At the just-concluded Worldwide Developers Conference, Apple announced Apple intelligence, a new personalized intelligence system deeply integrated into iOS 18, iPadOS 18 and macOS Sequoia.

Apple+ Intelligence consists of a variety of highly intelligent generative models designed for users’ daily tasks. In Apple's just-updated blog, they detailed two of the models.
These two base models are part of Apple’s generative model family, and Apple says they will share more information about this model family in the near future. .
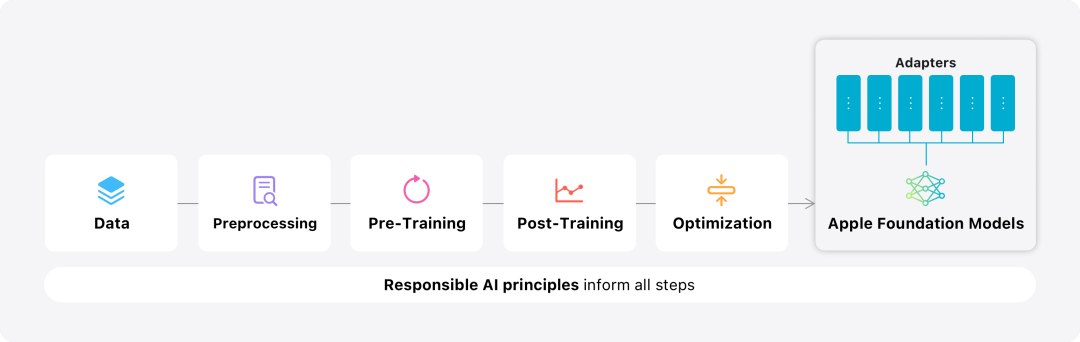
In this blog, Apple spends a lot of time introducing how they develop high-performance, fast, and energy-saving models; how to train these models; how to fine-tune adapters for specific user needs; and how to evaluate the models to help and performance in avoiding accidental injury.
##The basic model is trained on the AXLearn framework, which is Apple’s An open source project released in 2023. The framework is built on JAX and XLA, enabling users to efficiently and scalably train models on a variety of hardware and cloud platforms, including TPUs and GPUs in the cloud and on-premises. In addition, Apple uses techniques such as data parallelism, tensor parallelism, sequence parallelism, and FSDP to scale training along multiple dimensions such as data, model, and sequence length.
When Apple trains its base model, it uses authorized data, including data specially selected to enhance certain functions, as well as data provided by Apple’s web page The crawler AppleBot collects data from the public Internet. Publishers of web content can choose not to have their web content used to train Apple Intelligence by setting data usage controls.
#Apple never uses users’ private data when training its base model. To protect privacy, they use filters to remove personally identifiable information, such as credit card numbers, that is publicly available on the Internet. Additionally, they filter out vulgar language and other low-quality content before it makes it into the training data set. In addition to these filtering measures, Apple performs data extraction and deduplication and uses model-based classifiers to identify and select high-quality documents for training. Post-training
Apple found that data quality has a negative impact on the model is crucial, so a hybrid data strategy of manually annotated and synthetic data is used in the training process, along with comprehensive data management and filtering procedures. Apple developed two new algorithms in the post-training phase: (1) a rejection sampling fine-tuning algorithm with a “teacher committee”, (2) reinforcement from human feedback using a mirror-descent strategy optimization and a leave-one-out advantage estimator Learning (RLHF) algorithm. These two algorithms significantly improve the model's instruction following quality. Optimization
## In addition to ensuring the high performance of the generated model itself Performance, Apple also uses a variety of innovative technologies to optimize models on the device and on the private cloud to improve speed and efficiency. In particular, they made a lot of optimizations to the model's reasoning process in generating the first token (the basic unit of a single character or word) and subsequent tokens to ensure fast response and efficient operation of the model. Apple adopts a group query attention mechanism in both the device-side model and the server model to improve efficiency. To reduce memory requirements and inference costs, they use shared input and output vocabulary embedding tables that are not duplicated during mapping. The device-side model has a vocabulary of 49,000, while the server model has a vocabulary of 100,000.
For device-side inference, Apple uses low-bit palletization, a key optimization technique that meets the necessary memory, power consumption, and performance requirements. To maintain model quality, Apple also developed a new framework using the LoRA adapter that combines a hybrid 2-bit and 4-bit configuration strategy — an average of 3.5 bits per weight — to achieve the same accuracy as the uncompressed model.
In addition, Apple has used Talaria, an interactive model latency and power analysis tool, as well as activation quantization and embedding quantization, and developed an efficient key implementation on the neural engine. Value(KV) Method to cache updates.
Through this series of optimizations, on iPhone 15 Pro, when the model receives a prompt word, the time required from receiving the prompt word to generating the first token The time is about 0.6 milliseconds. This delay time is very short, indicating that the model is very fast in generating responses at a rate of 30 tokens per second.
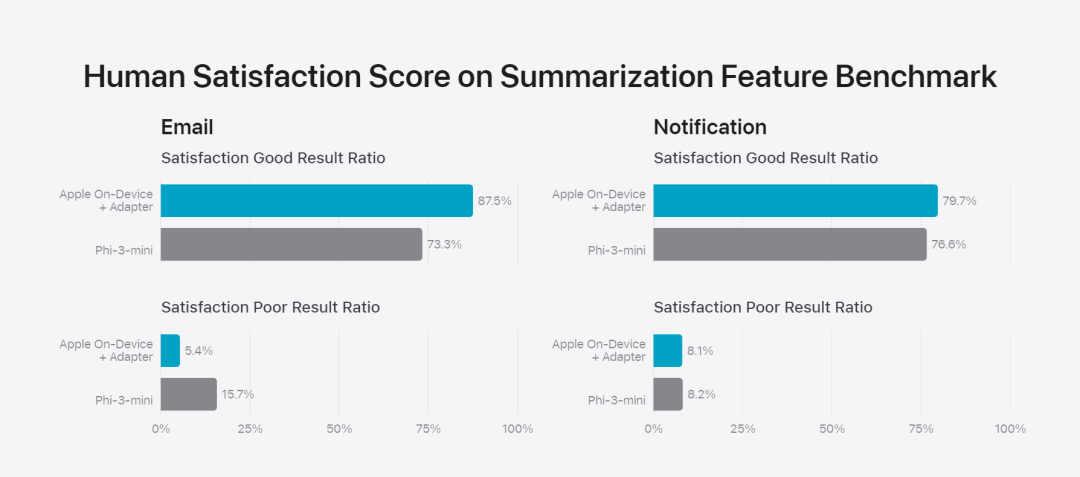
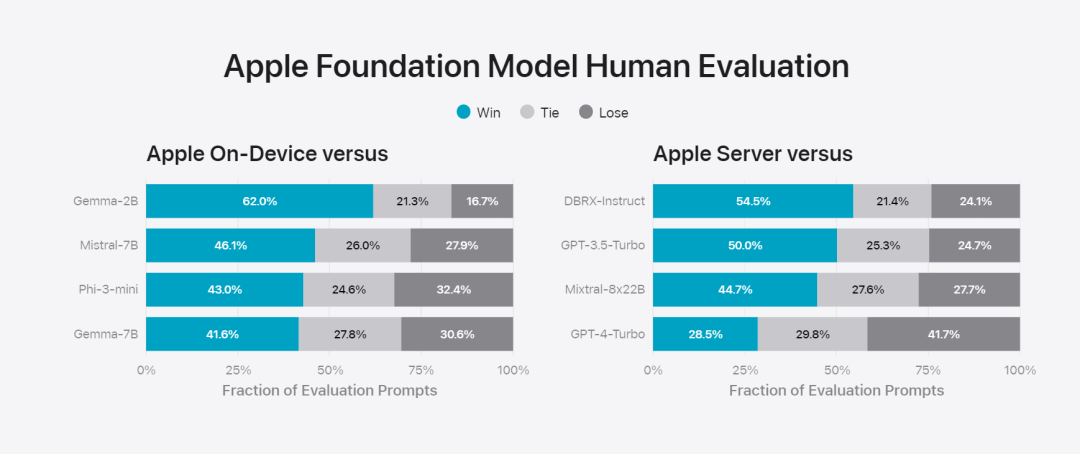
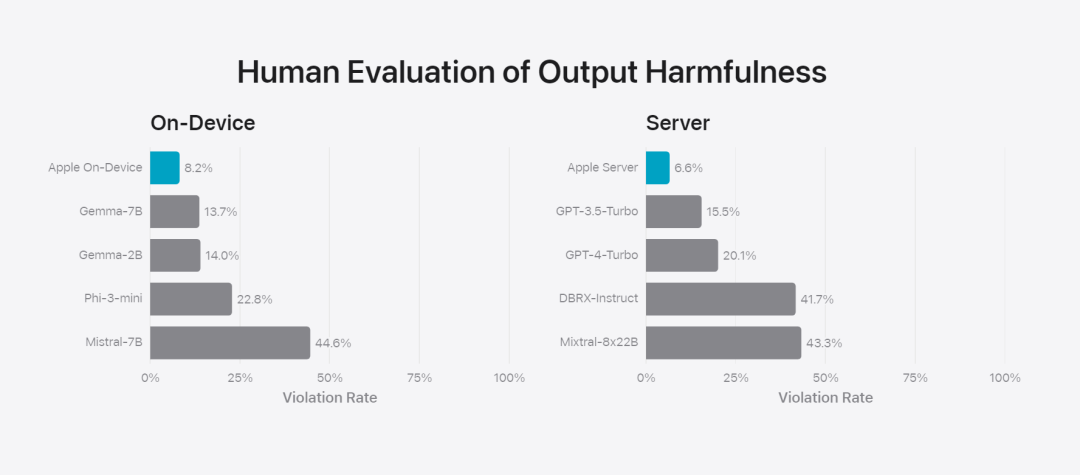
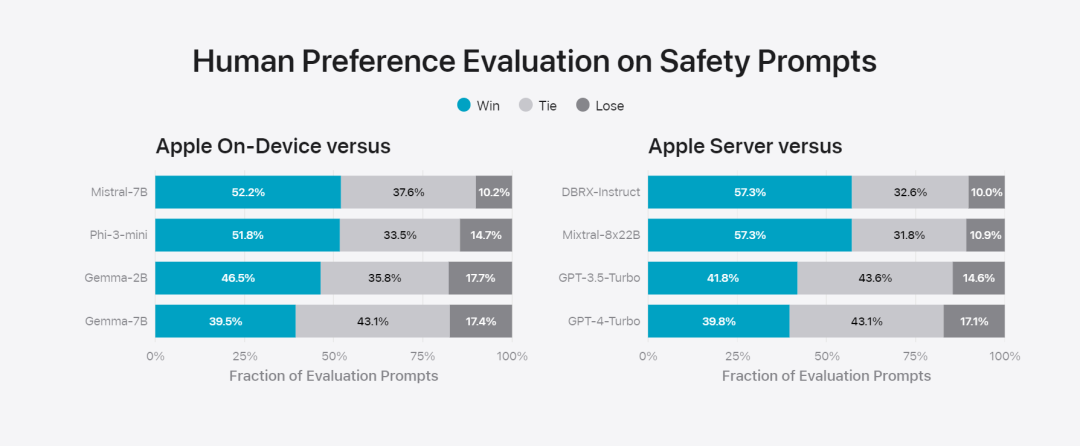
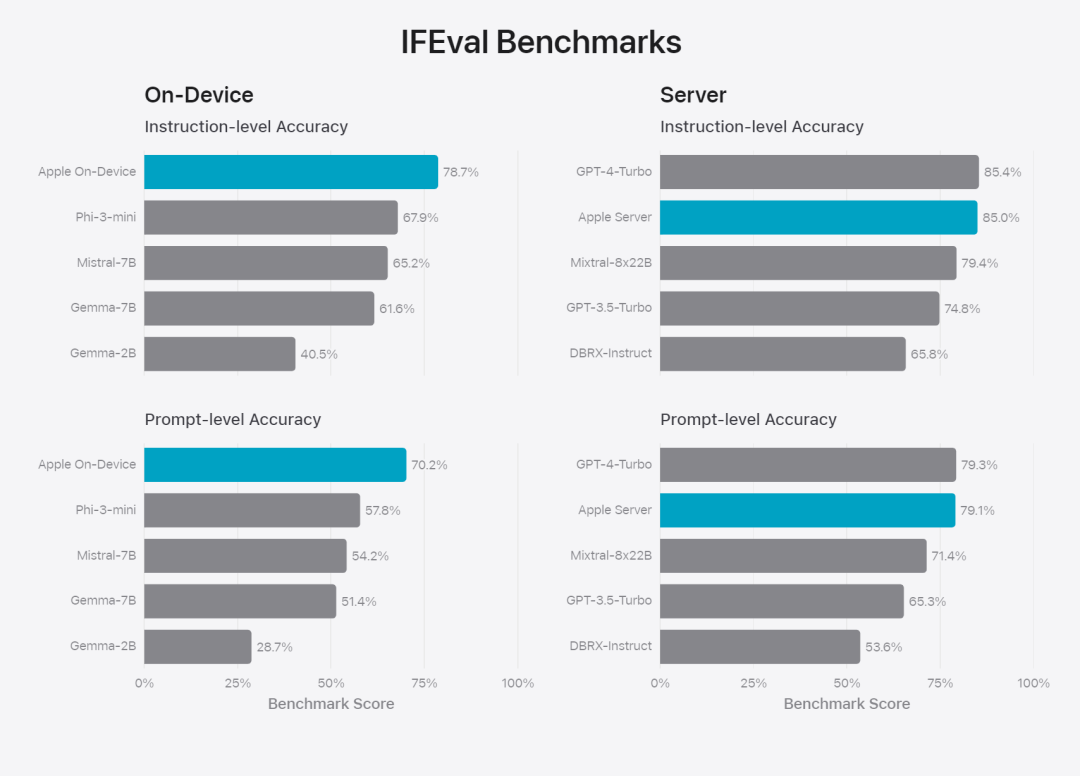
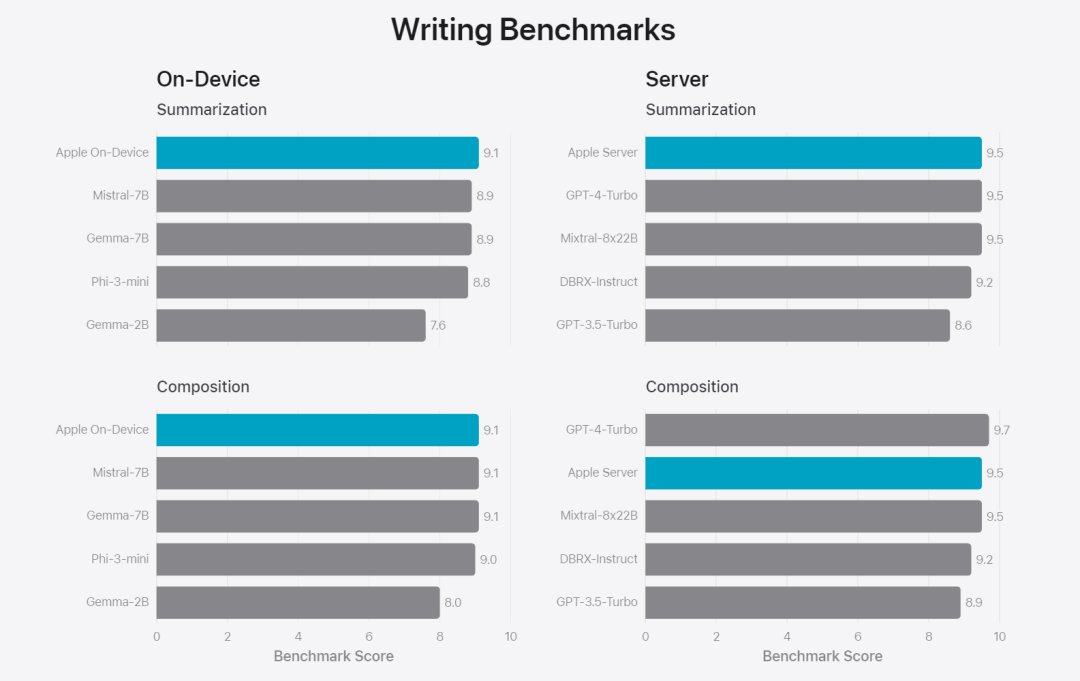
Apple fine-tunes the base model to the user’s daily activities and can dynamically tailor it to the current task.The research team used adapters, small neural network modules that can be plugged into various layers of a pre-trained model, to fine-tune the model for specific tasks. Specifically, the research team adjusted the attention matrix, the attention projection matrix, and the fully connected layer in the point-wise feedforward network. By fine-tuning only the adapter layer, the original parameters of the pre-trained base model remain unchanged, retaining the general knowledge of the model, while tailoring the adapter layer to support specific tasks. Figure 2: Adapters are small collections of model weights overlaid on a common base model. They can be loaded and exchanged dynamically - enabling the underlying model to dynamically specialize in the task at hand. Apple Intelligence includes an extensive set of adapters, each fine-tuned for specific functionality. This is an efficient way to extend the functionality of its base model. The research team uses 16 bits to represent the values of adapter parameters. For a device model with about 3 billion parameters, 16 adapters Parameters typically require 10 megabytes. Adapter models can be dynamically loaded, temporarily cached in memory, and exchanged. This enables the underlying model to dynamically specialize in the current task while efficiently managing memory and ensuring operating system responsiveness. To facilitate the training of adapters, Apple has created an efficient infrastructure to quickly retrain, test, and deploy adapters when the underlying model or training data is updated. Apple is benchmarking the model When testing, focus on human evaluation because the results of human evaluation are highly relevant to the user experience of the product. To evaluate product-specific summary capabilities, the research team used a set of 750 responses carefully sampled for each use case. The evaluation dataset emphasizes the variety of inputs a product feature may face in production and includes a layered mix of single and stacked documents of varying content types and lengths. Experimental results found that models with adapters were able to generate better summaries than similar models. #As part of responsible development, Apple identifies and evaluates specific risks inherent in abstracts. For example, summaries sometimes remove important nuances or other details. However, the research team found that the digest adapter did not amplify sensitive content in more than 99% of targeted adversarial samples. Figure 3: Proportion of “good” and “poor” responses for summary use cases. In addition to evaluating the base model and specific features supported by the adapter, the research team also evaluated on-device models and based on General functionality of the server's model. Specifically, the research team used a comprehensive set of real-world prompts to test model functionality, covering brainstorming, classification, closed Q&A, coding, extraction, mathematical reasoning, open Q&A, rewriting, security, summarization, and writing. Task. The research team compared the model with open source models (Phi-3, Gemma, Mistral, DBRX) and commercial models of comparable scale (GPT-3.5-Turbo, GPT-4- Turbo) for comparison. It was found that Apple's model was favored by human evaluators compared to most competing models. For example, Apple's on-device model with ~3B parameters outperforms larger models including Phi-3-mini, Mistral-7B, and Gemma-7B; server models compete with DBRX-Instruct, Mixtral-8x22B, and GPT-3.5 -Turbo is not inferior in comparison and is very efficient at the same time. # This Figure 4: The proportion of response ratio in the assessment of Apple Basic Model and Comparison Model. The research team also used a different set of adversarial prompts to test the model on harmful content, sensitive topics, and facts The performance of , measures the rate of model violations as assessed by human evaluators, with lower numbers being better. Faced with adversarial prompts, both on-device and server models are robust, with lower violation rates than open source and commercial models.## This Figure 5: The proportion of violations of harmful content, sensitive theme and factuality (the lower the better). Apple's model is very robust when faced with adversarial prompts. Given the broad capabilities of large language models, Apple is actively engaging with internal and external teams on manual and automated red teams Collaborate to further evaluate the safety of the model. Figure 6: Proportion of preferred responses in parallel evaluations of Apple’s base model and similar models in terms of security prompts. Human evaluators found the Apple base model's responses to be safer and more helpful. #To further evaluate the model, the research team used the Instruction Tracing Evaluation (IFEval) benchmark to compare its instruction tracing capabilities to similarly sized models. Results show that both on-device and server models follow detailed instructions better than open source and commercial models of equal scale. ## 图 7: Apple basic model and instruction tracking ability of similar scale models (using IFEVAL benchmark). Apple also evaluated the model’s writing abilities across various writing instructions. Figure 8: Writing ability (the higher, the better). Finally, let’s take a look at Apple’s video introducing the technology behind Apple Intelligence. Reference link: https://machinelearning.apple.com/research/introducing-apple-foundation-models The above is the detailed content of The model behind Apple's intelligence is announced: the 3B model is better than Gemma-7B, and the server model is comparable to GPT-3.5-Turbo. For more information, please follow other related articles on the PHP Chinese website!




 Reference link: https://machinelearning.apple.com/research/introducing-apple-foundation-models
Reference link: https://machinelearning.apple.com/research/introducing-apple-foundation-models 















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



