
 Technology peripherals
AI
To effectively evaluate the actual performance of Agent, the new online evaluation framework WebCanvas is here
Technology peripherals
AI
To effectively evaluate the actual performance of Agent, the new online evaluation framework WebCanvas is here
To effectively evaluate the actual performance of Agent, the new online evaluation framework WebCanvas is here

Pan Yichen: First-year master’s student at Zhejiang University. Kong Dehan: Head of Model Algorithm at Cross Star Technology. Zhou Sida: A 2024 graduate of Nanchang University, he will study for a master's degree at Xi'an University of Electronic Science and Technology. Cui Cheng: A 2024 graduate of Zhejiang University of Traditional Chinese Medicine. He will study for a master's degree at Suzhou University.
Pan Yichen, Zhou Sida, and Cui Cheng jointly completed the research work of this paper as algorithm interns of Cross Star Technology.
In today's era of rapid technological development, Large Language Model (LLM) is changing the way we interact with the digital world at an unprecedented speed. LLM-based intelligent agents (LLM Agents) are gradually integrated into our lives, from simple information searches to complex web page operations. However, a key question remains unresolved: When these LLM Agents step into the real online network world, will they perform as well as expected?
Most of the existing evaluation methods remain at the level of static data sets or simulated websites. These methods have their value, but their limitations are obvious: static data sets are difficult to capture dynamic changes in the web environment, such as interface updates and content iterations; simulated websites lack the complexity of the real world and fail to fully consider cross-site operations, such as using Search engines and other operations, these factors are indispensable in real environments.
In order to solve this problem, a paper titled "WebCanvas: Benchmarking Web Agents
in Online Environments" proposed an innovative online evaluation framework - WebCanvas, aiming to benchmark the performance of Agents in the real online world. Provide a comprehensive assessment approach.

Paper link: https://arxiv.org/pdf/2406.12373
WebCanvas platform link: https://imean.ai/web-canvas
Project code link: https: //github.com/iMeanAI/WebCanvas
Dataset link: https://huggingface.co/datasets/iMeanAI/Mind2Web-Live
One of the innovations of WebCanvas is the proposal of "key nodes" concept. This concept not only focuses on the final completion of the task, but also goes deep into the details of the task execution process to ensure the accuracy of the assessment. WebCanvas provides a new perspective for online evaluation of agents by identifying and detecting key nodes in the task flow - whether reaching a specific web page or performing a specific action (such as clicking a specific button).

WebCanvas frame diagram. The left side shows the labeling process of the task, and the right side shows the task evaluation process. WebCanvas takes into account the non-uniqueness of task paths in online network interactions, and the "trophy" represents the step score obtained after successfully reaching each key node.
Based on the WebCanvas framework, the author constructed the Mind2Web-Live dataset, which contains 542 tasks randomly selected from Mind2Web. The author of this article also annotated key nodes for each task in the data set. Through a series of experiments, we found that when the Agent is equipped with a Memory module, supplemented by the ReAct reasoning framework, and equipped with the GPT-4-turbo model, its task success rate increases to 23.1%. We firmly believe that with the continuous evolution of technology, the potential of Web Agent is still unlimited, and this number will soon be exceeded.
Key nodes
The concept of "key nodes" is one of the core ideas of WebCanvas. Key nodes refer to the steps that are indispensable in completing a specific network task, that is, these steps are indispensable regardless of the path to complete the task. These steps range from visiting a specific web page to performing specific actions on the page, such as filling out a form or clicking a button.
Taking the green part of the WebCanvas frame as an example, the user needs to find the highest-rated upcoming adventure movie on the Rotten Tomatoes website. He can do this in a variety of ways, such as starting from the Rotten Tomatoes homepage, or directly targeting the “upcoming movies” page of a search engine. When filtering videos, a user might select the "Adventure" genre first and then sort by popularity, or vice versa. While there are multiple paths to achieving your goals, getting to a specific page and filtering through them is an integral step in getting things done. Therefore, these three operations are defined as critical nodes for this task.
Evaluation indicators
The evaluation system of WebCanvas is divided into two parts: step score and task score, which together constitute the evaluation of WebAgent's comprehensive capabilities.
Step Score: Measures the performance of the Agent on key nodes. Each key node is associated with an evaluation function, through three evaluation targets (URL, element path, element value) and three matching functions (exact, inclusion, semantics) to achieve. Each time it reaches a key node and passes the evaluation function, the Agent can obtain the corresponding score.

評估函數總覽,其中 E 代表網頁元素 Element
任務得分:分為任務完成得分和效率得分。任務完成得分反映 Agent 是否成功拿到了此任務所有的步驟得分。而效率得分則考慮了任務執行的資源利用率,計算方法為每個步驟得分所需的平均步驟數。
Mind2Web-Live 資料集
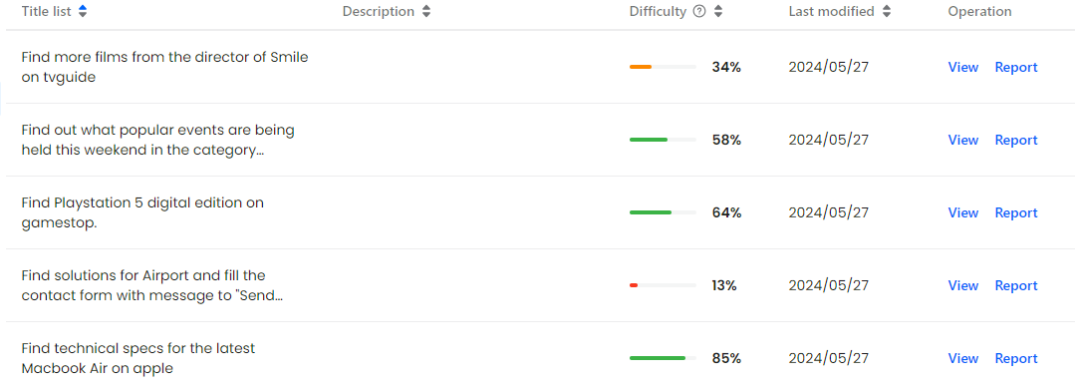
作者從Mind2Web 訓練集中隨機抽取了601 個與時間無關的任務,以及測試集Cross-task 子集中的179 個同樣與時間無關的任務,然後將這些任務在真實線上環境中進行標註。最終,作者建立了由 542 個任務組成的 Mind2Web-Live 資料集, 其中包含了 438 個訓練樣本和 104 個用於測試的樣本。下圖直觀地展示了標註結果和評估函數的分佈。

資料標註工具
資料標註過程中,作者使用了跨越星空科技開發的 iMean Builder 瀏覽器外掛程式。該外掛程式能夠記錄使用者瀏覽器互動行為,包括但不限於點擊、文字輸入、懸浮、拖曳等動作,同時記錄操作的具體類型、執行參數、目標元素的 Selector 路徑,以及元素內容和頁面座標位置。此外,iMean Builder 還為每個步驟產生網頁截圖,為驗證和維護工作流程提供了直覺的展示。
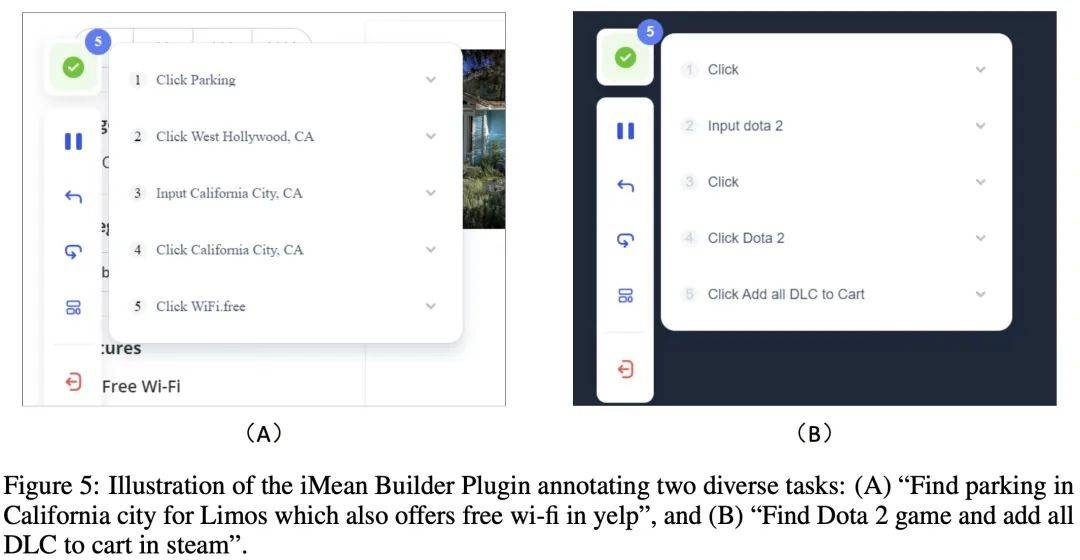
範例:使用 iMean Builder 外掛程式註解兩個不同的任務。 (A) 在Yelp 上尋找加州提供免費Wi-Fi 的豪華轎車停車場,(B) 在Steam 上查找Dota 2 遊戲並將所有DLC 添加到購物車中
數據維護
網絡環境瞬息萬變網絡環境瞬息萬變,網站內容的更新、使用者介面的調整乃至網站的關閉都是不可避免的常態。這些變化可能導致先前定義的任務或關鍵節點失去時效性,進而影響評測的有效性和公平性。
為此,作者設計了一套資料維護方案,旨在確保評測集的持續相關性和準確性。在資料收集階段,除了標註關鍵節點外,iMean Builder 插件還能夠詳細記錄每一步工作流程執行的信息,包括動作類型、Selector 路徑、元素值以及座標位置等。後續使用 iMean Replay SDK 的元素匹配策略就能重現工作流程動作,並及時發現並報告工作流程或評估函數中的任何無效情況。
透過此方案,我們有效解決了流程失效帶來的挑戰,確保了評測資料集能夠適應網路世界的不斷演變,為自動化評測 Agent 的能力提供了堅實的基礎。
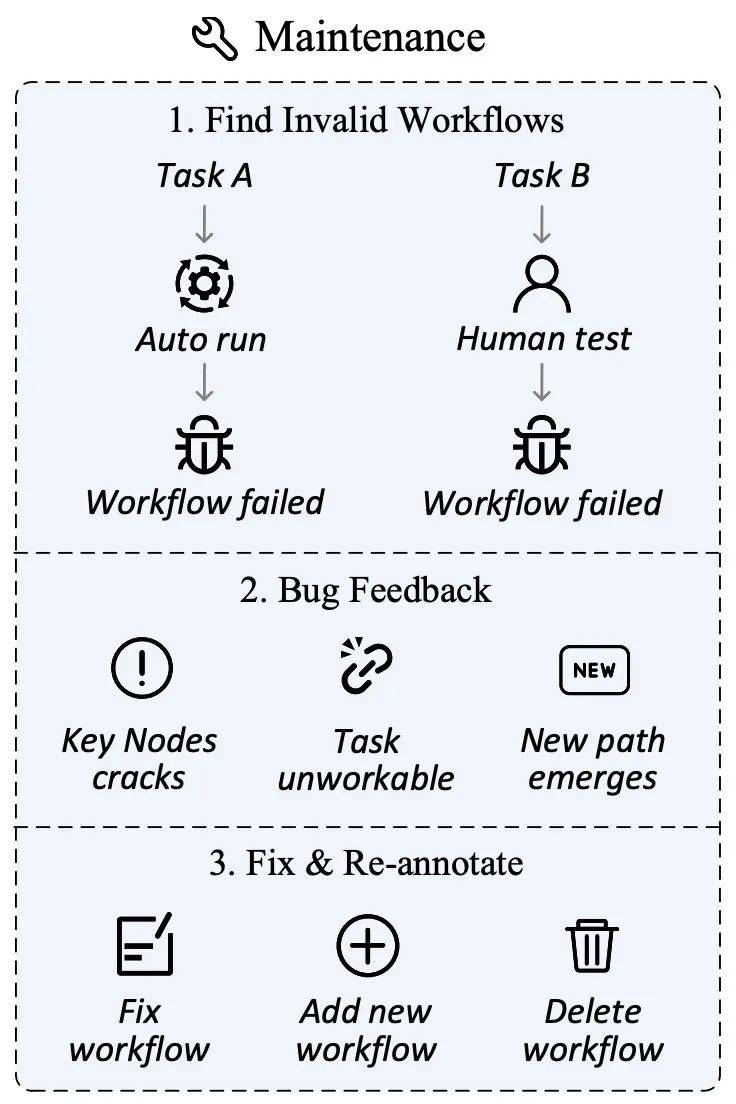
資料管理平台
在WebCanvas 網站上,使用者可以清楚瀏覽所有已錄製的任務流程及其關鍵節點,也能夠迅速向平台管理員回饋失效的流程,確保資料的時效性和準確性。
同時,作者鼓勵社區成員積極參與,共同建構一個良好的生態系統。無論是維護現有資料的完整性,或是開發更先進的 Agent 進行測試,甚至是創造全新的資料集,WebCanvas 都歡迎各種形式的貢獻。這不僅促進了數據品質的提升,也鼓勵技術創新,能夠形成良性循環推動整個領域向前發展。
WebCanvas 網站首頁
Mind2Web-Live 資料集的可視化展示在線上網路環境下的任務執行效率。該框架主要由四個關鍵組件組成:規劃(Planning)、觀察(Observation)、記憶(Memory)以及獎勵(Reward)模組。
規劃(Planning):基於 Accessibility Tree 的輸入,Planning 模組運用 ReAct 推理架構進行邏輯推斷,產生具體的操作指令。此模組的核心功能在於根據目前狀態和任務目標,給予行動路徑。
觀察(Observation):Agent 透過解析瀏覽器提供的 HTML 原始碼,將其轉換成 Accessibility Tree 結構。這個過程確保了 Agent 能夠以標準化格式接收網頁訊息,以便於後續分析和決策。
記憶(Memory):Memory 模組負責儲存 Agent 在任務執行過程中的歷史數據,包括但不限於 Agent 的思考過程、過往的決策等。
獎勵(Reward):Reward 模組能對 Agent 的行為給予評價,包括對決策品質的回饋以及給予任務完成訊號。

基礎 Agent 框架示意圖
主要實驗
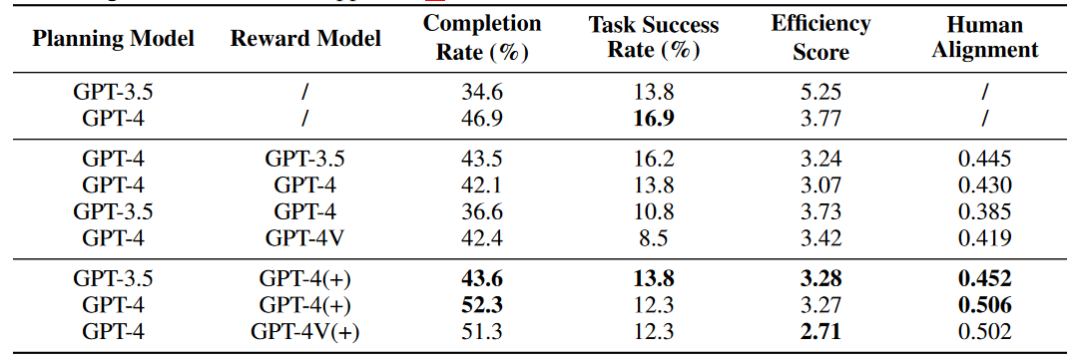
作者使用基礎 Agent 框架並接取不同 LLM 進行評估(不含 Reward 模組評估)。實驗結果如下圖所示,其中 Completion Rate 指的是關鍵節點的達成率,Task Success Rate 指的是任務成功率。
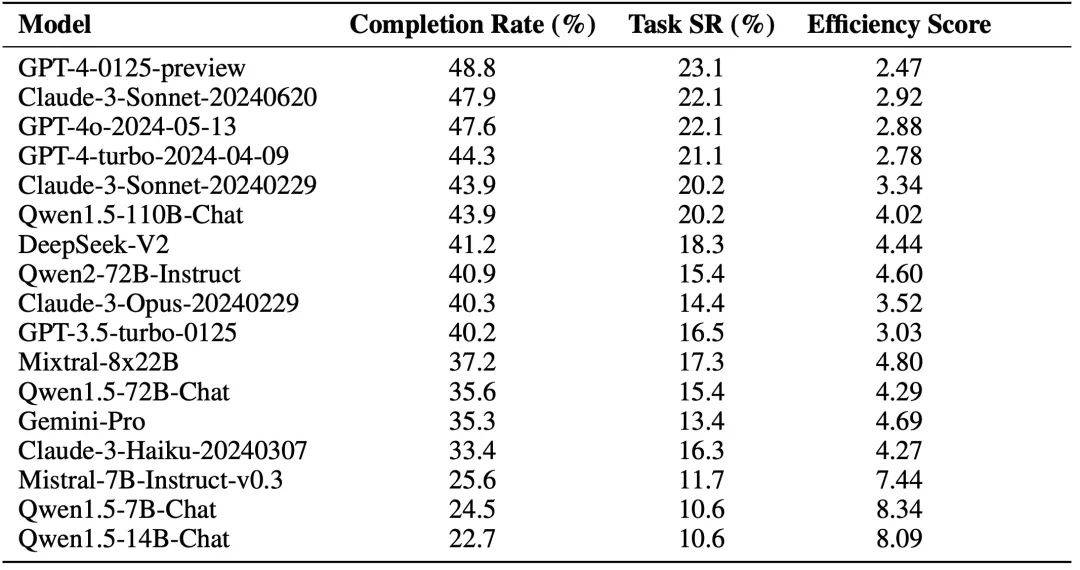

除此之外,作者還探索了Reward 模組對Agent 能力的影響,其中(+) 號代表Reward 資訊中包含人類標註資料以及關鍵節點資訊供Agent 參考,Human Alignment 分數代表Agent 與人類的對齊程度。初步實驗的結果表明,在線上網路環境中,Agent 並不能夠透過 Self Reward 模組改善能力,但是整合了原始標註資料的 Reward 模組能夠增強 Agent 的能力。
實驗分析
在附錄中,作者對實驗結果進行了分析,下圖是任務複雜度與任務難度之間的關係,橙色線條描繪了關鍵節點達成率隨任務複雜度增加的變化軌跡,而藍色線條則反映了任務成功率隨任務複雜度的變化軌跡。
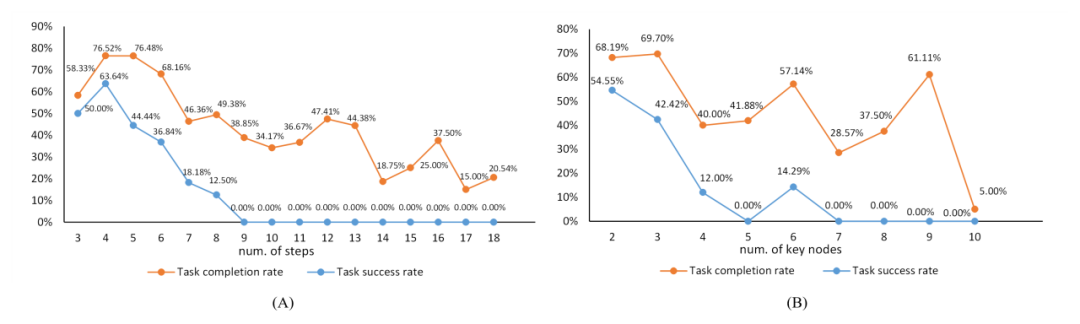
任務複雜度與任務難度之間的關係。 "num of steps" 指的是標註資料中動作序列的長度,與關鍵節點的數量一起作為任務複雜度的參考。
下表是實驗結果與地區、設備、系統之間的關係。

總結
在推動 LLM 和 Agent 技術發展的征途上,建構一套適應真實網路環境的評測體系至關重要。本文聚焦於在瞬息萬變的網路世界中有效地評估 Agent 的表現。我們直面挑戰,透過在開放的環境中界定關鍵節點和對應的評測函數達成了這一目標,並開發資料維護系統減少了後續維護成本。
經過不懈努力,我們已邁出了實質的步伐,並向著建立穩健且精準的線上評測系統前進。然而,在動態的網路空間中進行評測並非易事,它引入了一系列在封閉、離線場景下未曾遭遇的複雜問題。在評測 Agent 的過程中,我們遇到了網路連線不穩定、網站存取限制,以及評測函數的限制等難題。這些問題凸顯出在複雜的真實環境中,對 Agent 進行評測所面臨的艱鉅任務,要求我們不斷精進調整 Agent 的推理和評測框架。
我們呼籲整個科研社群共同協作,以應對未知挑戰,推動評測技術的革新與完善。我們堅信,只有透過持續的研究與實踐,才能逐步克服這些障礙。我們期待與同行們攜手並進,共創 LLM Agent 的新紀元。
The above is the detailed content of To effectively evaluate the actual performance of Agent, the new online evaluation framework WebCanvas is here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
In modern manufacturing, accurate defect detection is not only the key to ensuring product quality, but also the core of improving production efficiency. However, existing defect detection datasets often lack the accuracy and semantic richness required for practical applications, resulting in models unable to identify specific defect categories or locations. In order to solve this problem, a top research team composed of Hong Kong University of Science and Technology Guangzhou and Simou Technology innovatively developed the "DefectSpectrum" data set, which provides detailed and semantically rich large-scale annotation of industrial defects. As shown in Table 1, compared with other industrial data sets, the "DefectSpectrum" data set provides the most defect annotations (5438 defect samples) and the most detailed defect classification (125 defect categories
 Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Editor |KX To this day, the structural detail and precision determined by crystallography, from simple metals to large membrane proteins, are unmatched by any other method. However, the biggest challenge, the so-called phase problem, remains retrieving phase information from experimentally determined amplitudes. Researchers at the University of Copenhagen in Denmark have developed a deep learning method called PhAI to solve crystal phase problems. A deep learning neural network trained using millions of artificial crystal structures and their corresponding synthetic diffraction data can generate accurate electron density maps. The study shows that this deep learning-based ab initio structural solution method can solve the phase problem at a resolution of only 2 Angstroms, which is equivalent to only 10% to 20% of the data available at atomic resolution, while traditional ab initio Calculation
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
For AI, Mathematical Olympiad is no longer a problem. On Thursday, Google DeepMind's artificial intelligence completed a feat: using AI to solve the real question of this year's International Mathematical Olympiad IMO, and it was just one step away from winning the gold medal. The IMO competition that just ended last week had six questions involving algebra, combinatorics, geometry and number theory. The hybrid AI system proposed by Google got four questions right and scored 28 points, reaching the silver medal level. Earlier this month, UCLA tenured professor Terence Tao had just promoted the AI Mathematical Olympiad (AIMO Progress Award) with a million-dollar prize. Unexpectedly, the level of AI problem solving had improved to this level before July. Do the questions simultaneously on IMO. The most difficult thing to do correctly is IMO, which has the longest history, the largest scale, and the most negative
 PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
In 2023, almost every field of AI is evolving at an unprecedented speed. At the same time, AI is constantly pushing the technological boundaries of key tracks such as embodied intelligence and autonomous driving. Under the multi-modal trend, will the situation of Transformer as the mainstream architecture of AI large models be shaken? Why has exploring large models based on MoE (Mixed of Experts) architecture become a new trend in the industry? Can Large Vision Models (LVM) become a new breakthrough in general vision? ...From the 2023 PRO member newsletter of this site released in the past six months, we have selected 10 special interpretations that provide in-depth analysis of technological trends and industrial changes in the above fields to help you achieve your goals in the new year. be prepared. This interpretation comes from Week50 2023
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
Editor | KX Retrosynthesis is a critical task in drug discovery and organic synthesis, and AI is increasingly used to speed up the process. Existing AI methods have unsatisfactory performance and limited diversity. In practice, chemical reactions often cause local molecular changes, with considerable overlap between reactants and products. Inspired by this, Hou Tingjun's team at Zhejiang University proposed to redefine single-step retrosynthetic prediction as a molecular string editing task, iteratively refining the target molecular string to generate precursor compounds. And an editing-based retrosynthetic model EditRetro is proposed, which can achieve high-quality and diverse predictions. Extensive experiments show that the model achieves excellent performance on the standard benchmark data set USPTO-50 K, with a top-1 accuracy of 60.8%.
 Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Editor | ScienceAI Based on limited clinical data, hundreds of medical algorithms have been approved. Scientists are debating who should test the tools and how best to do so. Devin Singh witnessed a pediatric patient in the emergency room suffer cardiac arrest while waiting for treatment for a long time, which prompted him to explore the application of AI to shorten wait times. Using triage data from SickKids emergency rooms, Singh and colleagues built a series of AI models that provide potential diagnoses and recommend tests. One study showed that these models can speed up doctor visits by 22.3%, speeding up the processing of results by nearly 3 hours per patient requiring a medical test. However, the success of artificial intelligence algorithms in research only verifies this
