
 Technology peripherals
AI
Generate four-dimensional content in a few minutes and control motion effects: Peking University and Michigan propose DG4D
Technology peripherals
AI
Generate four-dimensional content in a few minutes and control motion effects: Peking University and Michigan propose DG4D
Generate four-dimensional content in a few minutes and control motion effects: Peking University and Michigan propose DG4D


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The author of this article, Dr. Pan Liang, is currently a Research Scientist at the Shanghai Artificial Intelligence Laboratory. Previously, from 2020 to 2023, he served as a Research Fellow at the S-Lab of Nanyang Technological University in Singapore, and his advisor was Professor Liu Ziwei. His research focuses on computer vision, 3D point clouds and virtual humans, and he has published multiple papers in top conferences and journals, with more than 2700 Google Scholar citations. In addition, he has served as a reviewer for top conferences and journals in the fields of computer vision and machine learning.
Recently, SenseTime-Nanyang Technological University Joint AI Research Center S-Lab, Shanghai Artificial Intelligence Laboratory, Peking University and the University of Michigan jointly proposed DreamGaussian4D (DG4D), which combines explicit modeling of spatial transformation with static 3D Gaussian Splatting (GS) technology enables efficient four-dimensional content generation.
Four-dimensional content generation has made significant progress recently, but existing methods have problems such as long optimization time, poor motion control capabilities, and low detail quality. DG4D proposes an overall framework containing two main modules: 1) Image to 4D GS - we first use DreamGaussianHD to generate static 3D GS, and then generate dynamic generation based on Gaussian deformation based on HexPlane; 2) Video to video texture refinement - we The resulting UV spatial texture map is refined and its temporal consistency is enhanced by using a pretrained image-to-video diffusion model.
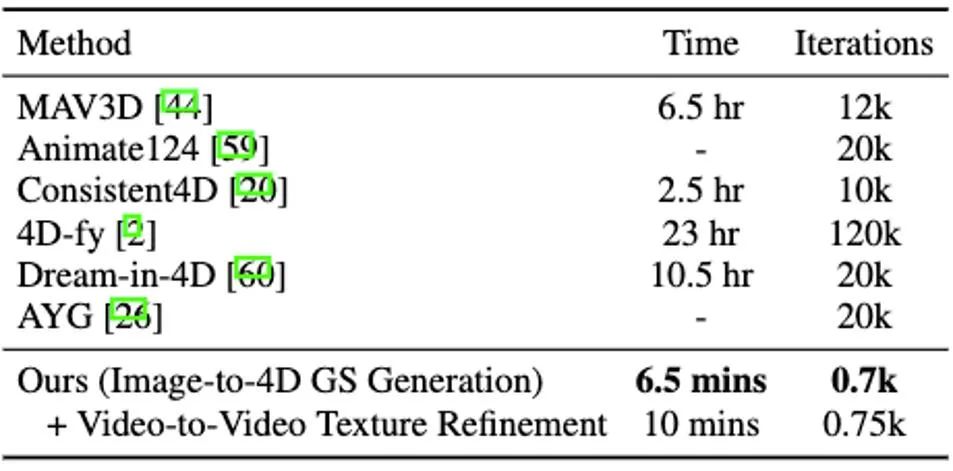
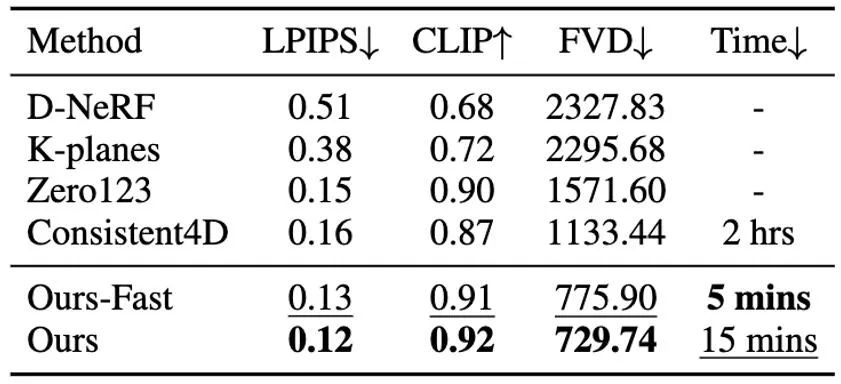
It is worth noting that DG4D reduces the optimization time of four-dimensional content generation from hours to minutes (as shown in Figure 1), allows visual control of the generated three-dimensional motion, and supports the generation of images that can be realistically rendered in a three-dimensional engine. Animated mesh model.

Paper name: DreamGaussian4D: Generative 4D Gaussian Splatting
Homepage address: https://jiawei-ren.github.io/projects/dreamgaussian4d/
Paper address: https:// arxiv.org/abs/2312.17142
Demo address: https://huggingface.co/spaces/jiawei011/dreamgaussian4d

Figure 1. DG4D can realize four-dimensional content in four and a half minutes Optimizing Basic Convergence
Issues and Challenges
Generative models can greatly simplify the production and production of diverse digital content such as 2D images, videos, and 3D scenes, and have made significant progress in recent years. Four-dimensional content is an important content form for many downstream tasks such as games, movies, and television. Four-dimensional generated content should also support the import of traditional graphics rendering engine software (such as Blender or Unreal Engine) to connect to the existing graphics content production pipeline (see Figure 2).
Although there are some studies dedicated to dynamic three-dimensional (i.e., four-dimensional) generation, there are still challenges in the efficient and high-quality generation of four-dimensional scenes. In recent years, more and more research methods have been used to achieve four-dimensional content generation by combining video and three-dimensional generation models to constrain the consistency of content appearance and actions under any viewing angle.

NeRF) said. For example, MAV3D [1] achieves text-to-four-dimensional content generation by refining the text-to-video diffusion model on HexPlane [2]. Consistent4D [3] introduces a video-to-4D framework to optimize cascaded DyNeRF to generate 4D scenes from statically captured videos. With multiple diffusion model priors, Animate124 [4] is able to animate a single unprocessed 2D image into a 3D dynamic video via textual motion description. Based on hybrid SDS [5] technology, 4D-fy [6] enables the generation of engaging text-to-four-dimensional content using multiple pre-trained diffusion models. However, all the above-mentioned existing methods [1,3,4,6] require several hours to generate a single 4D NeRF, which greatly limits their application potential. Furthermore, they all have difficulty in effectively controlling or selecting the final generated motion. The above shortcomings mainly come from the following factors: First, the underlying implicit four-dimensional representation of the aforementioned method is not efficient enough, and there are problems such as slow rendering speed and poor motion regularity; secondly, the random nature of video SDS increases the difficulty of convergence, and in the final results Introduces instability and multiple artifacts. Method introduction Different from methods that directly optimize 4D NeRF, DG4D builds an efficient and powerful representation for 4D content generation by combining static Gaussian splashing technology and explicit spatial transformation modeling. Furthermore, video generation methods have the potential to provide valuable spatiotemporal priors that enhance high-quality 4D generation. Specifically, we propose an overall framework consisting of two main stages: 1) image to 4D GS generation; 2) video large model-based texture map refinement. D1. The generation of image to 4D GS
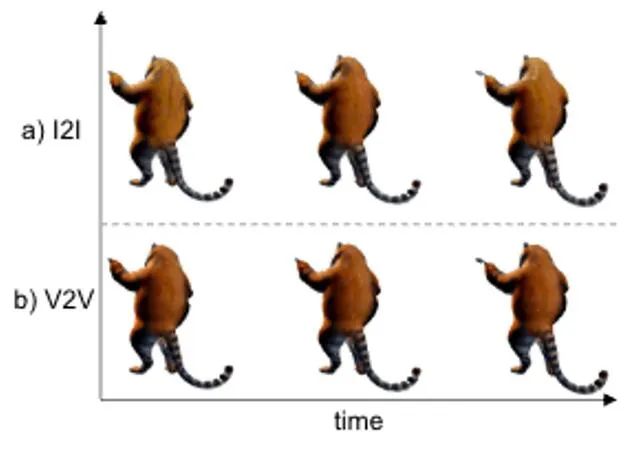
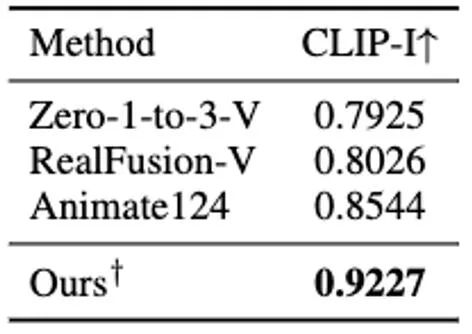
In this stage, we use static 3D GS and its spatial deformation to indicate dynamic dynamics four-dimensional scene. Based on a given 2D image, we use the enhanced DreamGaussianHD method to generate static 3D GS. Subsequently, by optimizing the time-dependent deformation field on the static 3D GS function, the Gaussian deformation at each timestamp is estimated, aiming to make the shape and texture of each deformed frame consistent with the corresponding frame in the driving video. At the end of this stage, a dynamic three-dimensional mesh model sequence will be generated. Based on the recent graphical 3D object method DreamGaussian [7] using 3D GS, we have made some further improvements , and compiled a set of better 3D GS generation and initialization methods. The main improved operations include 1) adopting a multi-view optimization method; 2) setting the background of the rendered image during the optimization process to a black background that is more suitable for generation. We call the improved version DreamGaussianHD, and the specific improvement renderings can be seen in Figure 4. Figure 5 HexPlane represents the dynamic deformation field Based on the generated static 3D GS model, we generate videos that meet the expectations by predicting the deformation of the Gaussian kernel in each frame Dynamic 4D GS model. In terms of characterization of dynamic effects, we choose HexPlane (shown in Figure 5) to predict the Gaussian kernel displacement, rotation and scale at each timestamp, thereby driving the generation of a dynamic model for each frame. In addition, we also adjusted the design network in a targeted manner, especially the design of residual connections and zero initialization for the last few linear operation network layers, so that the dynamic field can be smoothly and fully initialized based on the static 3D GS model (the effect is as shown in the figure) shown in 6).始 Figure 6 The impact of the initialization of the dynamic formation on the final generation of the dynamic field Figure 7 Video to video texture optimization Frame diagram Similar to DreamGaussian, after the first stage of four-dimensional dynamic model generation based on 4D GS, the four-dimensional mesh model sequence can be extracted. Moreover, we can also further optimize the texture in the UV space of the mesh model, similar to what DreamGaussian does. Unlike DreamGaussian, which only uses image generation models to optimize textures for individual 3D mesh models, we need to optimize the entire 3D mesh sequence. Moreover, we found that if we follow the approach of DreamGaussian, that is, perform independent texture optimization for each 3D mesh sequence, the texture of the 3D mesh will be generated inconsistently at different timestamps, and there will often be flickering, etc. Defect artifacts appear. In view of this, we are different from DreamGaussian and propose a video-to-video texture optimization method in UV space based on a large video generation model. Specifically, we randomly generated a series of camera trajectories during the optimization process, and rendered multiple videos based on this, and performed corresponding noise addition and denoising on the rendered videos to achieve the generation of mesh model sequences. texture enhancement. The comparison of the texture optimization effects of generating a large model based on pictures and generating a large model based on videos is shown in Figure 8. Experimental results . Consistency reporting In Table 2.
Table 3 Comparison of numerical results of four-dimensional content-related methods based on video generation DG4D and the existing open source SOTA graph generates the effect of the four -dimensional content method and video generating four -dimensional content methods, which are displayed in FIG. 9 and Figure 10 .内容 Figure 9 Figure 9 Shengsheng four -dimensional content effect comparison Figure Video Sheng four -dimensional content effect comparison Figure In addition, we also generated static 3D content based on the recent direct feedforward method of generating 3D GS from a single image (that is, not using the SDS optimization method), and initialized the generation of dynamic 4D GS based on this. Direct feedforward generation of 3D GS can produce higher quality and more diverse 3D content faster than methods based on SDS optimization. The four-dimensional content obtained based on this is shown in Figure 11.生 Figure 11 The four -dimensional dynamic content generated based on the method of generating 3D GS Conclusion
Based on 4D GS, we propose DreamGaussian4D (DG4D), an efficient image-to-4D generation framework. Compared to existing four-dimensional content generation frameworks, DG4D significantly reduces optimization time from hours to minutes. Furthermore, we demonstrate the use of generated videos for driven motion generation, achieving visually controllable 3D motion generation.
References [1] Singer et al. "Text-to-4D dynamic scene generation." Proceedings of the 40th International Conference on Machine Learning. 2023. [ 2] Cao et al. "Hexplane: A fast representation for dynamic scenes." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. [3] Jiang et al. "Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video." The Twelfth International Conference on Learning Representations. 2023. [4] Zhao et al. "Animate124: Animating one image to 4d dynamic scene." arXiv preprint arXiv:2311.14603 (2023). [5] Poole et al. "DreamFusion: Text-to-3D using 2D Diffusion." The Eleventh International Conference on Learning Representations. 2022. [6] Bahmani , Sherwin, et al. "4d-fy: Text-to-4d generation using hybrid score distillation sampling." arXiv preprint arXiv:2311.17984 (2023). [7] Tang et al. "DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation." The Twelfth International Conference on Learning Representations. 2023.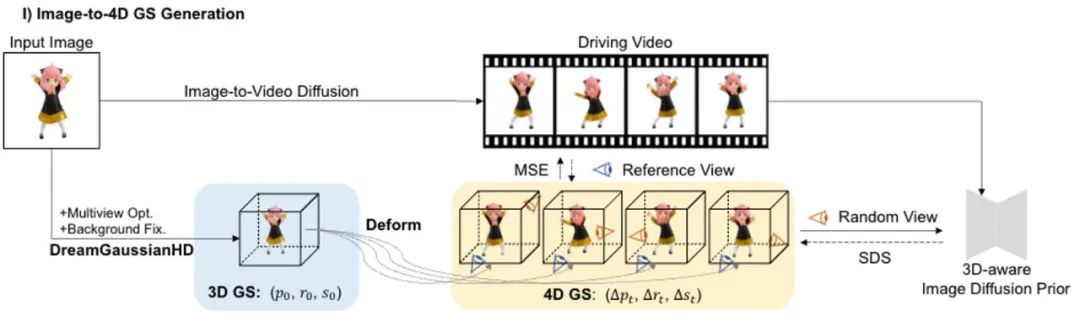

2. Water optimization of video to video


The above is the detailed content of Generate four-dimensional content in a few minutes and control motion effects: Peking University and Michigan propose DG4D. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1422
52
1316
25
1267
29
1239
24
14
1422
52
1316
25
1267
29
1239
24

 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
It is also a Tusheng video, but PaintsUndo has taken a different route. ControlNet author LvminZhang started to live again! This time I aim at the field of painting. The new project PaintsUndo has received 1.4kstar (still rising crazily) not long after it was launched. Project address: https://github.com/lllyasviel/Paints-UNDO Through this project, the user inputs a static image, and PaintsUndo can automatically help you generate a video of the entire painting process, from line draft to finished product. follow. During the drawing process, the line changes are amazing. The final video result is very similar to the original image: Let’s take a look at a complete drawing.
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com The authors of this paper are all from the team of teacher Zhang Lingming at the University of Illinois at Urbana-Champaign (UIUC), including: Steven Code repair; Deng Yinlin, fourth-year doctoral student, researcher
 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com In the development process of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models are both powerful and safe serve human society. Early efforts focused on reinforcement learning methods through human feedback (RL
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
cheers! What is it like when a paper discussion is down to words? Recently, students at Stanford University created alphaXiv, an open discussion forum for arXiv papers that allows questions and comments to be posted directly on any arXiv paper. Website link: https://alphaxiv.org/ In fact, there is no need to visit this website specifically. Just change arXiv in any URL to alphaXiv to directly open the corresponding paper on the alphaXiv forum: you can accurately locate the paragraphs in the paper, Sentence: In the discussion area on the right, users can post questions to ask the author about the ideas and details of the paper. For example, they can also comment on the content of the paper, such as: "Given to
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
Recently, the Riemann Hypothesis, known as one of the seven major problems of the millennium, has achieved a new breakthrough. The Riemann Hypothesis is a very important unsolved problem in mathematics, related to the precise properties of the distribution of prime numbers (primes are those numbers that are only divisible by 1 and themselves, and they play a fundamental role in number theory). In today's mathematical literature, there are more than a thousand mathematical propositions based on the establishment of the Riemann Hypothesis (or its generalized form). In other words, once the Riemann Hypothesis and its generalized form are proven, these more than a thousand propositions will be established as theorems, which will have a profound impact on the field of mathematics; and if the Riemann Hypothesis is proven wrong, then among these propositions part of it will also lose its effectiveness. New breakthrough comes from MIT mathematics professor Larry Guth and Oxford University
 The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Introduction In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the basic model for many downstream tasks, current MLLM consists of the well-known Transformer network, which
 LLM is really not good for time series prediction. It doesn't even use its reasoning ability.
Jul 15, 2024 pm 03:59 PM
LLM is really not good for time series prediction. It doesn't even use its reasoning ability.
Jul 15, 2024 pm 03:59 PM
Can language models really be used for time series prediction? According to Betteridge's Law of Headlines (any news headline ending with a question mark can be answered with "no"), the answer should be no. The fact seems to be true: such a powerful LLM cannot handle time series data well. Time series, that is, time series, as the name suggests, refers to a set of data point sequences arranged in the order of time. Time series analysis is critical in many areas, including disease spread prediction, retail analytics, healthcare, and finance. In the field of time series analysis, many researchers have recently been studying how to use large language models (LLM) to classify, predict, and detect anomalies in time series. These papers assume that language models that are good at handling sequential dependencies in text can also generalize to time series.
