The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The main author of this article is Huang Yichong. Huang Yichong is a doctoral student at the Social Computing and Information Retrieval Research Center of Harbin Institute of Technology and an intern at Pengcheng Laboratory. He studies under Professor Qin Bing and Professor Feng Xiaocheng. Research directions include large language model ensemble learning and multi-language large models. Related papers have been published in top natural language processing conferences ACL, EMNLP, and COLING. As large language models demonstrate amazing language intelligence, major AI companies have launched their own large models. These large models usually have their own strengths in different fields and tasks. How to integrate them to tap their complementary potential has become a frontier topic in AI research. Recently, researchers from Harbin Institute of Technology and Pengcheng Laboratory proposed the "Training-free heterogeneous large model integrated learning framework" DeePEn. Different from previous methods that train external modules to filter and fuse responses generated by multiple models, DeePEn fuses the probability distributions of multiple model outputs during the decoding process and jointly determines the output token of each step. In comparison, this method can not only be quickly applied to any model combination, but also allows the integrated models to access each other's internal representations (probability distributions), enabling deeper model collaboration. The results show that DeePEn can achieve significant improvements on multiple public data sets, effectively expanding the performance boundaries of large models: 
The current paper and code have been made public:
- Paper Title: Ensemble Learning for Heterogeneous LargeLanguage Models with Deep Parallel Collaboration
- Paper address: https://arxiv.org/abs/2404.12715
- Code address: https://github.com/OrangeInSouth/DeePEn
The core difficulty of heterogeneous large model integration is how to solve the vocabulary difference problem between models. To this end, DeePEn builds a unified relative representation space composed of shared tokens between multiple model vocabularies based on relative representation theory. In the decoding stage, DeePEn maps the probability distributions output by different large models to this space for fusion. No parameter training is required in the whole process. The image below shows DeePEn’s method. Given N models for ensemble, DeePEn first builds their transformation matrices (i.e., relative representation matrices), mapping probability distributions from multiple heterogeneous absolute spaces into a unified relative space. At each decoding step, all models perform forward computations and output N probability distributions. These distributions are mapped into relative space and aggregated. Finally, the aggregation results are transformed back into the absolute space of some model (the master model) to determine the next token.
Figure 1: Schematic diagram. Among them, the relative representation transformation matrix is obtained by calculating the word embedding similarity between each token in the vocabulary and the anchor token shared between models. Construct a relative representation transformation Given N models to be integrated, DeePEn first finds the intersection of all model vocabularies, that is, the shared vocabulary , And extract a subset A⊆C or use all shared words as the anchor word set A=C. For each model , DeePEn calculates the embedding similarity between each token in the vocabulary and the anchor token to obtain a relative representation matrix . Finally, in order to overcome the relative representation degradation problem of outlier words, the author of the paper performs row normalization on the relative representation matrix and performs a softmax operation on each row of the matrix to obtain the normalized relative representation matrix . Relative representation fusion In each decoding step, once the model outputs the probability distribution , DeePEn uses the normalized relative representation matrix to convert into a relative representation :
and perform a weighted average of all relative representations to obtain the aggregated relative representation: where is the collaboration weight of the model . The authors tried two methods of determining collaborative weight values: (1) DeePEn-Avg, which uses the same weights for all models; (2) DeePEn-Adapt, which sets weights for each model proportionally based on its validation set performance .
Relative representation inverse mappingTo decide the next token based on the aggregated relative representation, DeePEn converts it from the relative space back to the absolute space of the main model (the best performing model on the development set). In order to achieve this inverse transformation, DeePEn adopts a search-based strategy to find the absolute representation whose relative representation is the same as the aggregated relative representation:
where represents the absolute space of the model , and is the measure of the relative representation. loss function (KL divergence) between distances. DeePEn utilizes the gradient of the loss function with respect to the absolute representation to guide the search process and performs the search iteratively. Specifically, DeePEn initializes the starting point of the search to the original absolute representation of the master model and updates it:
Where η is a hyperparameter called the relative ensemble learning rate, and T is the number of search iteration steps. Finally, use the updated absolute representation to determine the token to be output in the next step.
Table 1: Main experiment results. The first part is the performance of a single model, the second part is ensemble learning of the top-2 models on each data set, and the third part is the integration of top-4 models. Through experiments, the author of the paper came to the following conclusions: (1) Large models have their own strengths in different tasks. As shown in Table 1, there are significant differences in the performance of different large models on different datasets. For example, LLaMA2-13B achieved the highest results on the TriviaQA and NQ data sets, but did not rank in the top four on the other four tasks. (2) Distribution fusion has achieved consistent improvements on various data sets. As shown in Table 1, DeePEn-Avg and DeePEn-Adapt achieved performance improvements on all datasets. On GSM8K, combined with voting, a performance improvement of +11.35 was achieved. Table 2: Ensemble learning performance under different number of models.
As the number of integrated models increases, the integration performance first increases and then decreases
. The author adds the models to the ensemble in order from high to low according to the model performance, and then observes the performance changes. As shown in Table 2, as models with poor performance are continuously introduced, the integration performance first increases and then decreases.
Table 3: Ensemble learning between large models and translation expert models on the multilingual machine translation dataset Flores.
Integrate large models and expert models to effectively improve the performance of specific tasks
. The authors also integrated the large model LLaMA2-13B and the multilingual translation model NLLB on machine translation tasks. As shown in Table 3, the integration between a general large model and a task-specific expert model can significantly improve performance.
There are an endless stream of large models, but it is difficult for one model to comprehensively crush other models on all tasks. Therefore, how to take advantage of the complementary advantages between different models has become an important research direction. The DeePEn framework introduced in this article solves the problem of vocabulary differences between different large models in distribution fusion without any parameter training. A large number of experiments show that DeePEn has achieved stable performance improvements in ensemble learning settings with different tasks, different model numbers, and different model architectures. The above is the detailed content of LLama+Mistral+…+Yi=? The training-free heterogeneous large model integrated learning framework DeePEn is here. For more information, please follow other related articles on the PHP Chinese website!






 , And extract a subset A⊆C or use all shared words as the anchor word set A=C.
, And extract a subset A⊆C or use all shared words as the anchor word set A=C.  , DeePEn calculates the embedding similarity between each token in the vocabulary and the anchor token to obtain a relative representation matrix
, DeePEn calculates the embedding similarity between each token in the vocabulary and the anchor token to obtain a relative representation matrix 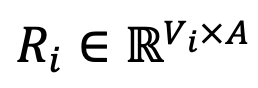 . Finally, in order to overcome the relative representation degradation problem of outlier words, the author of the paper performs row normalization on the relative representation matrix and performs a softmax operation on each row of the matrix to obtain the normalized relative representation matrix
. Finally, in order to overcome the relative representation degradation problem of outlier words, the author of the paper performs row normalization on the relative representation matrix and performs a softmax operation on each row of the matrix to obtain the normalized relative representation matrix 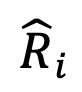 .
.  outputs the probability distribution
outputs the probability distribution  , DeePEn uses the normalized relative representation matrix to convert
, DeePEn uses the normalized relative representation matrix to convert  into a relative representation
into a relative representation  :
: 
 where
where  is the collaboration weight of the model
is the collaboration weight of the model 
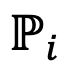 represents the absolute space of the model
represents the absolute space of the model 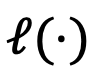 is the measure of the relative representation. loss function (KL divergence) between distances.
is the measure of the relative representation. loss function (KL divergence) between distances.  with respect to the absolute representation
with respect to the absolute representation 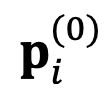 to the original absolute representation of the master model and updates it:
to the original absolute representation of the master model and updates it: 
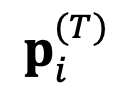 to determine the token to be output in the next step.
to determine the token to be output in the next step. 


 How to flash Xiaomi phone
How to flash Xiaomi phone
 How to center div in css
How to center div in css
 How to open rar file
How to open rar file
 Methods for reading and writing java dbf files
Methods for reading and writing java dbf files
 How to solve the problem that the msxml6.dll file is missing
How to solve the problem that the msxml6.dll file is missing
 Commonly used permutation and combination formulas
Commonly used permutation and combination formulas
 Virtual mobile phone number to receive verification code
Virtual mobile phone number to receive verification code
 dynamic photo album
dynamic photo album








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



