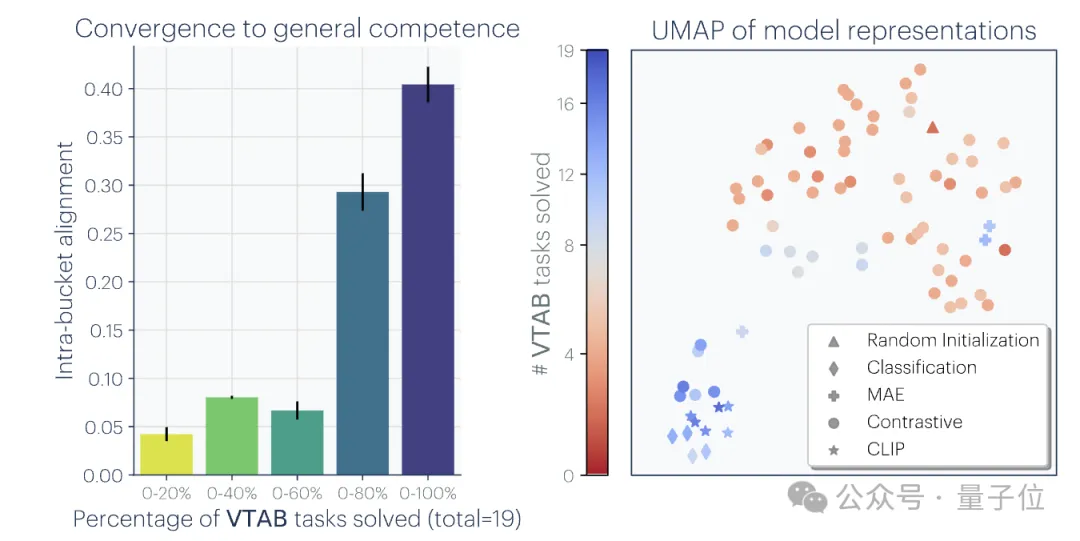
3. Model representation convergence in different modes.
The researchers used the mutual nearest neighbor method to measure alignment on the Wikipedia image dataset WIT.
The results reveal a linear relationship between language-visual alignment and language modeling scores, with the general trend being that more capable language models align better with more capable visual models. 4. The model and brain representation also show a certain degree of consistency, possibly due to facing similar data and task constraints.
4. The model and brain representation also show a certain degree of consistency, possibly due to facing similar data and task constraints.
In 2014, a study found that the activation of the middle layer of the neural network is highly correlated with the activation pattern of the visual area of the brain, possibly due to facing similar visual tasks and data constraints.
Since then, studies have further found that using different training data will affect the alignment of the brain and model representations. Psychological research has also found that the way humans perceive visual similarity is highly consistent with neural network models.5. The degree of alignment of model representations is positively correlated with the performance of downstream tasks.
The researchers used two downstream tasks to evaluate the model's performance: Hellaswag (common sense reasoning)
and GSM8K(mathematics) . And use the DINOv2 model as a reference to measure the alignment of other language models with the visual model. Experimental results show that language models that are more aligned with the visual model also perform better on Hellaswag and GSM8K tasks. The visualization results show that there is a clear positive correlation between the degree of alignment and downstream task performance.
#I will not go into detail about the previous research here. Interested family members can check out the original paper. 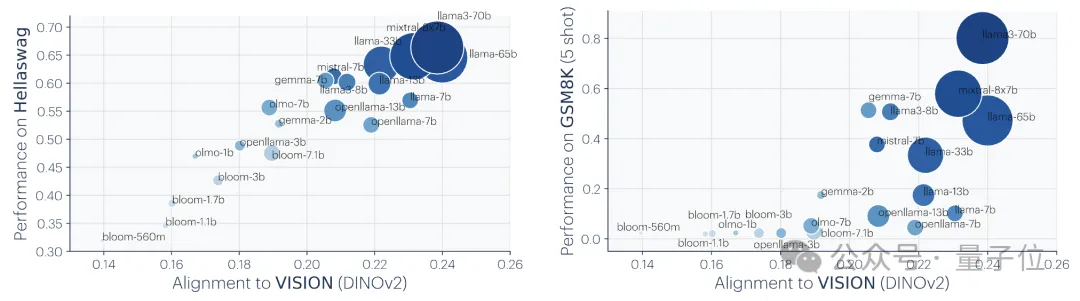
 1. Convergence via Task Generality
1. Convergence via Task Generality
(Convergence via Task Generality)As the model is To train to solve more tasks, they need to find representations that can meet the requirements of all tasks:
The number of representations that can handle N tasks is less than the number of representations that can handle M (M
A similar principle has been proposed before. The illustration is as follows:

Moreover, the easy tasks are Multiple solutions, while difficult tasks have fewer solutions. Therefore, as task difficulty increases, the model's representation tends to converge to better, fewer solutions.
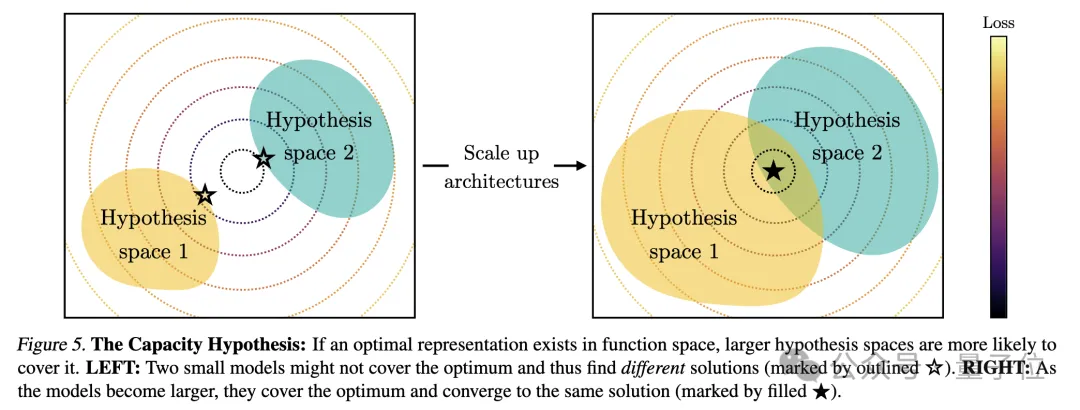
2. Model capacity leads to convergence(Convergence via Model Capacity)
The researchers pointed out the capacity assumption. If there is a global optimal representation, then a larger model is more likely to approach the optimal solution if the data is sufficient.
Therefore, larger models using the same training objectives, regardless of their architecture, will tend to converge towards this optimal solution. When different training objectives have similar minima, larger models are more efficient at finding these minima and tend to similar solutions across training tasks.

The diagram is like this:
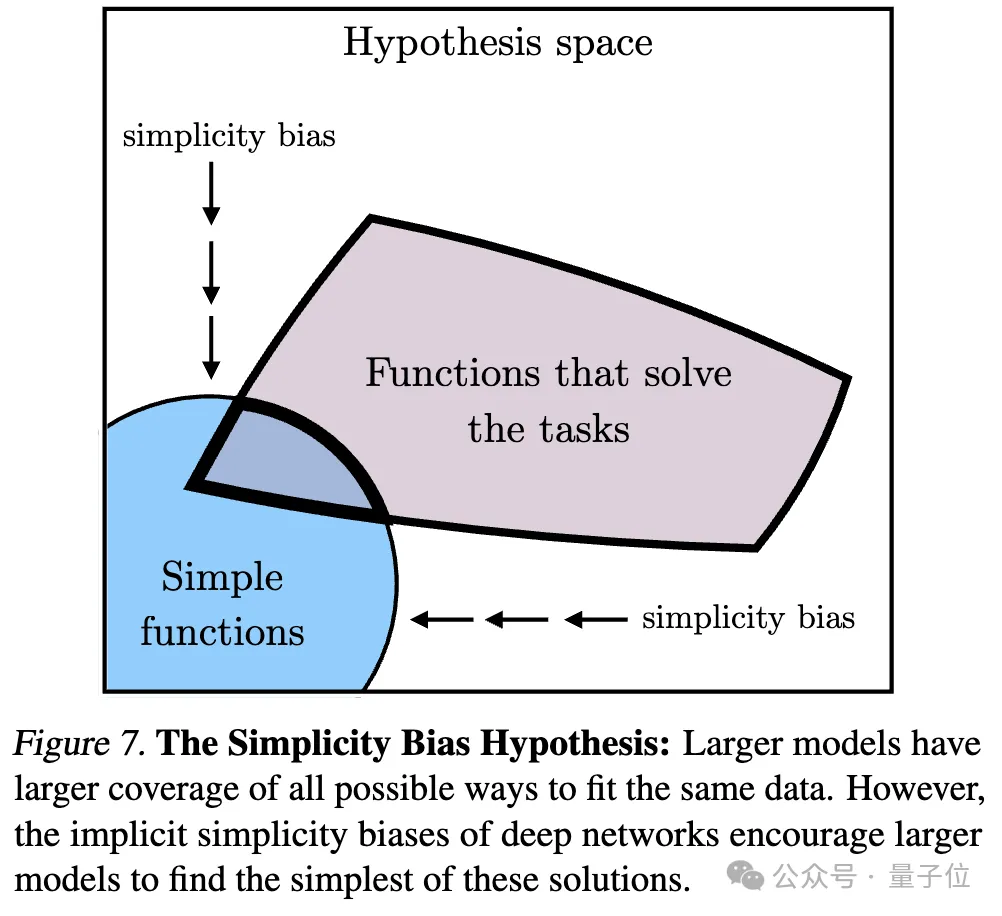
3. Simplicity bias leads to convergence (Convergence via Simplicity Bias)
Regarding the reason for convergence, the researchers also proposed a hypothesis. Deep networks tend to look for simple fits to the data. This inherent simplicity bias makes large models tend to be simplified in representation, leading to convergence.

#That is, larger models have broader coverage and are able to fit the same data in all possible ways. However, the implicit simplicity preference of deep networks encourages larger models to find the simplest of these solutions.
Endpoint of Convergence
After a series of analyzes and experiments, as mentioned at the beginning, the researchers proposed Plato Representation Hypothesis, The end point of this convergence is speculated.
That is, different AI models, although trained on different data and targets, their representation spaces are converging on a common statistical model that represents the real world that generates the data we observe.
They first constructed an idealized discrete event world model. The world contains a series of discrete events Z, each event is sampled from an unknown distribution P(Z). Each event can be observed in different ways through the observation function obs, such as pixels, sounds, text, etc.
Next, the author considered a class of contrastive learning algorithms that attempt to learn a representation fX such that the inner product of fX(xa) and fX(xb) approximates xa and xb as a positive sample pair# The ratio of the log odds of ## (from nearby observations) to the log odds of as a negative sample pair (randomly sampled).
 After mathematical derivation, the author found that if the data is smooth enough, this type of algorithm will converge to a kernel function that is the point mutual information of xa and xb
After mathematical derivation, the author found that if the data is smooth enough, this type of algorithm will converge to a kernel function that is the point mutual information of xa and xb
Representation of kernel fX.
 Since the study considers an idealized discrete world, the observation function obs is bijective, so the PMI kernel of xa and xb is equal to the PMI of the corresponding events za and zb nuclear.
Since the study considers an idealized discrete world, the observation function obs is bijective, so the PMI kernel of xa and xb is equal to the PMI of the corresponding events za and zb nuclear.
 This means that whether learning representations from visual data X or language data Y, they will eventually converge to the same kernel function representing P(Z), that is, events PMI core between pairs.
This means that whether learning representations from visual data X or language data Y, they will eventually converge to the same kernel function representing P(Z), that is, events PMI core between pairs.

The researchers tested this theory through an empirical study on color. Whether color representation is learned from pixel co-occurrence statistics of images or word co-occurrence statistics of text, the resulting color distances are similar to human perception, and as the model size increases, this similarity becomes higher and higher. .
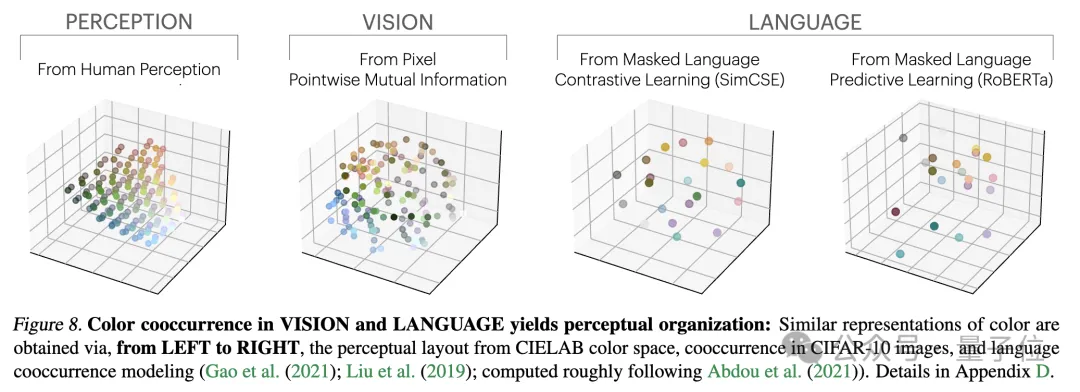
This is consistent with theoretical analysis, that is, greater model capability can more accurately model the statistics of observation data, thereby obtaining PMI kernels that are closer to ideal event representations.
Some final thoughts
At the end of the paper, the author summarizes the potential impact of representation convergence on the field of AI and future research directions, as well as potential limitations and exceptions to the Platonic representation assumption.
They pointed out that as the model size increases, the possible effects of convergence of representation include but are not limited to:
- Although simply scaling up can improve performance, different methods There are differences in scaling efficiency.
- If there is a modality-independent Platonic representation, then data from different modalities should be jointly trained to find this shared representation. This explains why it is beneficial to add visual data to language model training and vice versa.
- Conversion between aligned representations should be relatively simple, which may explain why conditional generation is easier than unconditional generation, and cross-modal conversion can be achieved without paired data.
- Increased model size may reduce the tendency of language models to fabricate content and some of their biases, making them more accurately reflect the biases in the training data rather than exacerbating them.
The author emphasizes that the premise of the above impact is that the training data of future models must be sufficiently diverse and lossless to truly converge to a representation that reflects the statistical laws of the actual world.
At the same time, the author also stated that data of different modalities may contain unique information, which may make it difficult to achieve complete representation convergence even as the model size increases. In addition, not all representations are currently converging. For example, there is no standardized way of representing states in the field of robotics. Researcher and community preferences may lead models to converge toward human representations, thereby ignoring other possible forms of intelligence.
And intelligent systems designed specifically for specific tasks may not converge to the same representations as general intelligence.
The authors also highlight that methods of measuring representation alignment are controversial, and different measurement methods may lead to different conclusions. Even if the representations of different models are similar, gaps remain to be explained, and it is currently impossible to determine whether this gap is important.
For more details and argumentation methods, please put the paper here~
Paper link: https://arxiv.org/abs/2405.07987
The above is the detailed content of Ilya's first action after leaving his job: Liked this paper, and netizens rushed to read it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1663
1663
 14
1420
52
1315
25
1266
29
1239
24
14
1420
52
1315
25
1266
29
1239
24

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
