

DiT can be used to generate videos with no quality loss and no training required.
Real-time AI video generation is here!
On Wednesday, the team of You Yang from the National University of Singapore proposed the industry's first DiT-based video generation method that can be output in real time.

The technology is called Pyramid Attention Broadcast (PAB). By reducing redundant attention computations, PAB achieves frame rates up to 21.6 FPS and 10.6x speedup without sacrificing the benefits of popular DiT-based video generation models including Open-Sora, Open-Sora-Plan, and Latte. quality. It is worth noting that, as a method that does not require training, PAB can provide acceleration for any future DiT-based video generation model, giving it the ability to generate real-time video.
Since this year, OpenAI’s Sora and other DiT-based video generation models have caused another wave in the field of AI. However, compared with image generation, people's focus on video generation is basically on quality, and few studies have focused on exploring how to accelerate DiT model inference. Accelerating the inference of video generative models is already a priority for generative AI applications.
The emergence of the PAB method has opened a way for us. Comparison of original method and PAB video generation speed. The author tested 5 4s (192 frames) 480p resolution videos on Open-Sora. 
pyramid attention broadcast
Recently, Sora and other DiT-based video generation models have attracted widespread attention. However, compared to image generation, few studies have focused on accelerating the inference of DiT-based video generation models. Furthermore, the inference cost of generating a single video can be high.散 Figure 1: Differences between the current diffusion steps and the previous diffusion steps, and the differential error (MSE) is quantified.Implementation
This study reveals two key observations of the attention mechanism in the video diffusion transformer: First, the difference in attention at different time steps exhibits a U-shaped pattern, at the initial and last 15 % of steps change significantly, while the middle 70% of steps are very stable with small differences.
First, the difference in attention at different time steps exhibits a U-shaped pattern, at the initial and last 15 % of steps change significantly, while the middle 70% of steps are very stable with small differences.
Secondly, within the stable middle segment, there are differences between attention types: spatial attention changes the most, involving high-frequency elements such as edges and textures; temporal attention shows mid-frequency changes related to motion and dynamics in the video ; Cross-modal attention is the most stable, connecting text with video content, similar to low-frequency signals reflecting text semantics. Based on this, the research team proposed pyramid attention broadcasting to reduce unnecessary attention calculations. In the middle part, attention shows small differences, and the study broadcasts the attention output of one diffusion step to several subsequent steps, thereby significantly reducing the computational cost. In addition, for more efficient calculation and minimal quality loss, the author sets different broadcast ranges according to the stability and difference of different attentions. Even without post-training, this simple yet effective strategy achieves speedups of up to 35% with negligible quality loss in the generated content.
Figure 2: This study proposes a pyramid attention broadcast, in which different broadcast ranges are set for three attentions based on attention differences. The smaller the change in attention, the wider the broadcast range. At runtime, the method broadcasts the attention results to the next few steps to avoid redundant attention computations. x_t refers to the features at time step t.
Parallel
Figure 3 below shows the comparison between the method in this article and the original Dynamic Sequence Paralle (DSP). When temporal attention is spread, all communication can be avoided.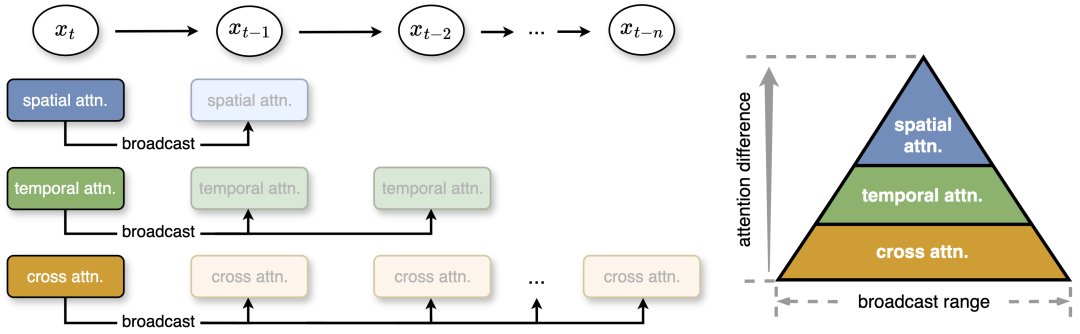
In order to further improve the speed of video generation, this article uses DSP to improve sequence parallelism. Sequence Parallel splits the video into different parts across multiple GPUs, reducing the workload on each GPU and lowering build latency. However, DSP introduces a large amount of communication overhead, requiring time and attention to prepare two All-to-All communications.
By propagating temporal attention in PAB, this article no longer needs to calculate temporal attention, thereby reducing communication. Correspondingly, the communication overhead is significantly reduced by more than 50%, enabling more efficient distributed inference for real-time video generation.
Evaluation results
Acceleration
The following figure shows the total PAB latency measured by different models when generating a single video on 8 NVIDIA H100 GPUs. When using a single GPU, the authors achieved a speedup of 1.26 to 1.32x and remained stable across different schedulers.
When extended to multiple GPUs, this method achieved a 10.6x acceleration, and benefited from efficient sequential parallelism improvements to achieve near-linear expansion with the number of GPUs.

Qualitative results
The following three videos are respectively Open-Sora, Open-Sora-Plan and Latte. Three different models use the original method to compare the effects of the method in this article. It can be seen that the method in this article achieves different degrees of FPS acceleration under different numbers of GPUs. 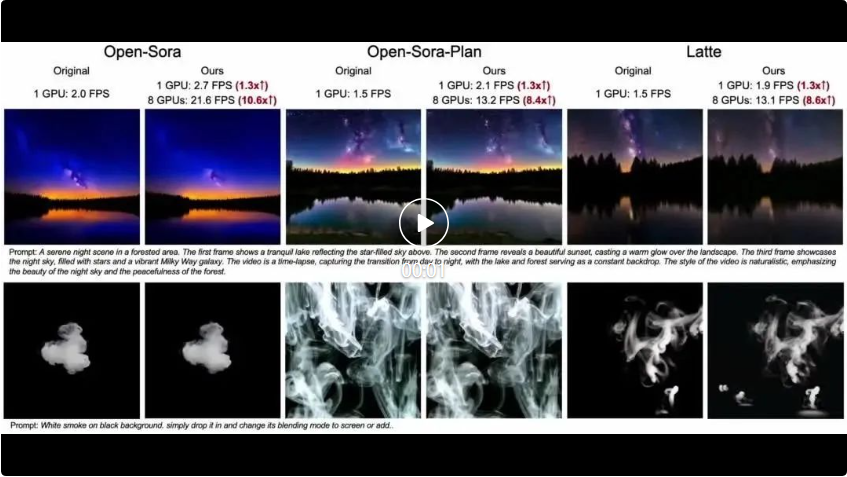

Quantitative results
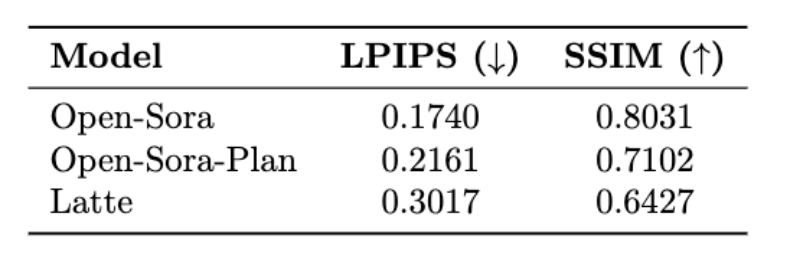
The following table shows the LPIPS (Learning Perceptual Image Patch Similarity) and SSIM (Structural Similarity) of the three models of Open-Sora, Open-Sora-Plan and Latte ) indicator results.
More technical details and evaluation results can be found in the upcoming paper.
Project address: https://oahzxl.github.io/PAB/
Reference link:
https://oahzxl.github.io/PAB/
The above is the detailed content of The first real-time AI video generation technology in history: DiT universal, 10.6 times faster. For more information, please follow other related articles on the PHP Chinese website!
 What is mobile phone HD?
What is mobile phone HD?
 What are the domain name error correction systems?
What are the domain name error correction systems?
 How to run code with vscode
How to run code with vscode
 How to use php sleep
How to use php sleep
 Introduction to laravel components
Introduction to laravel components
 What are the electronic contract signing platforms?
What are the electronic contract signing platforms?
 How to round in Matlab
How to round in Matlab
 What are the virtual currency trading platforms?
What are the virtual currency trading platforms?
 Convert text to numeric value
Convert text to numeric value








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



