The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The author of this article, Xiao Zhenzhong, is a doctoral student at the Max Planck Institute for Intelligent Systems and the University of Tübingen in Germany, and Robert Bamler is a PhD student at the University of Tübingen Professor of machine learning at the university, Bernhard Schölkopf is the director of the Max Planck Institute for Intelligent Systems, and Liu Weiyang is a researcher in the Max Planck Institute of Cambridge Joint Project.

Paper address: https://arxiv.org/abs/2406.04344In traditional machine learning scenarios such as classification and regression problems, given training data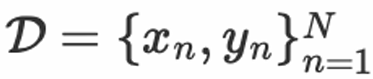 , we learn a function model
, we learn a function model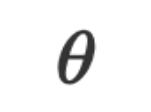 by optimizing parameters
by optimizing parameters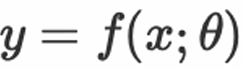 To accurately describe the relationship between
To accurately describe the relationship between 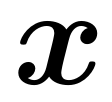 and
and 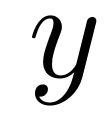 in the training set and test set. Among them,
in the training set and test set. Among them, 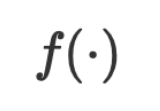 is a function based on numerical values. Its parameters
is a function based on numerical values. Its parameters  are usually numerical vectors or matrices in continuous space. The optimization algorithm iteratively updates
are usually numerical vectors or matrices in continuous space. The optimization algorithm iteratively updates  by calculating the numerical gradient to achieve the learning effect. Instead of using numerical values, can we use natural language to represent a model? How to perform inference and training on this non-numerical model based on natural language? Verbalized Machine Learning (VML; Verbalized Machine Learning) answers these questions and proposes a new paradigm of machine learning based on natural language. VML treats the large language model (LLM) as a universal function approximator
by calculating the numerical gradient to achieve the learning effect. Instead of using numerical values, can we use natural language to represent a model? How to perform inference and training on this non-numerical model based on natural language? Verbalized Machine Learning (VML; Verbalized Machine Learning) answers these questions and proposes a new paradigm of machine learning based on natural language. VML treats the large language model (LLM) as a universal function approximator in the natural language space, and the data
in the natural language space, and the data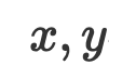 and parameters
and parameters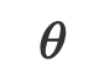 are both strings in the natural language space. When doing inference, we can submit the given input data
are both strings in the natural language space. When doing inference, we can submit the given input data 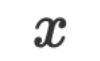 and parameters
and parameters  to LLM, and the LLM’s answer is the answer to the inference
to LLM, and the LLM’s answer is the answer to the inference 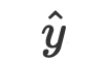 .For arbitrary tasks and data
.For arbitrary tasks and data 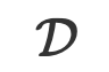 , how do we get
, how do we get  ? In traditional machine learning based on numerical values, we update the existing model parameters in the direction of decreasing loss by calculating the gradient of the loss function, thereby obtaining the optimization function of
? In traditional machine learning based on numerical values, we update the existing model parameters in the direction of decreasing loss by calculating the gradient of the loss function, thereby obtaining the optimization function of  :
: 
where 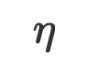 and
and 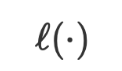 are the learning rate and loss function respectively. In the setting of VML, since the data
are the learning rate and loss function respectively. In the setting of VML, since the data  and parameters
and parameters  are both strings and LLM is regarded as a black-box inference engine, we cannot optimize
are both strings and LLM is regarded as a black-box inference engine, we cannot optimize  through numerical calculations. But since we have used LLM as a general approximation function in natural language space to approximate the model function, and the optimizer of
through numerical calculations. But since we have used LLM as a general approximation function in natural language space to approximate the model function, and the optimizer of  is also a function, why don’t we also use LLM to approximate it? Therefore, the verbal
is also a function, why don’t we also use LLM to approximate it? Therefore, the verbal 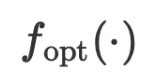 optimization function can be written as
optimization function can be written as 

, where
is the training data and model prediction results of a batch of  , and
, and 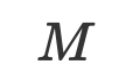 is the parameters of the optimization function (the same is natural language).
is the parameters of the optimization function (the same is natural language). 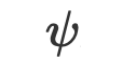


中 Figure 2: Sample samples of natural language templates of models and optimizers in VML.
Figure 1 shows the complete algorithm of VML. It can be seen that it is basically the same as the traditional machine learning algorithm. The only difference is that the data and parameters are strings in the natural language space, and the model
and optimizer both perform inference in the natural language space through LLM. Figure 2 shows specific template examples of the model
and optimizer  in the regression task.
in the regression task. 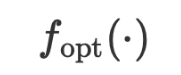

 Compared with traditional machine learning, the advantages of VML include: (1) You can add inductive bias to the model with a simple description in natural language; (2) Since there is no need to preset the function family of the model (function family), the optimizer
Compared with traditional machine learning, the advantages of VML include: (1) You can add inductive bias to the model with a simple description in natural language; (2) Since there is no need to preset the function family of the model (function family), the optimizer
can automatically select the function family of the model during the training process; (3) The optimization function will provide a natural language explanation for each update of the model parameters, and the description and reasoning of the model are also natural language and explainable.
As shown in Figure 3, the initial parameter of the model is the definition of linear regression. During the first step of optimization, the optimizer said that it found that had a larger range of values than
, and they seemed to be positively correlated, so it decided to update the model to a simple linear regression model.In the second step of optimization, the optimizer said that the poor performance of the current model made it realize that the assumption of the linear model was too simple, and it found that there was a non-linear relationship between  and
and  , so it decided to change the model Updated to a quadratic function. In the third step of optimization, the optimizer’s focus shifts from function family selection to parameter modification of the quadratic function. The final model learns a result that is very close to the real function.在 Figure 3: The training process record of VML in the multi -split regression mission.
, so it decided to change the model Updated to a quadratic function. In the third step of optimization, the optimizer’s focus shifts from function family selection to parameter modification of the quadratic function. The final model learns a result that is very close to the real function.在 Figure 3: The training process record of VML in the multi -split regression mission. 
Nonlinear two-dimensional plane classification As shown in Figure 4, the initial parameters of the model are the definition of two-dimensional plane binary classification, and the sentence "decision boundary" is used It's a circle" and add inductive bias. In the first step of optimization, the optimizer says it updates the model to a circle equation based on the provided prior. In the next optimization steps, the optimizer adjusts the center and radius of the circle equation based on the training data. Until step 41, the optimizer said that the current model seemed to fit well, so it stopped updating the model.
At the same time, we can also see that VML can also learn a good model based on decision trees without adding inductive bias, but the training loss fluctuates more in comparison.
 Figure 4: Record of the training process of VML in the nonlinear two-dimensional plane classification task. Medical image binary classificationIf the large model accepts multi-modal input, such as pictures and text, then VML can also be used for image tasks. In this experiment, we used the GPT-4o and PneumoniaMNIST data sets to perform an X-ray pneumonia detection task. As shown in Figure 5, we initialized two models. The initial parameters of the models
Figure 4: Record of the training process of VML in the nonlinear two-dimensional plane classification task. Medical image binary classificationIf the large model accepts multi-modal input, such as pictures and text, then VML can also be used for image tasks. In this experiment, we used the GPT-4o and PneumoniaMNIST data sets to perform an X-ray pneumonia detection task. As shown in Figure 5, we initialized two models. The initial parameters of the models  are both defined as the second classification of images, but one of them added a sentence "The input is an X-ray image used for pneumonia detection." of inductive bias as a priori. After fifty steps of training, both models reached an accuracy of about 75%, with the model with a prior being slightly more accurate. Looking carefully at the model parameters after step 50, we can see that the model description with inductive bias contains many medical words related to pneumonia, such as "infection" and "inflammation"; but not The model description with inductive bias only describes the characteristics of lung X-rays, such as "transparency" and "symmetry". At the same time, the descriptions learned by these models can be verified by doctors with professional knowledge. Such interpretable and human-checkable machine learning models are valuable in safety-critical medical scenarios.在 Figure 5: VML training records in pneumoniamnist pictures.
are both defined as the second classification of images, but one of them added a sentence "The input is an X-ray image used for pneumonia detection." of inductive bias as a priori. After fifty steps of training, both models reached an accuracy of about 75%, with the model with a prior being slightly more accurate. Looking carefully at the model parameters after step 50, we can see that the model description with inductive bias contains many medical words related to pneumonia, such as "infection" and "inflammation"; but not The model description with inductive bias only describes the characteristics of lung X-rays, such as "transparency" and "symmetry". At the same time, the descriptions learned by these models can be verified by doctors with professional knowledge. Such interpretable and human-checkable machine learning models are valuable in safety-critical medical scenarios.在 Figure 5: VML training records in pneumoniamnist pictures. 
 ConclusionThis article introduces a new machine learning paradigm Verbalized Machine Learning (VML; Verbalized Machine Learning) based on large language models, and in regression It demonstrates the effectiveness and interpretability of VML on classification tasks.
ConclusionThis article introduces a new machine learning paradigm Verbalized Machine Learning (VML; Verbalized Machine Learning) based on large language models, and in regression It demonstrates the effectiveness and interpretability of VML on classification tasks. The above is the detailed content of Can machine learning be done purely by talking without doing numerical calculations? A new ML paradigm based on natural language is coming. For more information, please follow other related articles on the PHP Chinese website!



 are usually numerical vectors or matrices in continuous space. The optimization algorithm iteratively updates
are usually numerical vectors or matrices in continuous space. The optimization algorithm iteratively updates  to LLM, and the LLM’s answer is the answer to the inference
to LLM, and the LLM’s answer is the answer to the inference  and parameters
and parameters 

 and
and  , so it decided to change the model Updated to a quadratic function.
, so it decided to change the model Updated to a quadratic function. 
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



