Meta has developed an awesome LLM Compiler to help programmers write code more efficiently.
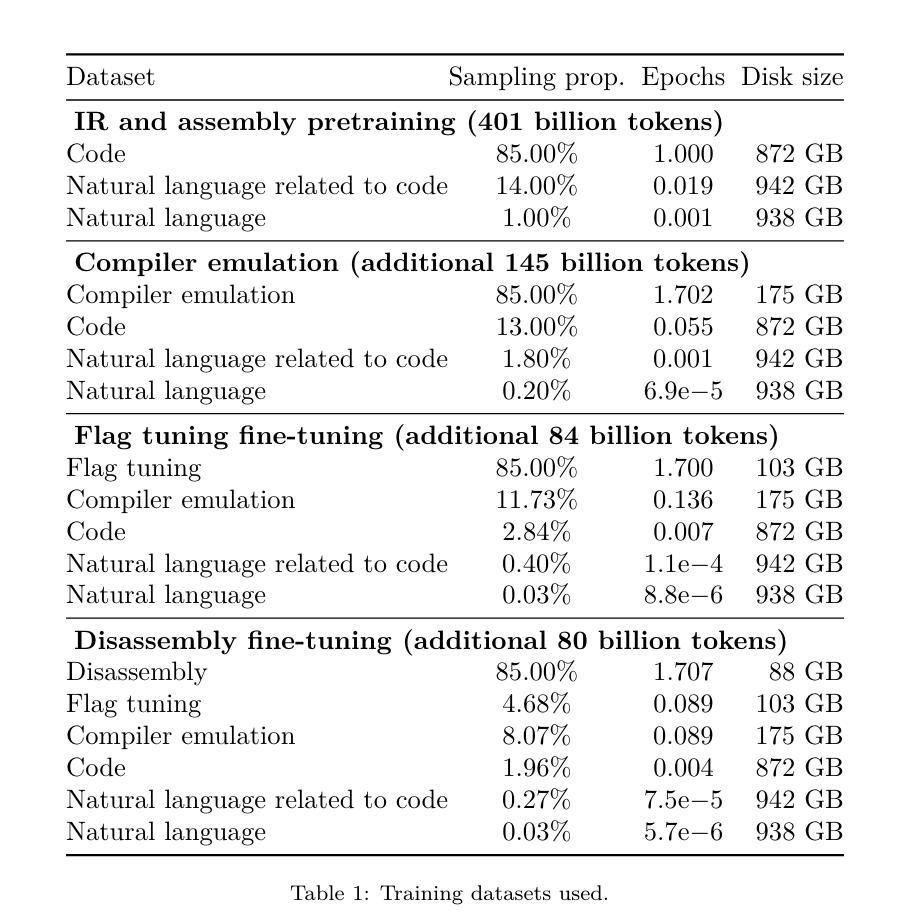
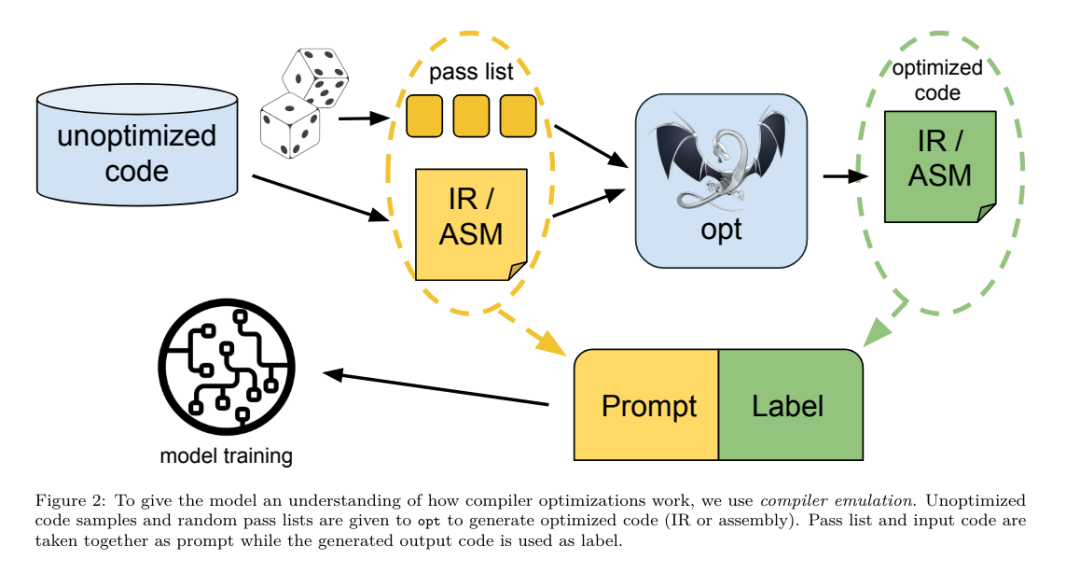
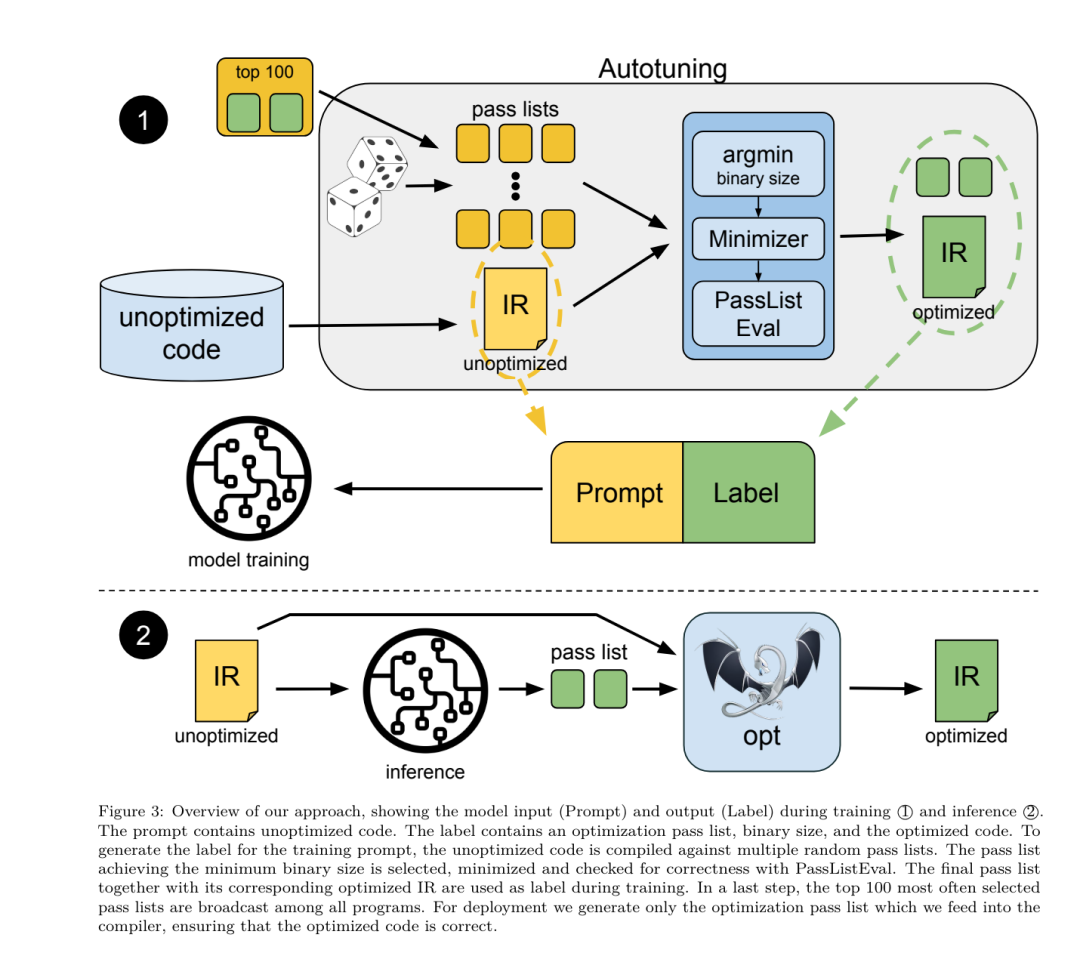
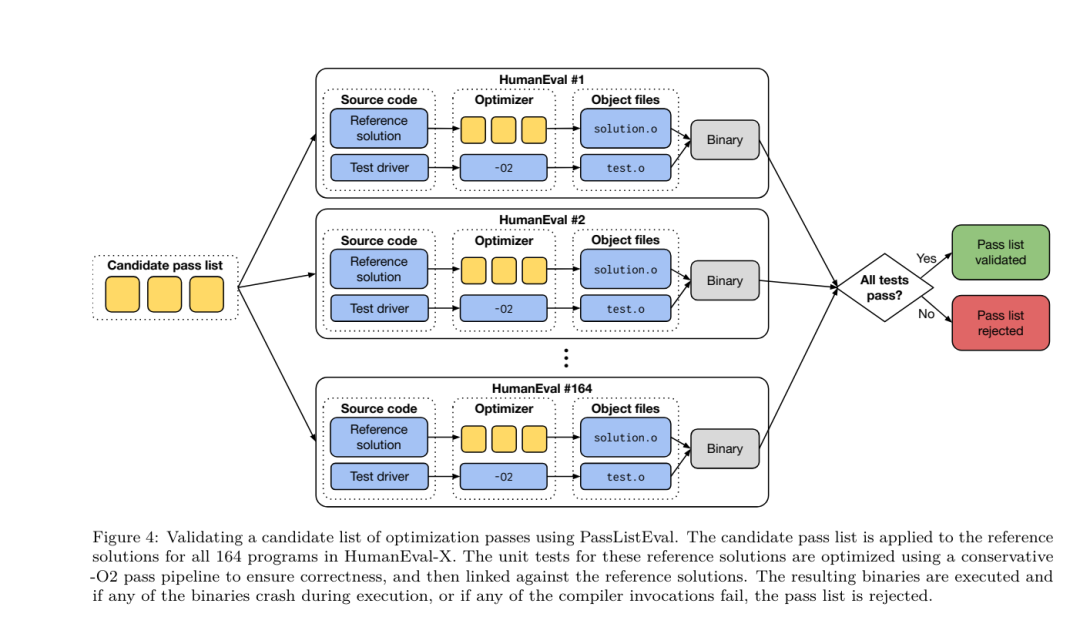
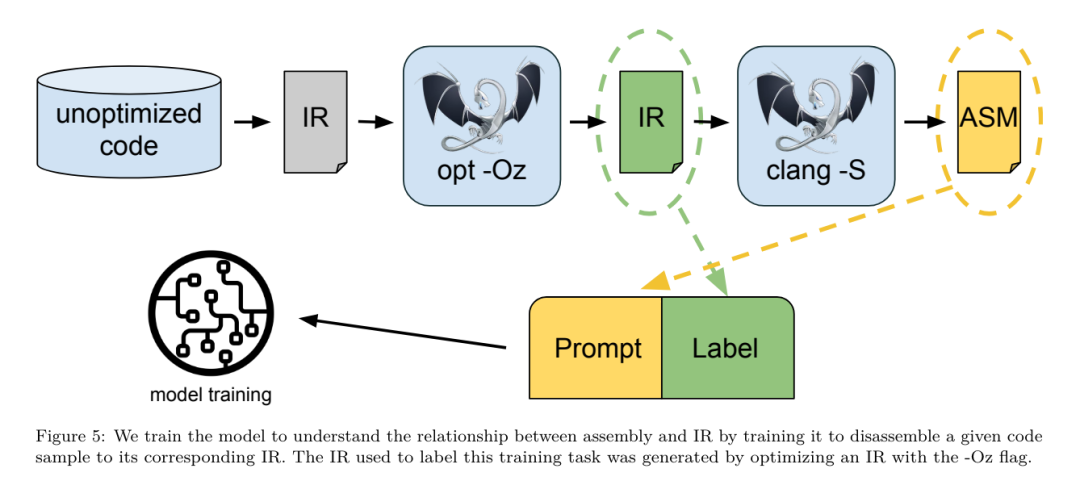
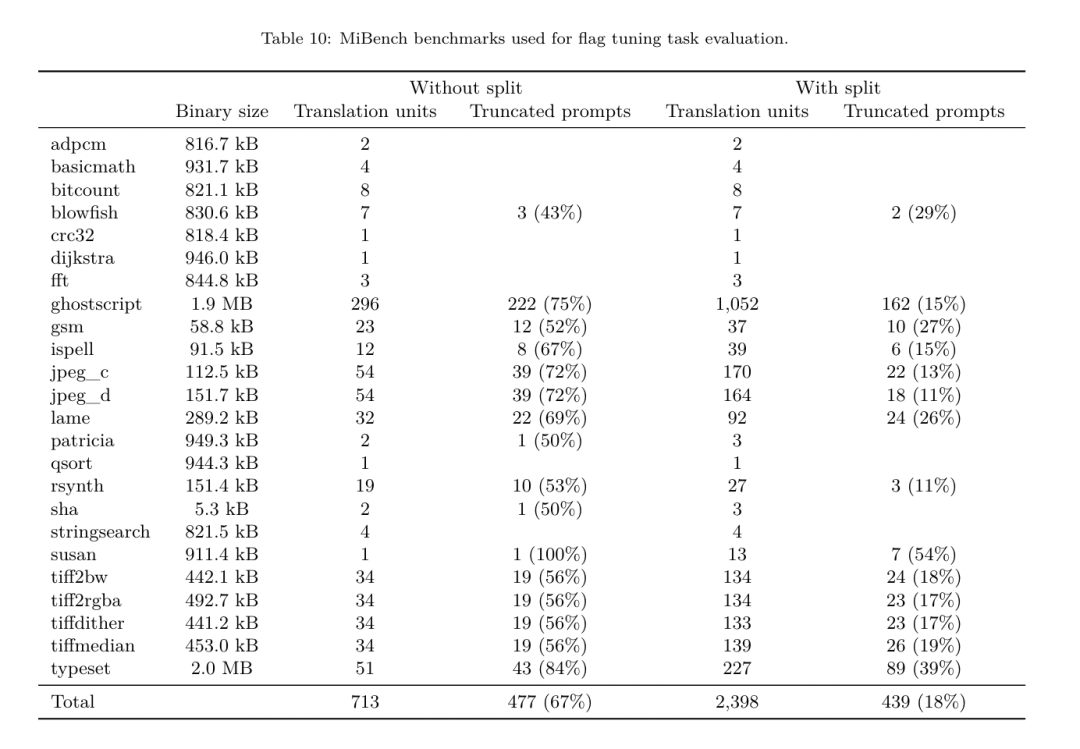
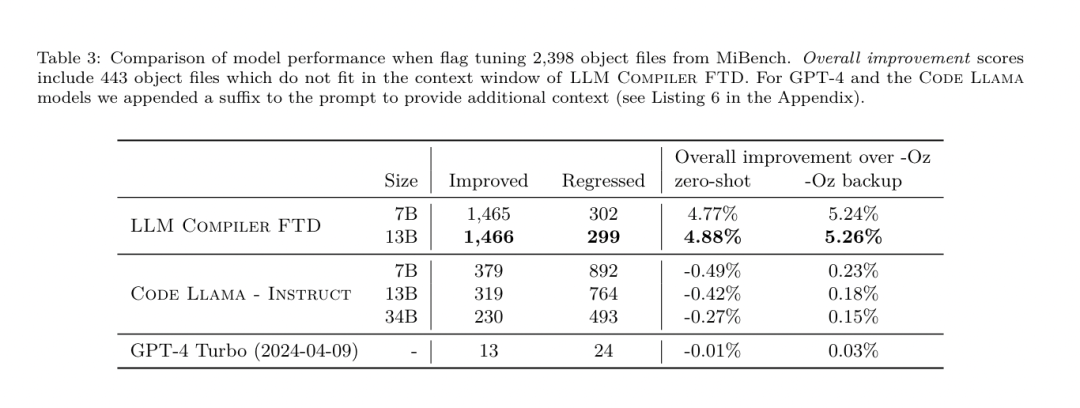
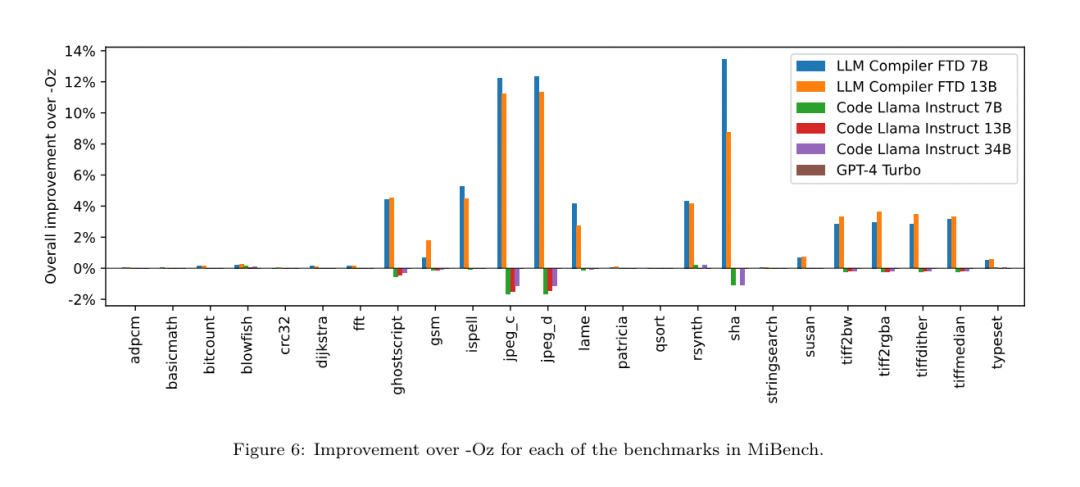
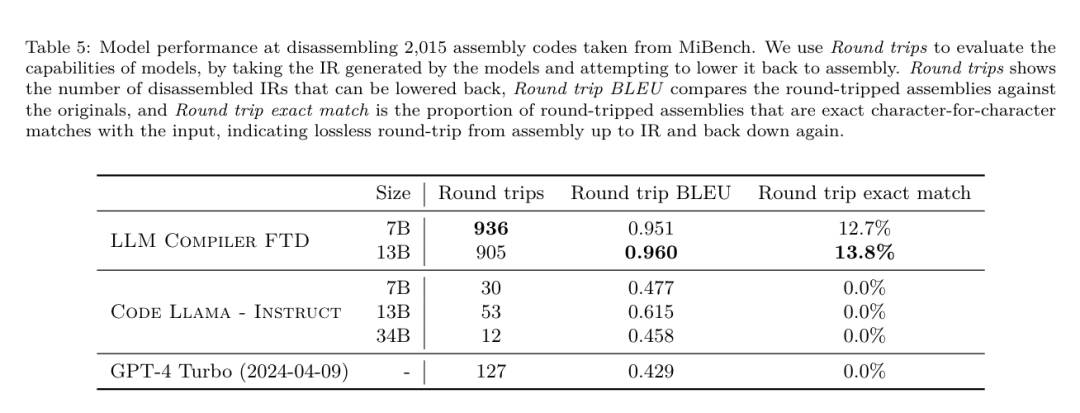
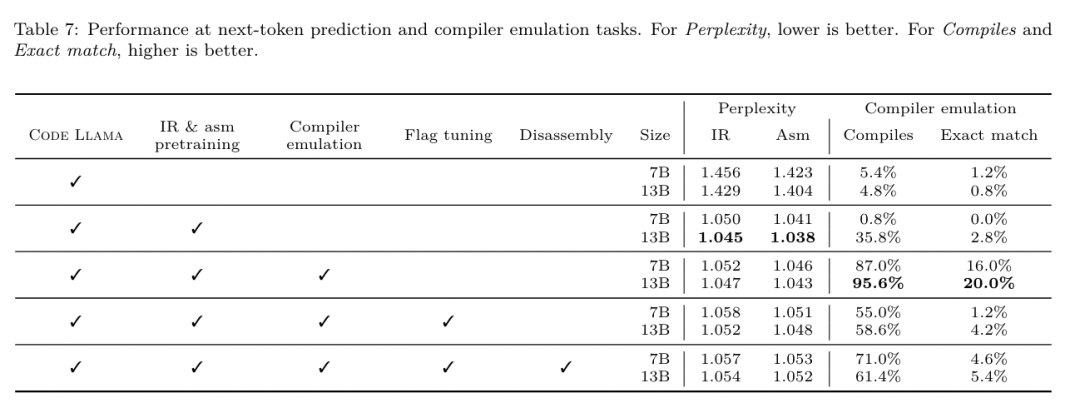
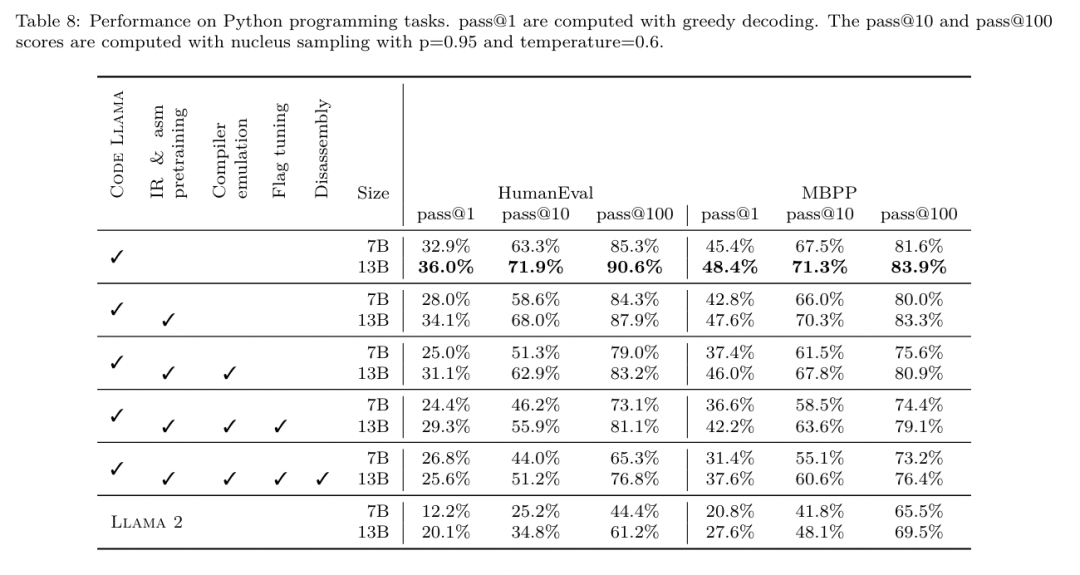
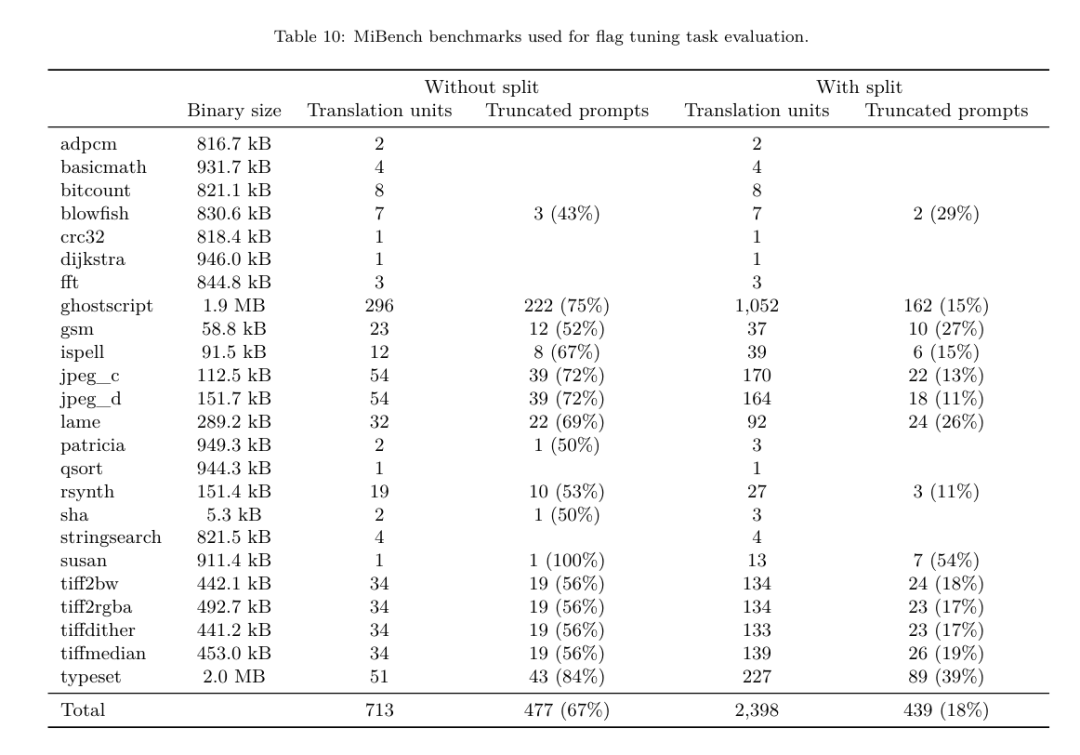
Yesterday, the three major AI giants OpenAI, Google, and Meta teamed up to release the latest research results of their own large models - OpenAI launched a new model CriticGPT based on GPT-4 training that specializes in finding bugs, Google Open source 9B and 27B versions of Gemma2, and Meta has come up with the latest artificial intelligence breakthrough-LLM Compiler. This is a powerful set of open source models designed to optimize code and revolutionize compiler design. This innovation has the potential to change the way developers approach code optimization, making it faster, more efficient, and more cost-effective. It is reported that the optimization potential of the LLM Compiler reaches 77% of automatic tuning searches. This result can significantly reduce compilation time and improve the code efficiency of various applications. In terms of disassembly, its round trip The success rate of disassembly is 45%. Some netizens said that this is like a game changer for code optimization and disassembly. This is incredibly good news for developers. Large language models have shown excellent capabilities in many software engineering and programming tasks, but their application in the field of code optimization and compilers has not been fully explored. Training these LLMs requires extensive computing resources, including expensive GPU time and large datasets, which often makes many research and projects unsustainable. To fill this gap, the Meta research team introduced an LLM Compiler to specifically optimize code and revolutionize compiler design. By training the model on a massive corpus of 546 billion tokens of LLVM-IR and assembly code, they enabled the model to understand compiler intermediate representations, assembly language, and optimization techniques. Paper link: https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/Researchers at “LLM Compiler provides enhanced understanding of compiler intermediate representations (IRs), assembly language, and optimization techniques,” their paper explains. This enhanced understanding enables models to perform tasks previously restricted to human experts or specialized tools. The training process of LLM Compiler is shown in Figure 1. LLM Compiler achieves significant results in code size optimization. In tests, the model's optimization potential reached 77% of the automated tuning search, a result that can significantly reduce compilation times and improve code efficiency for a variety of applications. The model is better at disassembly. LLM Compiler achieves a 45% round-trip disassembly success rate (14% of which are exact matches) when converting x86_64 and ARM assembly code back to LLVM-IR. This ability can be invaluable for reverse engineering tasks and legacy code maintenance. One of the core contributors to the project, Chris Cummins, highlighted the potential impact of this technology: “By providing pre-trained models in two sizes (700 million and 1.3 billion parameters) and demonstrating its effectiveness through fine-tuned versions, "LLM Compiler paves the way to explore the untapped potential of LLM in the field of code and compiler optimization," he said. Pre-training on assembly code and compiler IR The data used to train programming LLMs usually mainly consists of high-level source languages like Python, assembly code accounts for a negligible proportion in these data sets, and compiler IR accounts for smaller.In order to build an LLM with good understanding of these languages, the research team initialized the LLM Compiler model with the weights of Code Llama, and then trained 401 billion tokens on a compiler-centric dataset. This dataset It mainly consists of assembly code and compiler IR, as shown in Table 1. Dataset LLM Compiler is mainly trained on the compiler intermediate representation and assembly code generated by LLVM (version 17.0.6). These data are derived from the same dataset used to train Code Llama, which has been reported in Table 2 The dataset is outlined in . Like Code Llama, we also obtain small training batches from natural language datasets.  Instruction fine-tuning for compiler simulationIn order to understand the mechanism of code optimization, the research team performed instruction fine-tuning on the LLM Compiler model to simulate compiler optimization, as shown in Figure 2. The idea is to generate a large number of examples from a limited collection of unoptimized seed programs by applying randomly generated sequences of compiler optimizations to these programs. They then trained the model to predict the code generated by the optimization, and also trained the model to predict the code size after applying the optimization. Task specifications. Given unoptimized LLVM-IR (output by the clang frontend), a list of optimization passes, and a starting code size, generate the resulting code and code size after applying these optimizations. There are two types of this task: in the first, the model expects to output a compiler IR; in the second, the model expects to output assembly code. The input IR, optimization process and code size are the same for both types, and the hint determines the required output format. Code size. They use two metrics to measure code size: number of IR instructions and binary size. Binary size is calculated as the sum of the .TEXT and .DATA segment sizes after downgrading the IR or assembly to an object file. We exclude the .BSS segment because it does not affect the size on disk. Optimize pass. In this work, the research team targets LLVM 17.0.6 and uses the new process manager (PM, 2021), which classifies passes into different levels, such as modules, functions, loops, etc., as well as converts and analyzes passes . A transformation pass changes a given input IR, while an analysis pass generates information that affects subsequent transformations. Out of 346 possible pass parameters for opt, they chose 167 to use. This includes every default optimization pipeline (e.g. module (default)), individual optimization transformation passes (e.g. module (constmerge)), but excludes non-optimizing utility passes (e.g. module (dot-callgraph)) and does not preserve semantics conversion pass (such as module (internalize)). They exclude analysis passes because they have no side effects and we rely on the pass manager to inject dependent analysis passes as needed. For passes that accept parameters, we use default values (e.g. module (licm)). Table 9 contains a list of all passes used. We apply the pass list using LLVM's opt tool and downgrade the resulting IR to an object file using clang. Listing 1 shows the commands used. dataset. The research team generated a compiler simulation dataset by applying a list of 1 to 50 random optimization passes to the unoptimized program summarized in Table 2. The length of each pass list is chosen uniformly and randomly. The pass list is generated by uniformly sampling from the above 167 pass set. Pass lists that cause the compiler to crash or timeout after 120 seconds are excluded. LLM Compiler FTD: Extend downstream compilation tasks Instruction fine-tuning for optimization flag tuningManipulating compiler flags has a significant impact on runtime performance and code size. The research team trained the LLM Compiler FTD model to perform the downstream task of selecting flags for LLVM's IR optimization tool opt to produce the smallest code size. Flag-tuned machine learning methods have previously shown good results, but have had difficulties with generalization across different programs.Previous work often required compiling new programs dozens or hundreds of times to try different configurations and find the best-performing option. The research team trained and evaluated the LLM Compiler FTD model on a zero-shot version of this task by predicting flags to minimize the code size of unseen programs. Their approach does not depend on the chosen compiler and optimization metrics, and they intend to target runtime performance in the future. Currently, optimizing code size simplifies the collection of training data. Task specifications. The research team presented an unoptimized LLVM-IR (generated by the clang frontend) to the LLM Compiler FTD model and asked it to generate a list of opt flags that should be applied, the binary size before and after these optimizations are applied, and the output code if it cannot be used on the input code Improvements are made to produce a short output message containing only the unoptimized binary size. They used the same set of restricted optimization passes as the compiler simulation task and calculated the binary size in the same way. Figure 3 illustrates the process used to generate training data and how the model is used at inference time. Only the generated pass list is needed during evaluation. They extract the pass list from the model output and run opt with the given parameters. Researchers can then evaluate the accuracy of the model's predicted binary size and optimize the output code, but these are auxiliary learning tasks and are not required for use. Correctness. The LLVM optimizer is not infallible, and running optimization passes in an unexpected or untested order can expose subtle correctness errors that reduce the usefulness of the model. To mitigate this risk, the research team developed PassListEval, a tool to help automatically identify pass lists that break program semantics or cause compilers to crash. Figure 4 shows an overview of the tool. PassListEval accepts as input a list of candidate passes and evaluates it on a suite of 164 self-testing C++ programs, taken from HumanEval-X. Each program contains a reference solution to a programming challenge, such as "check if the distance between two numbers in a given vector of numbers is less than a given threshold", as well as a suite of unit tests to verify correctness. They apply the list of candidate passes to reference solutions and then link them with test suites to generate binaries. While executing, if any test fails, the binary will crash. If any binary crashes, or any compiler call fails, we reject the candidate pass list. Dataset. The team trained the LLM Compiler FTD model on a flag-tuned example dataset derived from 4.5 million unoptimized IRs used for pretraining. To generate the best pass list examples for each program, they performed an extensive iterative compilation process, as shown in Figure 3. 1. The research team uses large-scale random search to generate an initial candidate best pass list for the program. For each program, they independently generated a random list of up to 50 passes, uniformly sampled from the previously described set of 167 searchable passes. Each time they evaluated a program's pass list, they recorded the resulting binary size, and then selected each program's pass list that produced the smallest binary size. They ran 22 billion independent compilations, an average of 4,877 per program. 2. The pass list generated by random search may contain redundant passes, which have no impact on the final result. Additionally, some pass orders are interchangeable and reordering will not affect the final result. Since these introduce noise into the training data, they developed a minimization process and applied it to each pass list. Minimization includes three steps: redundant pass elimination, bubble sorting and insertion search. In redundant pass elimination, they minimize the optimal pass list by iteratively removing individual passes to see if they contribute to the binary size, and if not, discard them. Repeat this process until no more passes can be dropped. Bubble sort then attempts to provide a unified ordering for pass subsequences, sorting passes based on keywords. Finally, insertion sort performs a local search by looping through each pass in the pass list and trying to insert each of the 167 search passes before it. If doing so improves binary size, keep this new pass list. The entire minimization pipeline is looped until a fixed point is reached. The minimized pass list length distribution is shown in Figure 9. The average pass list length is 3.84.3. They apply the previously described PassListEval to the list of candidate best passes. In this way, they identified 167,971 out of 1,704,443 unique pass lists (9.85%) that would cause compile-time or run-time errors 4. They broadcast the 100 most common optimal pass lists to all program, and update the best pass list for each program if improvements are found. Afterwards, the total number of single best pass lists was reduced from 1,536,472 to 581,076. The above auto-tuning pipeline produced a 7.1% geometric mean binary size reduction compared to -Oz. Figure 10 shows the frequency of a single pass. To them, this automatic tuning serves as the gold standard for every program optimization. While the binary size savings found are significant, this required 28 billion additional compilations at a computational cost of over 21,000 CPU days. The goal of instruction fine-tuning of the LLM Compiler FTD to perform flag tuning tasks is to achieve a fraction of the auto-tuner performance without having to run the compiler thousands of times. Instruction fine-tuning for disassembly Lifts code from assembly language to a higher-level structure that can run additional optimizations, such as library code integrated directly into application code, or Port legacy code to new architecture. The field of decompilation has made progress in applying machine learning techniques to generate readable and accurate code from binary executables. In this study, the research team shows how LLM Compiler FTD can learn the relationship between assembly code and compiler IR by fine-tuning disassembly. The task is to learn the inverse translation of clang -xir - -o - -S, as shown in Figure 5. Round trip test. Using LLM for disassembly can cause correctness issues. Boosted code must be verified with an equivalence checker, which is not always possible, or requires manual verification of correctness, or sufficient test cases to gain confidence. However, a lower bound on correctness can be found through round-trip testing. That is, by recompiling the lifted IR into assembly code, if the assembly code is the same, the IR is correct. This provides a simple path to using the results of LLM and is a simple way to measure the utility of the disassembled model. Task specifications. The research team fed the model assembly code and trained it to emit corresponding disassembly IRs. The context length for this task was set to 8k tokens for the input assembly code and 8k tokens for the output IR. Dataset. They derived assembly code and IR pairs from the dataset used in previous tasks. Their fine-tuning dataset contains 4.7 million samples, and the input IR has been optimized using -Oz before being reduced to x86 assembly. The data is tokenized via byte pair encoding, using the same tokenizer as Code Llama, Llama and Llama 2. They use the same training parameters for all four training phases. They used most of the same training parameters as the Code Llama base model, using the AdamW optimizer with values of 0.9 and 0.95 for β1 and β2. They used cosine scheduling with a warm-up step of 1000 steps and set the final learning rate to 1/30 of the peak learning rate. Compared to the Code Llama base model, the team increased the context length of a single sequence from 4096 to 16384 but kept the batch size constant at 4 million tokens. To accommodate longer contexts, they set the learning rate to 2e-5 and modified the parameters of the RoPE position embedding, where they reset the frequency to the base value θ=10^6. These settings are consistent with long-context training of the Code Llama base model. The research team evaluates the performance of the LLM Compiler model on flag tuning and disassembly tasks, compiler simulation, next token prediction, and software engineering tasks. Method. They evaluate the performance of LLM Compiler FTD on the task of tuning optimization flags for unseen programs and compare it with GPT-4 Turbo and Code Llama - Instruct. They run inference on each model and extract a list of optimization passes from the model output. They then use this pass list to optimize a specific program and record the binary size. The baseline is the binary size of the program when optimized with -Oz. For GPT-4 Turbo and Code Llama - Instruct, they append a suffix after the prompt to provide additional context to further describe the problem and expected output format.All pass lists generated by the model are verified using PassListEval, and -Oz is used as an alternative if verification fails. To further verify the correctness of the pass list generated by the model, they linked the final program binary and differentially tested its output against the benchmark output optimized using a conservative -O2 optimization pipeline. Dataset. The research team conducted the evaluation using 2,398 test cues extracted from the MiBench benchmark suite. To generate these hints, they take all 713 translation units that make up the 24 MiBench benchmarks and generate unoptimized IRs from each unit, then format them into hints. If the generated hints exceed 15k tokens, they use llvm-extract to split the LLVM module representing that translation unit into smaller modules, one per function, which results in 1,985 hints that fit into the 15k token context window, leaving 443 translation units Not suitable. When calculating performance scores, they used -Oz for the 443 excluded translation units. Table 10 summarizes the benchmarks. Results. Table 3 shows the zero-shot performance of all models on the flag tuning task. Only the LLM Compiler FTD model improved over -Oz, with the 13B parameter model slightly outperforming the smaller model, producing smaller object files than -Oz in 61% of the cases. In some cases, the pass list generated by the model resulted in a larger target file size than -Oz. For example, LLM Compiler FTD 13B has degradation in 12% of cases. These degradations can be avoided by simply compiling the program twice: once with the pass list generated by the model, and once with -Oz, then selecting the pass list that yields the best results. By eliminating degradation relative to -Oz, these -Oz backup scores increase the overall improvement of LLM Compiler FTD 13B relative to -Oz to 5.26%, and enable Code Llama - Instruct and GPT-4 Turbo to achieve modest improvements relative to -Oz . Figure 6 shows the performance breakdown of each model on various benchmarks. Binary size accuracy. While the binary size predictions generated by the model have no impact on actual compilation, the research team can evaluate the model's performance in predicting binary size before and after optimization to understand how well each model understands the optimization. Figure 7 shows the results. LLM Compiler FTD’s binary size predictions correlate well with the actual situation, with the 7B parameter model achieving MAPE values of 0.083 and 0.225 for unoptimized and optimized binary sizes, respectively. The MAPE values for the 13B parameter model were similar, 0.082 and 0.225, respectively. Code Llama - Instruct and GPT-4 Turbo's binary size predictions have little correlation with reality. The researchers noticed that LLM Compiler FTD had slightly higher errors for optimized code than for unoptimized code. In particular, LLM Compiler FTD occasionally has a tendency to overestimate the effectiveness of optimization, resulting in predicted binary sizes that are lower than they actually are. Ablation research. Table 4 presents an ablation study of the model's performance on a small hold-out validation set of 500 cues from the same distribution as their training data (but not used in training). They performed flag-tuned training at each stage of the training pipeline shown in Figure 1 to compare performance. As shown, disassembly training resulted in a slight performance drop from an average of 5.15% to 5.12% (improvement over -Oz). They also demonstrate the performance of the autotuner used to generate the training data described in Section 2. LLM Compiler FTD achieves 77% of the performance of the autotuner. method. The research team evaluates the functional correctness of LLM-generated code when disassembling assembly code into LLVM-IR. They evaluate LLM Compiler FTD and compare it with Code Llama - Instruct and GPT-4 Turbo and find that additional hint suffixes are needed to extract the best performance from these models. The suffix provides additional context about the task and expected output format. To evaluate the performance of the model, they round-trip downgraded the disassembly IR generated by the model back to assembly. This allows us to evaluate the accuracy of the disassembly by comparing the BLEU scores of the original assembly with the round-trip results.A lossless perfect disassembly from assembly to IR will have a round-trip BLEU score of 1.0 (exact match). Dataset. They evaluated using 2,015 test hints extracted from the MiBench benchmark suite, taking the 2,398 translation units used for the above flag tuning evaluation, to generate disassembly hints. They then filtered the tips based on the maximum 8k token length, allowing 8k tokens for model output, leaving 2,015. Table 11 summarizes the benchmarks. Results. Table 5 shows the performance of the model on the disassembly task. LLM Compiler FTD 7B has a slightly higher round-trip success rate than LLM Compiler FTD 13B, but LLM Compiler FTD 13B has the highest round-trip assembly accuracy (round-trip BLEU) and most frequently produces perfect disassemblies (round-trip exact match). Code Llama - Instruct and GPT-4 Turbo have difficulty generating syntactically correct LLVM-IR. Figure 8 shows the distribution of round-trip BLEU scores for all models. Ablation research. Table 6 presents an ablation study of the model's performance on a small hold-out validation set of 500 cues, taken from the MiBench dataset used previously. They performed disassembly training at each stage of the training pipeline shown in Figure 1 to compare performance. The round-trip rate is highest when going through the entire training data stack and continues to decrease with each training stage, although the round-trip BLEU changes little at each stage. method. The research team conducted ablation research on the LLM Compiler model on two basic model tasks: next token prediction and compiler simulation. They perform this evaluation at each stage of the training pipeline to understand how training for each successive task affects performance. For next token prediction, they compute perplexity on a small sample of LLVM-IR and assembly code at all optimization levels. They evaluate compiler simulations using two metrics: whether the generated IR or assembly code compiles, and whether the generated IR or assembly code exactly matches what the compiler produces. Dataset. For next token prediction, they use a small holdout validation dataset from the same distribution as our training data but not used for training. They use a mix of optimization levels, including unoptimized code, code optimized with -Oz, and randomly generated pass lists. For compiler simulations, they were evaluated using 500 tips generated from MiBench using randomly generated pass lists in the manner described in Section 2.2. Results. Table 7 shows the performance of LLM Compiler FTD on two base model training tasks (next token prediction and compiler simulation) across all training stages. Next token prediction performance rises sharply after Code Llama, which barely sees IR and assembly, and drops slightly with each subsequent fine-tuning stage. For compiler simulations, the Code Llama base model and pre-trained models do not perform well because they are not trained on this task. Maximum performance is achieved directly after compiler simulation training, where 95.6% of IRs and assemblies generated by LLM Compiler FTD 13B compile and 20% match the compiler exactly. After doing flag tuning and disassembly fine-tuning, performance dropped. Software Engineering TasksMethods. While the purpose of LLM Compiler FTD is to provide a base model for code optimization, it is built on top of the base Code Llama model trained for software engineering tasks. To evaluate how additional training of LLM Compiler FTD affects the performance of code generation, they used the same benchmark suite as Code Llama to evaluate LLM's ability to generate Python code from natural language prompts, such as "Write a function that finds out how to generate Python code from a given The longest chain formed by pairs of sets. They use HumanEval and MBPP benchmarks, the same as Code Llama. Results. Table 8 shows the greedy decoding performance (pass@1) for all model training stages and model sizes starting from the Code Llama base model.It also shows the model's scores on pass@10 and pass@100, which were generated with p=0.95 and temperature=0.6. Each compiler-centric training phase results in a slight degradation in Python programming abilities. On HumanEval and MBPP, pass@1 performance of LLM Compiler dropped by up to 18% and 5%, and LLM Compiler FTD dropped by up to 29% and 22% after additional flag tuning and disassembly fine-tuning. All models still outperform Llama 2 on both tasks. Meta research team has demonstrated that LLM Compiler performs well on compiler optimization tasks and provides improved understanding of compiler representation and assembly code compared to previous work, But there are still some limitations. The main limitation is the limited sequence length of the input (context window). LLM Compiler supports a context window of 16k tokens, but program code may be much longer than this. For example, when formatted as a flag tuning tip, 67% of MiBench translation units exceeded this context window, as shown in Table 10. To alleviate this problem, they split the larger translation units into separate functions, although this limits the scope of optimization that can be performed, and still 18% of the split translation units are too large for the model is too large to be accepted as input. Researchers are employing ever-increasing context windows, but limited context windows remain a common problem in LLM. The second limitation, and a problem common to all LLMs, is the accuracy of the model output. Users of LLM Compiler are recommended to evaluate their models using compiler-specific evaluation benchmarks. Given that compilers are not bug-free, any proposed compiler optimizations must be rigorously tested. When a model is decompiled into assembly code, its accuracy should be confirmed through round-tripping, manual inspection, or unit testing. For some applications, LLM generation can be restricted to regular expressions, or combined with automatic validation to ensure correctness. https://x.com/AIatMeta/status/1806361623831171318
Instruction fine-tuning for compiler simulationIn order to understand the mechanism of code optimization, the research team performed instruction fine-tuning on the LLM Compiler model to simulate compiler optimization, as shown in Figure 2. The idea is to generate a large number of examples from a limited collection of unoptimized seed programs by applying randomly generated sequences of compiler optimizations to these programs. They then trained the model to predict the code generated by the optimization, and also trained the model to predict the code size after applying the optimization. Task specifications. Given unoptimized LLVM-IR (output by the clang frontend), a list of optimization passes, and a starting code size, generate the resulting code and code size after applying these optimizations. There are two types of this task: in the first, the model expects to output a compiler IR; in the second, the model expects to output assembly code. The input IR, optimization process and code size are the same for both types, and the hint determines the required output format. Code size. They use two metrics to measure code size: number of IR instructions and binary size. Binary size is calculated as the sum of the .TEXT and .DATA segment sizes after downgrading the IR or assembly to an object file. We exclude the .BSS segment because it does not affect the size on disk. Optimize pass. In this work, the research team targets LLVM 17.0.6 and uses the new process manager (PM, 2021), which classifies passes into different levels, such as modules, functions, loops, etc., as well as converts and analyzes passes . A transformation pass changes a given input IR, while an analysis pass generates information that affects subsequent transformations. Out of 346 possible pass parameters for opt, they chose 167 to use. This includes every default optimization pipeline (e.g. module (default)), individual optimization transformation passes (e.g. module (constmerge)), but excludes non-optimizing utility passes (e.g. module (dot-callgraph)) and does not preserve semantics conversion pass (such as module (internalize)). They exclude analysis passes because they have no side effects and we rely on the pass manager to inject dependent analysis passes as needed. For passes that accept parameters, we use default values (e.g. module (licm)). Table 9 contains a list of all passes used. We apply the pass list using LLVM's opt tool and downgrade the resulting IR to an object file using clang. Listing 1 shows the commands used. dataset. The research team generated a compiler simulation dataset by applying a list of 1 to 50 random optimization passes to the unoptimized program summarized in Table 2. The length of each pass list is chosen uniformly and randomly. The pass list is generated by uniformly sampling from the above 167 pass set. Pass lists that cause the compiler to crash or timeout after 120 seconds are excluded. LLM Compiler FTD: Extend downstream compilation tasks Instruction fine-tuning for optimization flag tuningManipulating compiler flags has a significant impact on runtime performance and code size. The research team trained the LLM Compiler FTD model to perform the downstream task of selecting flags for LLVM's IR optimization tool opt to produce the smallest code size. Flag-tuned machine learning methods have previously shown good results, but have had difficulties with generalization across different programs.Previous work often required compiling new programs dozens or hundreds of times to try different configurations and find the best-performing option. The research team trained and evaluated the LLM Compiler FTD model on a zero-shot version of this task by predicting flags to minimize the code size of unseen programs. Their approach does not depend on the chosen compiler and optimization metrics, and they intend to target runtime performance in the future. Currently, optimizing code size simplifies the collection of training data. Task specifications. The research team presented an unoptimized LLVM-IR (generated by the clang frontend) to the LLM Compiler FTD model and asked it to generate a list of opt flags that should be applied, the binary size before and after these optimizations are applied, and the output code if it cannot be used on the input code Improvements are made to produce a short output message containing only the unoptimized binary size. They used the same set of restricted optimization passes as the compiler simulation task and calculated the binary size in the same way. Figure 3 illustrates the process used to generate training data and how the model is used at inference time. Only the generated pass list is needed during evaluation. They extract the pass list from the model output and run opt with the given parameters. Researchers can then evaluate the accuracy of the model's predicted binary size and optimize the output code, but these are auxiliary learning tasks and are not required for use. Correctness. The LLVM optimizer is not infallible, and running optimization passes in an unexpected or untested order can expose subtle correctness errors that reduce the usefulness of the model. To mitigate this risk, the research team developed PassListEval, a tool to help automatically identify pass lists that break program semantics or cause compilers to crash. Figure 4 shows an overview of the tool. PassListEval accepts as input a list of candidate passes and evaluates it on a suite of 164 self-testing C++ programs, taken from HumanEval-X. Each program contains a reference solution to a programming challenge, such as "check if the distance between two numbers in a given vector of numbers is less than a given threshold", as well as a suite of unit tests to verify correctness. They apply the list of candidate passes to reference solutions and then link them with test suites to generate binaries. While executing, if any test fails, the binary will crash. If any binary crashes, or any compiler call fails, we reject the candidate pass list. Dataset. The team trained the LLM Compiler FTD model on a flag-tuned example dataset derived from 4.5 million unoptimized IRs used for pretraining. To generate the best pass list examples for each program, they performed an extensive iterative compilation process, as shown in Figure 3. 1. The research team uses large-scale random search to generate an initial candidate best pass list for the program. For each program, they independently generated a random list of up to 50 passes, uniformly sampled from the previously described set of 167 searchable passes. Each time they evaluated a program's pass list, they recorded the resulting binary size, and then selected each program's pass list that produced the smallest binary size. They ran 22 billion independent compilations, an average of 4,877 per program. 2. The pass list generated by random search may contain redundant passes, which have no impact on the final result. Additionally, some pass orders are interchangeable and reordering will not affect the final result. Since these introduce noise into the training data, they developed a minimization process and applied it to each pass list. Minimization includes three steps: redundant pass elimination, bubble sorting and insertion search. In redundant pass elimination, they minimize the optimal pass list by iteratively removing individual passes to see if they contribute to the binary size, and if not, discard them. Repeat this process until no more passes can be dropped. Bubble sort then attempts to provide a unified ordering for pass subsequences, sorting passes based on keywords. Finally, insertion sort performs a local search by looping through each pass in the pass list and trying to insert each of the 167 search passes before it. If doing so improves binary size, keep this new pass list. The entire minimization pipeline is looped until a fixed point is reached. The minimized pass list length distribution is shown in Figure 9. The average pass list length is 3.84.3. They apply the previously described PassListEval to the list of candidate best passes. In this way, they identified 167,971 out of 1,704,443 unique pass lists (9.85%) that would cause compile-time or run-time errors 4. They broadcast the 100 most common optimal pass lists to all program, and update the best pass list for each program if improvements are found. Afterwards, the total number of single best pass lists was reduced from 1,536,472 to 581,076. The above auto-tuning pipeline produced a 7.1% geometric mean binary size reduction compared to -Oz. Figure 10 shows the frequency of a single pass. To them, this automatic tuning serves as the gold standard for every program optimization. While the binary size savings found are significant, this required 28 billion additional compilations at a computational cost of over 21,000 CPU days. The goal of instruction fine-tuning of the LLM Compiler FTD to perform flag tuning tasks is to achieve a fraction of the auto-tuner performance without having to run the compiler thousands of times. Instruction fine-tuning for disassembly Lifts code from assembly language to a higher-level structure that can run additional optimizations, such as library code integrated directly into application code, or Port legacy code to new architecture. The field of decompilation has made progress in applying machine learning techniques to generate readable and accurate code from binary executables. In this study, the research team shows how LLM Compiler FTD can learn the relationship between assembly code and compiler IR by fine-tuning disassembly. The task is to learn the inverse translation of clang -xir - -o - -S, as shown in Figure 5. Round trip test. Using LLM for disassembly can cause correctness issues. Boosted code must be verified with an equivalence checker, which is not always possible, or requires manual verification of correctness, or sufficient test cases to gain confidence. However, a lower bound on correctness can be found through round-trip testing. That is, by recompiling the lifted IR into assembly code, if the assembly code is the same, the IR is correct. This provides a simple path to using the results of LLM and is a simple way to measure the utility of the disassembled model. Task specifications. The research team fed the model assembly code and trained it to emit corresponding disassembly IRs. The context length for this task was set to 8k tokens for the input assembly code and 8k tokens for the output IR. Dataset. They derived assembly code and IR pairs from the dataset used in previous tasks. Their fine-tuning dataset contains 4.7 million samples, and the input IR has been optimized using -Oz before being reduced to x86 assembly. The data is tokenized via byte pair encoding, using the same tokenizer as Code Llama, Llama and Llama 2. They use the same training parameters for all four training phases. They used most of the same training parameters as the Code Llama base model, using the AdamW optimizer with values of 0.9 and 0.95 for β1 and β2. They used cosine scheduling with a warm-up step of 1000 steps and set the final learning rate to 1/30 of the peak learning rate. Compared to the Code Llama base model, the team increased the context length of a single sequence from 4096 to 16384 but kept the batch size constant at 4 million tokens. To accommodate longer contexts, they set the learning rate to 2e-5 and modified the parameters of the RoPE position embedding, where they reset the frequency to the base value θ=10^6. These settings are consistent with long-context training of the Code Llama base model. The research team evaluates the performance of the LLM Compiler model on flag tuning and disassembly tasks, compiler simulation, next token prediction, and software engineering tasks. Method. They evaluate the performance of LLM Compiler FTD on the task of tuning optimization flags for unseen programs and compare it with GPT-4 Turbo and Code Llama - Instruct. They run inference on each model and extract a list of optimization passes from the model output. They then use this pass list to optimize a specific program and record the binary size. The baseline is the binary size of the program when optimized with -Oz. For GPT-4 Turbo and Code Llama - Instruct, they append a suffix after the prompt to provide additional context to further describe the problem and expected output format.All pass lists generated by the model are verified using PassListEval, and -Oz is used as an alternative if verification fails. To further verify the correctness of the pass list generated by the model, they linked the final program binary and differentially tested its output against the benchmark output optimized using a conservative -O2 optimization pipeline. Dataset. The research team conducted the evaluation using 2,398 test cues extracted from the MiBench benchmark suite. To generate these hints, they take all 713 translation units that make up the 24 MiBench benchmarks and generate unoptimized IRs from each unit, then format them into hints. If the generated hints exceed 15k tokens, they use llvm-extract to split the LLVM module representing that translation unit into smaller modules, one per function, which results in 1,985 hints that fit into the 15k token context window, leaving 443 translation units Not suitable. When calculating performance scores, they used -Oz for the 443 excluded translation units. Table 10 summarizes the benchmarks. Results. Table 3 shows the zero-shot performance of all models on the flag tuning task. Only the LLM Compiler FTD model improved over -Oz, with the 13B parameter model slightly outperforming the smaller model, producing smaller object files than -Oz in 61% of the cases. In some cases, the pass list generated by the model resulted in a larger target file size than -Oz. For example, LLM Compiler FTD 13B has degradation in 12% of cases. These degradations can be avoided by simply compiling the program twice: once with the pass list generated by the model, and once with -Oz, then selecting the pass list that yields the best results. By eliminating degradation relative to -Oz, these -Oz backup scores increase the overall improvement of LLM Compiler FTD 13B relative to -Oz to 5.26%, and enable Code Llama - Instruct and GPT-4 Turbo to achieve modest improvements relative to -Oz . Figure 6 shows the performance breakdown of each model on various benchmarks. Binary size accuracy. While the binary size predictions generated by the model have no impact on actual compilation, the research team can evaluate the model's performance in predicting binary size before and after optimization to understand how well each model understands the optimization. Figure 7 shows the results. LLM Compiler FTD’s binary size predictions correlate well with the actual situation, with the 7B parameter model achieving MAPE values of 0.083 and 0.225 for unoptimized and optimized binary sizes, respectively. The MAPE values for the 13B parameter model were similar, 0.082 and 0.225, respectively. Code Llama - Instruct and GPT-4 Turbo's binary size predictions have little correlation with reality. The researchers noticed that LLM Compiler FTD had slightly higher errors for optimized code than for unoptimized code. In particular, LLM Compiler FTD occasionally has a tendency to overestimate the effectiveness of optimization, resulting in predicted binary sizes that are lower than they actually are. Ablation research. Table 4 presents an ablation study of the model's performance on a small hold-out validation set of 500 cues from the same distribution as their training data (but not used in training). They performed flag-tuned training at each stage of the training pipeline shown in Figure 1 to compare performance. As shown, disassembly training resulted in a slight performance drop from an average of 5.15% to 5.12% (improvement over -Oz). They also demonstrate the performance of the autotuner used to generate the training data described in Section 2. LLM Compiler FTD achieves 77% of the performance of the autotuner. method. The research team evaluates the functional correctness of LLM-generated code when disassembling assembly code into LLVM-IR. They evaluate LLM Compiler FTD and compare it with Code Llama - Instruct and GPT-4 Turbo and find that additional hint suffixes are needed to extract the best performance from these models. The suffix provides additional context about the task and expected output format. To evaluate the performance of the model, they round-trip downgraded the disassembly IR generated by the model back to assembly. This allows us to evaluate the accuracy of the disassembly by comparing the BLEU scores of the original assembly with the round-trip results.A lossless perfect disassembly from assembly to IR will have a round-trip BLEU score of 1.0 (exact match). Dataset. They evaluated using 2,015 test hints extracted from the MiBench benchmark suite, taking the 2,398 translation units used for the above flag tuning evaluation, to generate disassembly hints. They then filtered the tips based on the maximum 8k token length, allowing 8k tokens for model output, leaving 2,015. Table 11 summarizes the benchmarks. Results. Table 5 shows the performance of the model on the disassembly task. LLM Compiler FTD 7B has a slightly higher round-trip success rate than LLM Compiler FTD 13B, but LLM Compiler FTD 13B has the highest round-trip assembly accuracy (round-trip BLEU) and most frequently produces perfect disassemblies (round-trip exact match). Code Llama - Instruct and GPT-4 Turbo have difficulty generating syntactically correct LLVM-IR. Figure 8 shows the distribution of round-trip BLEU scores for all models. Ablation research. Table 6 presents an ablation study of the model's performance on a small hold-out validation set of 500 cues, taken from the MiBench dataset used previously. They performed disassembly training at each stage of the training pipeline shown in Figure 1 to compare performance. The round-trip rate is highest when going through the entire training data stack and continues to decrease with each training stage, although the round-trip BLEU changes little at each stage. method. The research team conducted ablation research on the LLM Compiler model on two basic model tasks: next token prediction and compiler simulation. They perform this evaluation at each stage of the training pipeline to understand how training for each successive task affects performance. For next token prediction, they compute perplexity on a small sample of LLVM-IR and assembly code at all optimization levels. They evaluate compiler simulations using two metrics: whether the generated IR or assembly code compiles, and whether the generated IR or assembly code exactly matches what the compiler produces. Dataset. For next token prediction, they use a small holdout validation dataset from the same distribution as our training data but not used for training. They use a mix of optimization levels, including unoptimized code, code optimized with -Oz, and randomly generated pass lists. For compiler simulations, they were evaluated using 500 tips generated from MiBench using randomly generated pass lists in the manner described in Section 2.2. Results. Table 7 shows the performance of LLM Compiler FTD on two base model training tasks (next token prediction and compiler simulation) across all training stages. Next token prediction performance rises sharply after Code Llama, which barely sees IR and assembly, and drops slightly with each subsequent fine-tuning stage. For compiler simulations, the Code Llama base model and pre-trained models do not perform well because they are not trained on this task. Maximum performance is achieved directly after compiler simulation training, where 95.6% of IRs and assemblies generated by LLM Compiler FTD 13B compile and 20% match the compiler exactly. After doing flag tuning and disassembly fine-tuning, performance dropped. Software Engineering TasksMethods. While the purpose of LLM Compiler FTD is to provide a base model for code optimization, it is built on top of the base Code Llama model trained for software engineering tasks. To evaluate how additional training of LLM Compiler FTD affects the performance of code generation, they used the same benchmark suite as Code Llama to evaluate LLM's ability to generate Python code from natural language prompts, such as "Write a function that finds out how to generate Python code from a given The longest chain formed by pairs of sets. They use HumanEval and MBPP benchmarks, the same as Code Llama. Results. Table 8 shows the greedy decoding performance (pass@1) for all model training stages and model sizes starting from the Code Llama base model.It also shows the model's scores on pass@10 and pass@100, which were generated with p=0.95 and temperature=0.6. Each compiler-centric training phase results in a slight degradation in Python programming abilities. On HumanEval and MBPP, pass@1 performance of LLM Compiler dropped by up to 18% and 5%, and LLM Compiler FTD dropped by up to 29% and 22% after additional flag tuning and disassembly fine-tuning. All models still outperform Llama 2 on both tasks. Meta research team has demonstrated that LLM Compiler performs well on compiler optimization tasks and provides improved understanding of compiler representation and assembly code compared to previous work, But there are still some limitations. The main limitation is the limited sequence length of the input (context window). LLM Compiler supports a context window of 16k tokens, but program code may be much longer than this. For example, when formatted as a flag tuning tip, 67% of MiBench translation units exceeded this context window, as shown in Table 10. To alleviate this problem, they split the larger translation units into separate functions, although this limits the scope of optimization that can be performed, and still 18% of the split translation units are too large for the model is too large to be accepted as input. Researchers are employing ever-increasing context windows, but limited context windows remain a common problem in LLM. The second limitation, and a problem common to all LLMs, is the accuracy of the model output. Users of LLM Compiler are recommended to evaluate their models using compiler-specific evaluation benchmarks. Given that compilers are not bug-free, any proposed compiler optimizations must be rigorously tested. When a model is decompiled into assembly code, its accuracy should be confirmed through round-tripping, manual inspection, or unit testing. For some applications, LLM generation can be restricted to regular expressions, or combined with automatic validation to ensure correctness. https://x.com/AIatMeta/status/1806361623831171318
https://ai.meta.com/ research/publications/meta -large-language-model-compiler-foundation-models-of-compiler-optimization/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fairThe above is the detailed content of Developers are ecstatic! Meta's latest release of LLM Compiler achieves 77% automatic tuning efficiency. For more information, please follow other related articles on the PHP Chinese website!






























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



