Large language models (LLM) are increasingly used in various fields. However, their text generation process is expensive and slow. This inefficiency is attributed to the algorithm of autoregressive decoding: the generation of each word (token) requires a forward pass, requiring access to an LLM with billions to hundreds of billions of parameters. This results in traditional autoregressive decoding being slower. Recently, the University of Waterloo, the Canadian Vector Institute, Peking University and other institutions jointly released EAGLE, which aims to improve the inference speed of large language models while ensuring a consistent distribution of model output text. This method extrapolates the second top-level feature vector of LLM, which can significantly improve the generation efficiency. 
- Technical report: https://sites.google.com/view/eagle-llm
- Code (supports commercial Apache 2.0): https://github.com/SafeAILab/EAGLE
EAGLE has the following features:
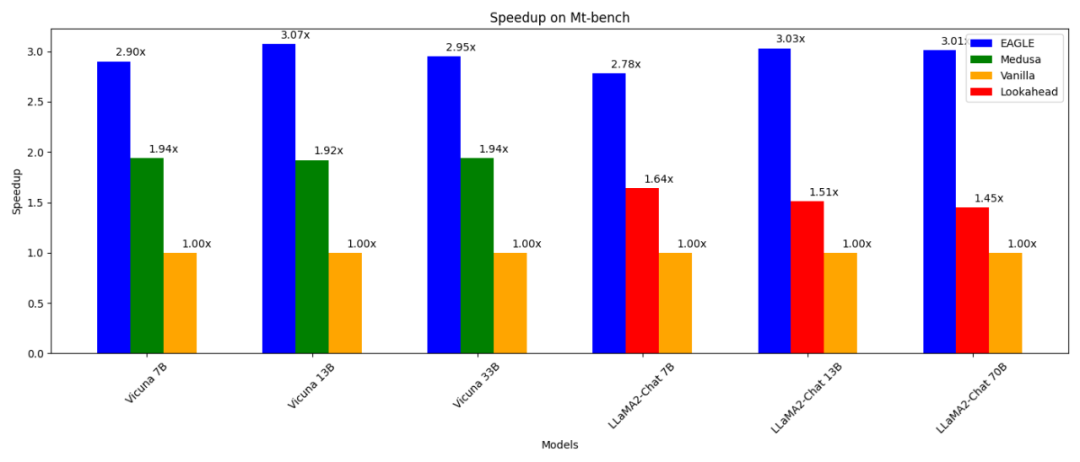
- 3 times faster than ordinary autoregressive decoding (13B);
- 2 times faster than Lookahead decoding (13B);
- than Medusa Decode (13B) 1.6 times faster;
- can be proven to be consistent with ordinary decoding in the distribution of generated text;
- can be trained (in 1-2 days) and tested on RTX 3090;
- can Use in conjunction with other parallel technologies such as vLLM, DeepSpeed, Mamba, FlashAttention, quantization and hardware optimization.
One way to speed up autoregressive decoding is speculative sampling. This technique uses a smaller draft model to guess the next multiple words via standard autoregressive generation. The original LLM then verifies these guessed words in parallel (requiring only one forward pass for verification). If the draft model accurately predicts α words, a single forward pass of the original LLM can generate α+1 words. In speculative sampling, the task of the draft model is to predict the next word based on the current word sequence. Accomplishing this task using a model with a significantly smaller number of parameters is extremely challenging and often yields suboptimal results. Furthermore, the draft model in the standard speculative sampling approach independently predicts the next word without leveraging the rich semantic information extracted by the original LLM, resulting in potential inefficiencies. This limitation inspired the development of EAGLE. EAGLE utilizes the contextual features extracted by the original LLM (i.e., the feature vector output by the second top layer of the model). EAGLE is built on the following first principles: Feature vector sequences are compressible, so it is easier to predict subsequent feature vectors based on previous feature vectors. EAGLE trains a lightweight plug-in called the Auto-regression Head that, together with the word embedding layer, predicts the next feature from the second top layer of the original model based on the current feature sequence. The frozen classification head of the original LLM is then used to predict the next word. Features contain more information than word sequences, making the task of regressing features much simpler than the task of predicting words. In summary, EAGLE extrapolates at the feature level, using a small autoregressive head, and then utilizes a frozen classification head to generate predicted word sequences. Consistent with similar work such as Speculative Sampling, Medusa, and Lookahead, EAGLE focuses on the latency of per-cue inference rather than overall system throughput. EAGLE - a method to enhance the efficiency of large language model generation 
The above figure shows the difference in input and output between EAGLE and standard speculative sampling, Medusa and Lookahead. The figure below shows the workflow of EAGLE. In the forward pass of the original LLM, EAGLE collects features from the second top layer. The autoregressive head takes these features and the word embeddings of previously generated words as input and starts guessing the next word. Subsequently, the frozen classification head (LM Head) is used to determine the distribution of the next word, allowing EAGLE to sample from this distribution. By repeating sampling multiple times, EAGLE performs a tree-like generation process, as shown on the right side of the figure below. In this example, EAGLE’s triple forward pass “guessed” a tree of 10 words. 
EAGLE uses a lightweight autoregressive head to predict features of the original LLM. To ensure the consistency of the generated text distribution, EAGLE then validates the predicted tree structure. This verification process can be completed using a forward pass. Through this cycle of prediction and verification, EAGLE is able to quickly generate text words. The cost of training an autoregressive head is very small. EAGLE is trained using the ShareGPT dataset, which contains just under 70,000 dialogue rounds. The number of trainable parameters of the autoregressive head is also very small. As shown in blue in the image above, most components are frozen. The only additional training required is the autoregressive head, which is a single-layer Transformer structure with 0.24B-0.99B parameters. Autoregressive heads can be trained even when GPU resources are insufficient. For example, Vicuna 33B's autoregressive regression can be trained in 24 hours on an 8-card RTX 3090 server. Why use word embeddings to predict features? Medusa only uses the features of the second top layer to predict the next word, the next word... Unlike Medusa, EAGLE also dynamically uses the currently sampled word embedding as input to the autoregressive head part to make predictions. This additional information helps EAGLE handle the inevitable randomness in the sampling process. Consider the example in the image below, assuming the prompt word is "I". LLM gives the probability that "I" is followed by "am" or "always". Medusa does not consider whether "am" or "always" is sampled, and directly predicts the probability of the next word under "I". Therefore, Medusa's goal is to predict the next word for "I am" or "I always" given only "I". Due to the randomness of the sampling process, the same input "I" to Medusa may have a different next word output "ready" or "begin", resulting in a lack of consistent mapping between inputs and outputs. In contrast, the input to EAGLE includes the word embeddings of the sampled results, ensuring a consistent mapping between input and output. This distinction allows EAGLE to more accurately predict subsequent words by taking into account the context established by the sampling process. 
Tree-like generation structureDifferent from other guessing-verification frameworks such as speculative sampling, Lookahead and Medusa, EAGLE adopts a tree-like generation structure in the "guessing word" stage, thereby achieving a more High decoding efficiency. As shown in the figure, the generation process of standard speculative sampling and Lookahead is linear or chained. Since the context cannot be constructed during the guessing stage, Medusa's method generates trees through Cartesian product, resulting in a fully connected graph between adjacent layers. This approach often results in meaningless combinations, such as "I am begin." In contrast, EAGLE creates a sparser tree structure. This sparse tree structure prevents the formation of meaningless sequences and focuses computing resources on more reasonable word combinations. 
Multiple rounds of speculative samplingThe standard speculative sampling method maintains the consistency of distribution during the process of "guessing words". In order to adapt to tree-like word guessing scenarios, EAGLE extends this method into a multi-round recursive form. Pseudocode for multiple rounds of speculative sampling is presented below. During the tree generation process, EAGLE records the probability corresponding to each sampled word. Through multiple rounds of speculative sampling, EAGLE ensures that the final generated distribution of each word is consistent with that of the original LLM. 
Lebih banyak hasil percubaanRajah berikut menunjukkan kesan pecutan EAGLE pada Vicuna 33B pada tugasan yang berbeza. Tugas "Pengekodan" yang melibatkan sejumlah besar templat tetap menunjukkan prestasi pecutan terbaik. 
Alu-alukan semua orang untuk mengalami EAGLE dan berikan maklum balas dan cadangan melalui isu GitHub: https://github.com/SafeAILab/EAGLE/issuesThe above is the detailed content of The inference efficiency of large models has been improved by 3 times without loss, and the University of Waterloo, Peking University and other institutions released EAGLE. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



