
 Technology peripherals
AI
After changing to more than 30 dialects, we failed to pass the test of China Telecom's large speech model
Technology peripherals
AI
After changing to more than 30 dialects, we failed to pass the test of China Telecom's large speech model
After changing to more than 30 dialects, we failed to pass the test of China Telecom's large speech model

No matter which city you come from, I believe you have your own "hometown dialect" in your memory: Wu dialect is soft and delicate, Guanzhong dialect is simple and thick, Sichuan dialect is humorous and humorous, Cantonese is quaint and unrestrained...
In a sense, Dialect is not only a language habit, but also an emotional connection and a cultural identity. Many of the new words we encounter while surfing the Internet come from local dialects from various places.
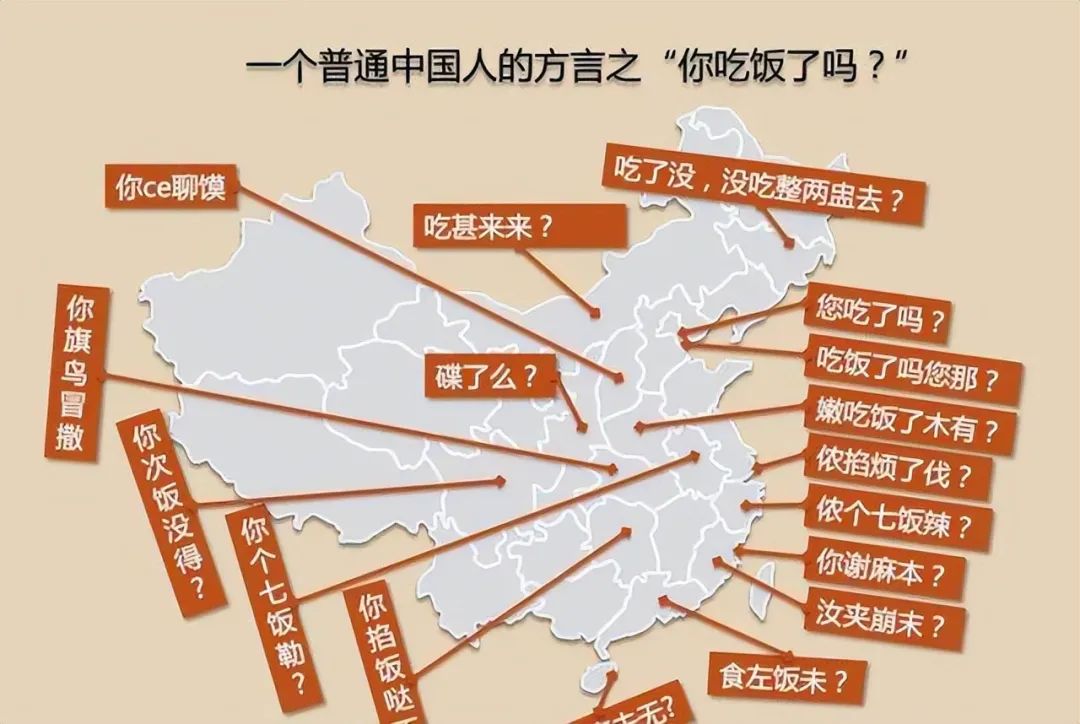
Of course, sometimes dialect is also a "barrier" to communication.
In real life, we often see "chickens and ducks talking" caused by dialects, such as this: 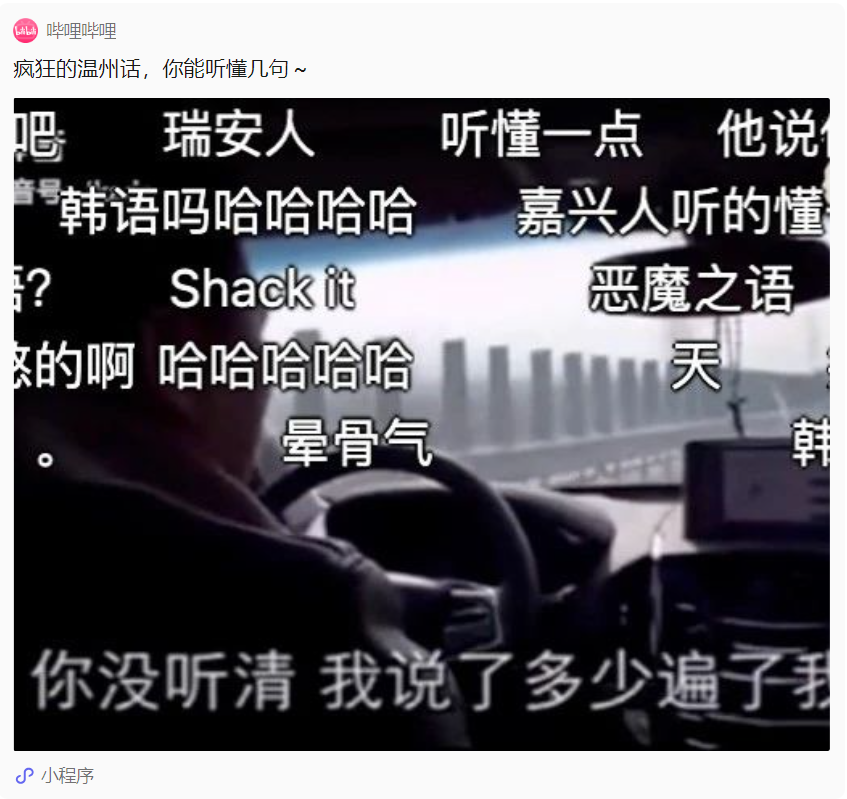
If you pay attention to the recent trends in the technology circle, you will know that the current AI voice assistant can already achieve The level of "real-time response" is even faster than human reaction. Moreover, AI has been able to fully understand human emotions and can express various emotions on its own.
On this basis, if the voice assistant can recognize and understand every dialect, it can completely break down communication barriers and communicate with any group without barriers.
In fact, someone has already done this: Recently, China Telecom Artificial Intelligence Research Institute (TeleAI) released the industry's first "Xingchen Super Multi-Dialect Speech Recognition Model" that supports free mixing of 30 dialects. It simultaneously recognizes and understands Cantonese, Shanghainese, Sichuan, Wenzhou and other local dialects. It is a large speech recognition model that supports the most dialects in China.
For example, in the following conference scenario, faced with input from multiple dialects, the recognition accuracy of Xingchen’s large multi-dialect speech recognition model reached the leading level in the industry.
First, the representative from the Guangdong company spoke in Cantonese: 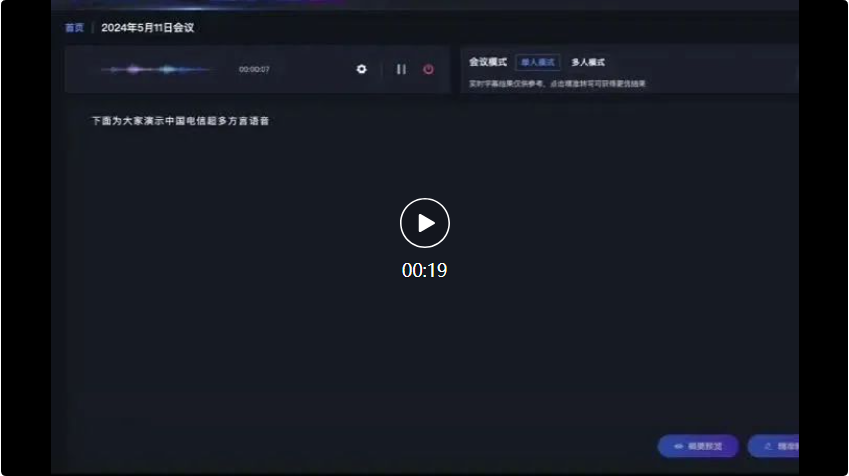
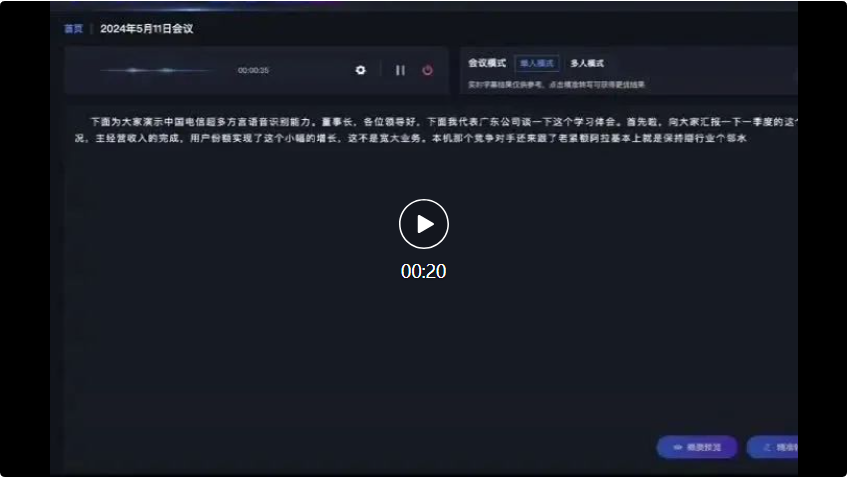 In the subsequent dialogue between Sichuan dialect and Shanxi dialect , Xingchen’s large multi-dialect speech recognition model can also accurately recognize and convert into text records:
In the subsequent dialogue between Sichuan dialect and Shanxi dialect , Xingchen’s large multi-dialect speech recognition model can also accurately recognize and convert into text records: 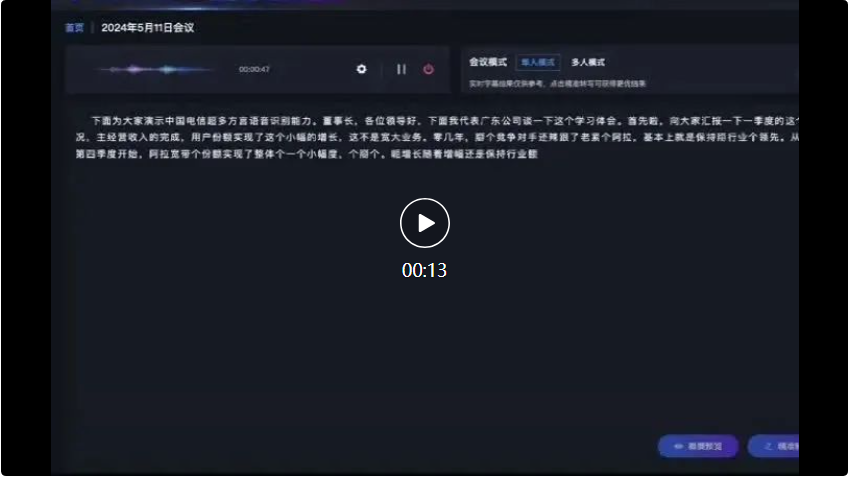
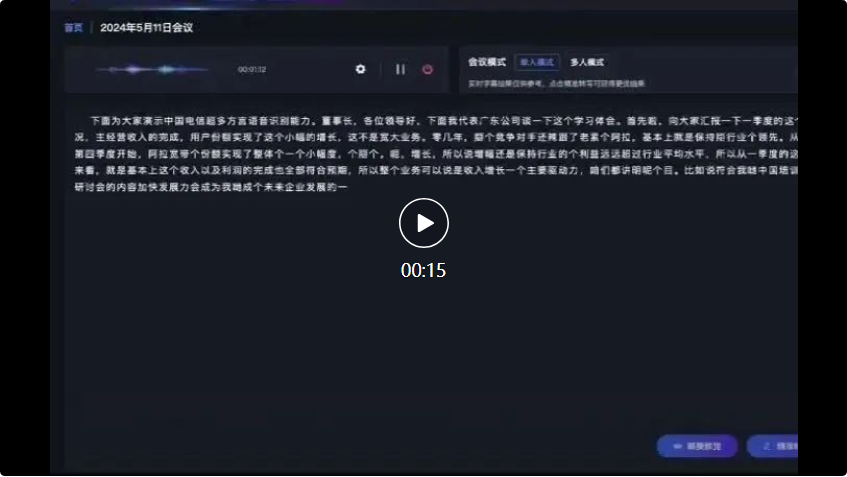
Anyone who has talked to a voice assistant knows that the accuracy of speech recognition for Mandarin is quite good, but When faced with strong accents or dialects, the recognition accuracy will drop significantly, or even "putting the crown in the hat".
In order to solve this problem, the traditional speech recognition model is to train a dialect model separately for each dialect. This results in the need to maintain multiple dialect models behind the same application, and it is impossible to recognize multiple dialects through one model. However, the latter is exactly what is most needed in real-life scenarios.
China Telecom, which has been deeply involved in the voice field, decided to challenge this proposition: create a more "universal" large speech recognition model.
More than 30 dialects, how to get the big model?
It is not as easy as imagined to let a large model learn more than 30 dialects in one go - the challenges also exist in terms of data, algorithms, and computing power.
On the one hand, due to the sparse amount of dialect data, the effect of training a dialect model alone without using the common information in other dialect data is often unsatisfactory.
After years of accumulation in the speech field, TeleAI has built a high-quality dialect database of more than 30 kinds and more than 300,000 hours. The dialect database ranks at the forefront of the industry in terms of richness and high quality. High-quality speech data is a big plus for researchers, allowing models to organize and summarize dialects more efficiently and systematically. In the longer term, building a high-quality dialect database is also the basis for dialect protection and research.
Another challenge comes from speech recognition technology. How to make users talk to large models as naturally as talking to family members, without the need to deliberately switch to Mandarin, without the need to raise the volume or slow down the speaking speed, is a new goal currently pursued by the industry.
Led by Li Xuelong, CTO of China Telecom and Director of the Artificial Intelligence Research Institute, TeleAI independently developed the large-scale Xingchen speech recognition model. The team pioneered the "distillation + expansion" joint training algorithm, which solved the problem of pre-training collapse under ultra-large-scale multi-scenario data sets and large-scale parameter conditions, and achieved stable training of the 80-layer model. At the same time, through ultra-large-scale speech pre-training and multi-dialect joint modeling, a single model can support free mixed speech recognition of 30 dialects.

The Xingchen speech recognition large model is also the industry's first open source large speech recognition model based on discrete speech representation. Through the new modeling paradigm of "from speech to token to text", the speech transmission bit rate during inference is reduced Reduced by dozens of times.
With its absolutely leading performance, the Xingchen speech recognition model has previously won multiple international authoritative competition championships internationally.
For example, in the ASR track (Automatic Speech Recognition, Automatic Speech Recognition) of the Interspeech 2024 Discrete Speech Unit Modeling Challenge, the authoritative international speech conference, the Xingchen speech recognition large model team is ahead of Johns Hopkins University, Card Well-known universities and companies at home and abroad, including Mellon University and NVIDIA, won the track championship in one fell swoop.
The system solution proposed by the team in this competition is very distinctive: it adopts a "three-stage" design during training, including the front-end pre-training model representation adjustment strategy (Frontend Model), representation extraction and discretization process (Dsicrete Token Process) and the multilingual recognition model training process (Discrete ASR Model), while only the latter two processes are used in the inference stage.
The representation discretization method allows the model to retain task-related information in speech while removing other irrelevant information to achieve the purpose of reducing the speech inference transmission bit rate, reducing memory usage, and improving training efficiency. It also provides speech Possible solutions are provided in the directions of unified model construction, multi-modal model modeling, and speaker privacy protection for multi-tasks (such as ASR, TTS, speaker recognition, etc.).
On the KeSpeech task, a well-known multi-dialect speech recognition data set in the industry, the Xingchen speech recognition large model broke the record by 20% ahead of the previous best result, achieving a word accuracy of 92.97%. In the low-resource Cantonese phone Babel speech recognition task held by NIST (National Institute of Standards and Technology), the Xingchen speech recognition large model also achieved the best results in the industry.
In terms of common computing power challenges, the R&D team of Xingchen speech recognition large model also has advantages. China Telecom is the first domestic operator to enter the field of cloud computing and has accumulated a large number of core technologies for computing power construction and computing power scheduling. In addition, China Telecom has successively put into operation several public intelligent computing centers that meet the needs of large model training, such as the Beijing-Tianjin-Hebei Intelligent Computing Center and the Central-South Intelligent Computing Center.
Based on these advantages, Xingchen’s large multi-dialect speech recognition model was born, breaking the dilemma that a single model can only recognize a specific single dialect. In multiple benchmark tests, the Xingchen super multi-dialect speech recognition large model has shown extremely excellent capabilities:
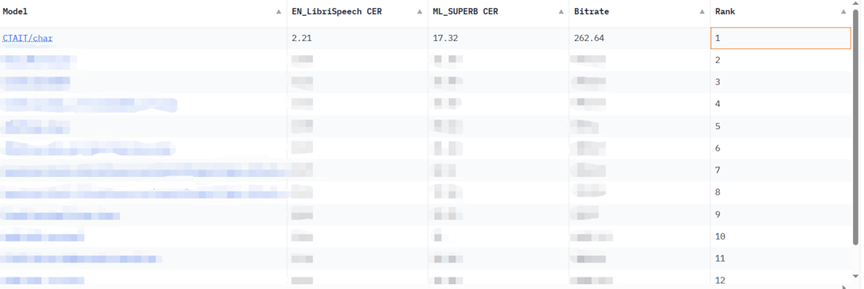
in the large model The user experience of voice assistants, smart devices and customer service systems that were widely used before the rise of technology is highly dependent on the accuracy of the speech recognition system. Many domestic and foreign manufacturers are working hard on this track, but everyone will also find that outside of mainstream languages, Chinese dialects with hundreds of millions of users have not received due attention, and their scene value has been seriously underestimated.
In the long run, the multi-dialect capabilities of Xingchen’s large multi-dialect speech recognition model can be valuable in a very wide range of social life scenarios. Taking the Smart Cockpit scenario with a high frequency of voice interaction as an example, Xingchen's large multi-dialect speech recognition model, which is good at various dialects, can enable the system to more accurately recognize and transcribe speech input in various dialects, bringing a more natural and smooth experience. Interactive experience, especially in areas where dialects are commonly used, can reduce misunderstandings caused by "chickens speaking with ducks".
From the perspective of emotional companionship, the understanding and proficiency of large models in dialects can greatly improve the companionship quality of conversational robot products, and effectively solve the problem of the elderly and other groups who are not proficient in Mandarin unable to access information services. Just like the plot in the science fiction movie "Her", AI can provide humans with high-quality care that transcends interpersonal relationships in the real world. 
目前,星辰超多方言語音辨識大模型已經在開始融入各行各業,積極探索新興的應用場景。例如,星辰超多方言語音辨識大模型已在福建、江西、廣西、北京、內蒙等地的中國電信萬號智能客服系統試點應用,接入星辰超多方言語音識別大模型以後,萬號智能客服秒懂30 種方言,實現了日均處理約200 萬通電話;智能客服翼聲平台接入星辰超多方言語音識別大模型的語音理解和分析能力,實現31 省全覆蓋,每天可處理125 萬通客服電話。
對於中國電信來說,還有一個非常重要的起點:2023 年之前,當人們談論大模型技術時,公益價值很少會被提及。但在 2024 年,這一價值越來越多地「被看見」。
大模型技術的應用將很大程度上推動對方言文化的保護。在我國的130 多種語言中,有68 種使用人口在萬人以下,有48 種使用人口在5000 人以下,有25 種使用人口不足千人,有的語言只剩下十幾個人甚至幾個人會說。語音大模型的參與,能夠幫助記錄和保護瀕危方言,促進方言的傳承和學習。對於包含大量方言內容的歷史文獻和檔案,方言大模型還可以輔助進行數位化和整理工作,防止文化遺產的流失。
「語音助理」全面開卷
中國電信如何領先大型模型落地之戰?
大模型之戰已經持續一年半之久,產業目前有一個共識:隨著大模型推理成本的大幅下降,人們將迎來大模型應用的井噴期。
在海內外眾多的大模型玩家中,中國電信是很特別的一位。在這個新階段,相較於我們熟悉的科技企業,像中國電信這樣的業者在資源優勢和業務方面更具優勢。
一方面,操作員有豐富的網路和算力資源,相對來說訓練、推理成本更低。尤其在大模型的建置方面,更容易發揮規模的優勢。另一方面,中國電信有龐大的客戶群,以及豐富的 2C、2H、2B 的資訊服務業務,能夠更快地推動人工智慧大模型在各個領域的落地,形成新的經濟成長點。這些優勢使營運商有動力在人工智慧領域加大投入,驅動技術進步。
在國內營運商中,中國電信是最早佈局 AI 領域的一家,且堅持走科技創新、核心能力自主研發的發展路線。去年至今,從星辰語意大模型到星辰多模態大模型與星辰語音辨識大模型,中國電信旗下的大模型始終保持著快速迭代,且完成了語意、語音、視覺、多模態的全模態大模型佈局。

更讓人打破對央企傳統印象的是,中國電信還是大模型開源領域的重量級玩家。今年,TeleAI 陸續開源了 7B、12B、52B 的星辰語意大模型。今年內,千億級星辰語意大模型也將正式開源。
沿著近年來人工智慧的技術發展趨勢,我們可以看到,在實現通用人工智慧的過程中,語音是關鍵的一部分,而語音辨識是其中非常重要的一環。
但我們同樣意識到,語音合成技術的成熟,將成為重塑各個語音助理場景的關鍵。據了解,TeleAI 也同步研發了讓擬人更真人的超自然語音生成大模型,實現零樣本聲音復刻和擬人度對齊GPT-4o,將在語音識別和生成應用層面上進一步突破,加速通用AI 語音助手的落地應用。  這樣的全能中文語音助手,你期待嗎?
這樣的全能中文語音助手,你期待嗎?
The above is the detailed content of After changing to more than 30 dialects, we failed to pass the test of China Telecom's large speech model. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1422
52
1316
25
1267
29
1239
24
14
1422
52
1316
25
1267
29
1239
24

 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Conference Introduction With the rapid development of science and technology, artificial intelligence has become an important force in promoting social progress. In this era, we are fortunate to witness and participate in the innovation and application of Distributed Artificial Intelligence (DAI). Distributed artificial intelligence is an important branch of the field of artificial intelligence, which has attracted more and more attention in recent years. Agents based on large language models (LLM) have suddenly emerged. By combining the powerful language understanding and generation capabilities of large models, they have shown great potential in natural language interaction, knowledge reasoning, task planning, etc. AIAgent is taking over the big language model and has become a hot topic in the current AI circle. Au
