

The first simulated interactive 3D society specially designed for various robots.
Remember Stanford’s AI Town? This is a virtual environment created by AI researchers at Stanford. In this small town, 25 AI agents live, work, socialize, and even fall in love normally. Each agent has its own personality and background story. The agent's behavior and memory are driven by large language models that store and retrieve the agent's experiences and plan actions based on these memories. (See "Stanford's "virtual town" is open source: 25 AI agents light up "Westworld"")
Similarly, recently, a group of researchers from Shanghai Artificial Intelligence Laboratory OpenRobotLab and other institutions A group of researchers also created a virtual town. However, living among them are robots and NPCs.  Containing 100,000 interactive scenes and 89 different scene categories, this town is the first simulated interactive 3D society designed specifically for various robots.
Containing 100,000 interactive scenes and 89 different scene categories, this town is the first simulated interactive 3D society designed specifically for various robots.

The authors stated that they designed this environment to solve the data scarcity problem in the field of embodied intelligence. As we all know, exploring scaling law in the field of embodied intelligence has been difficult due to the high cost of collecting real-world data. Therefore, the simulation-to-real (Sim2Real) paradigm becomes a critical step in extending embodied model learning.
The virtual environment they designed for robots is called GRUtopia. The project mainly includes:
1. Scene data set GRScenes. Contains 100,000 interactive, finely annotated scenes that can be freely combined into city-scale environments. Unlike previous work that mainly focused on the home, GRScenes covers 89 different scene categories, filling the gap in service-oriented environments (where robots are typically initially deployed).
2. GRResidents. This is a large language model (LLM) driven non-player character (NPC) system responsible for social interaction, task generation and task allocation, thereby simulating social scenarios for embodied AI applications.
3. Benchmark GRBench. Various robots are supported, but focus is on legged robots as the main agent, and moderately difficult tasks involving object localization navigation, social localization navigation, and localization manipulation are proposed.
The authors hope that this work will alleviate the scarcity of high-quality data in the field and provide a more comprehensive assessment of embodied AI research.

Paper title: GRUtopia: Dream General Robots in a City at Scale
Paper address: https://arxiv.org/pdf/2407.10943
Project address: https://github .com/OpenRobotLab/GRUtopia
GRScenes: Fully Interactive Environments at Large Scale
To build a platform for training and evaluating embodied agents, a fully interactive environment with different scene and object assets is a must Indispensable. Therefore, the authors collected a large-scale 3D synthetic scene dataset containing various object assets as the basis of the GRUtopia platform.
Diverse, realistic scenes
Due to the limited number and category of open source 3D scene data, the author first collected about 100,000 high-quality synthetic scenes from designer websites to obtain diverse scene prototypes. They then cleaned these scene prototypes, annotated them with region- and object-level semantics, and finally combined them to form towns that served as the robot's basic playground.
As shown in Figure 2-(a), in addition to common home scenes, the data set constructed by the author also has 30% of other different categories of scenes, such as restaurants, offices, public places, hotels, entertainment, etc. The authors initially screened 100 finely annotated scenes from a large-scale dataset for open source benchmarking. These 100 scenes include 70 home scenes and 30 business scenes, where the home scene consists of comprehensive common areas and other different areas, and the business scenes cover common types such as hospitals, supermarkets, restaurants, schools, libraries, and offices.
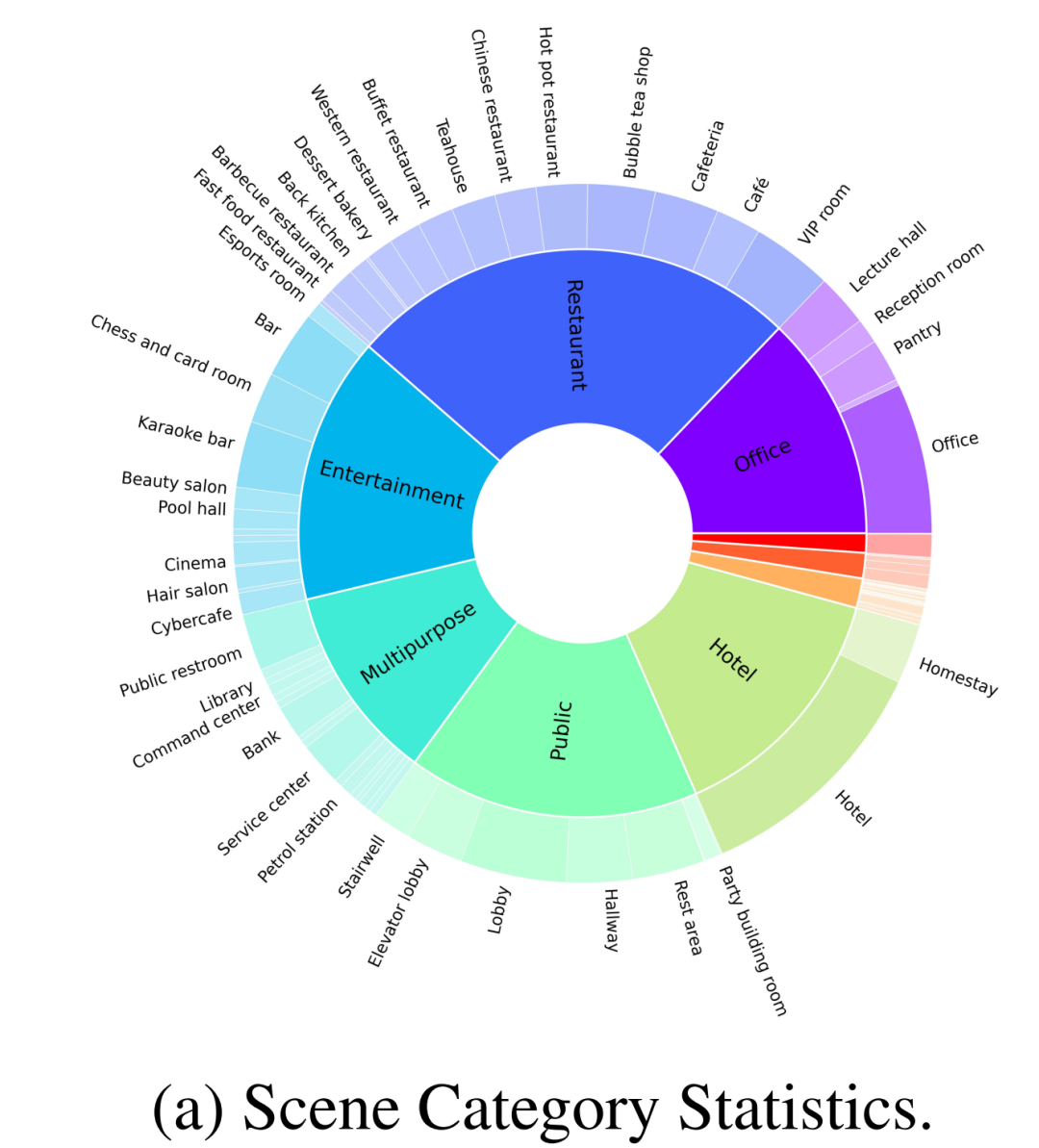
In addition, the author also cooperated with several professional designers to allocate objects according to human living habits to make these scenes more realistic, as shown in Figure 1, which is usually ignored in previous works.
Interactive objects with part-level annotations
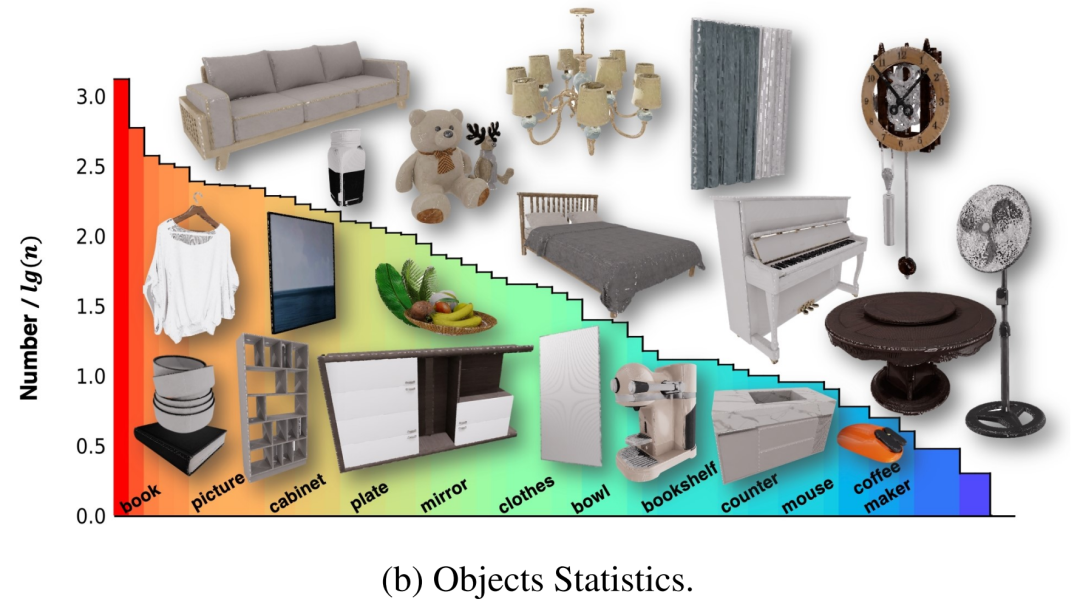
These scenes originally contained multiple 3D objects, but some of them were not modeled internally, so the robot could not be trained to interact with these objects. To solve this problem, the authors worked with a team of professionals to modify these assets and create complete objects that allowed them to interact in a physically believable way. Additionally, to provide more comprehensive information that enables agents to interact with these assets, the authors attached fine-grained part labels in the form of X to the interactive parts of all objects in NVIDIA Omniverse. Finally, the 100 scenes contain 2956 interactive objects and 22001 non-interactive objects in 96 categories, and their distribution is shown in Figure 2-(b).
Hierarchical multimodal annotation
Finally, in order to achieve multimodal interaction of embodied agents with the environment and NPC, these scenes and objects also need to be linguistically annotated. Unlike previous multimodal 3D scene datasets that only focused on the object level or relationships between objects, the authors also considered different granularities of scene elements, such as the relationship between objects and regions. Given the lack of region labels, the authors first designed a user interface to annotate regions with polygons on a bird's-eye view of the scene, which could then involve object-region relationships in the linguistic annotation. For each object, they prompt a powerful VLM (such as GPT-4v) with rendered multi-view images to initialize annotations, which are then inspected by humans. The resulting linguistic annotations provide the basis for subsequent benchmark generation embodied tasks.
GRResidents3D environment generative NPCs
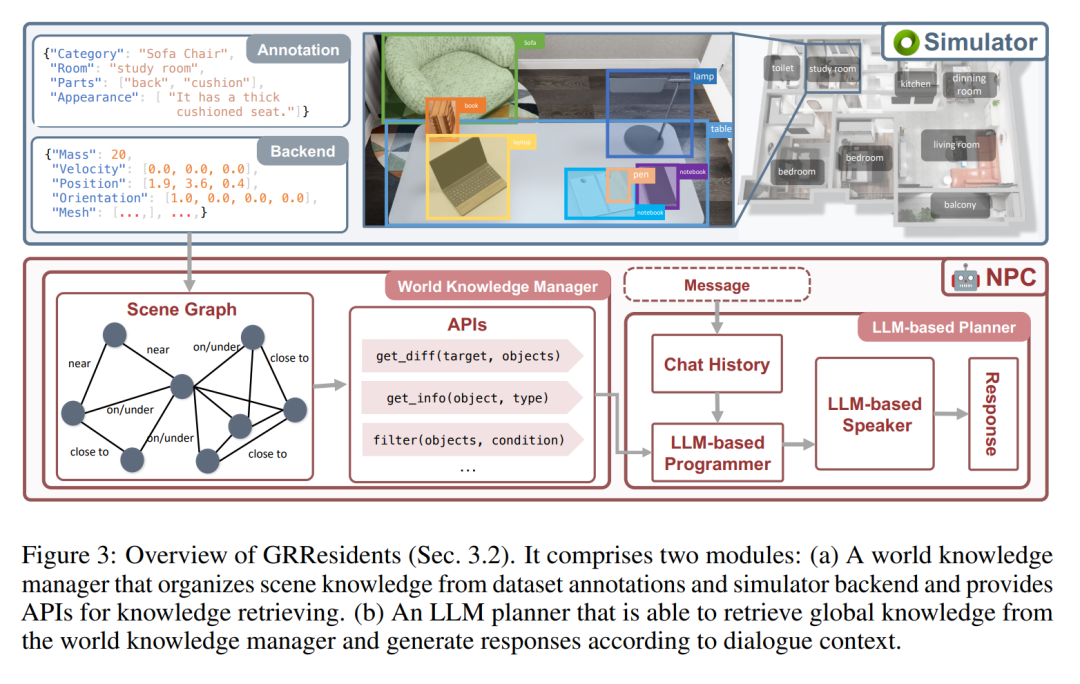
In GRUtopia, the author gives the world social capabilities by embedding some "residents" (i.e. generative NPCs driven by LLM) to simulate social interactions in urban environments. This NPC system is named GRResidents. One of the main challenges in building realistic virtual characters in 3D scenes is integrating 3D perception capabilities. However, virtual characters can easily access scene annotations and the internal state of the simulated world, enabling powerful perception capabilities. To this end, the authors designed a World Knowledge Manager (WKM) to manage dynamic knowledge of real-time world states and provide access through a series of data interfaces. With WKM, NPCs can retrieve the required knowledge and perform fine-grained object grounding through parameterized function calls, which forms the core of their sentience capabilities.
World Knowledge Manager (WKM)
The main responsibility of WKM is to continuously manage virtual environment knowledge and provide advanced scene knowledge to NPCs. Specifically, WKM obtains hierarchical annotations and scene knowledge from the dataset and simulator backend respectively, and constructs a scene graph as a scene representation, where each node represents an object instance and edges represent spatial relationships between objects. The authors adopt the spatial relations defined in Sr3D as the relational space. WKM retains this scene graph at each simulation step. In addition, WKM also provides three core data interfaces for extracting knowledge from scene graphs:
1, find_diff (target, objects): compares the difference between the target object and a set of other objects;
2, get_info (object, type): Obtain object knowledge according to the required attribute type;
3. filter (objects, condition):: Filter objects according to conditions.
LLM Planner
NPC’s decision-making module is an LLM-based planner, consisting of three parts (Figure 3): a storage module used to store the chat history between NPC and other agents; An LLM programmer uses the interface of WKM to query scene knowledge; and an LLM speaker is used to digest the chat history and the queried knowledge to generate replies. When an NPC receives a message, it first stores the message in memory and then forwards the updated history to the LLM programmer. Then, the programmer will repeatedly call the data interface to query the necessary scene knowledge. Finally, the knowledge and history are sent to the LLM speaker, which generates a response.
Experiments
The author conducted experiments on object reference, language grounding and object-centric QA to prove that the NPC in the paper can generate object descriptions, locate objects through descriptions, and provide intelligent The body provides object information. NPC backend LLMs in these experiments include GPT-4o, InternLM2-Chat-20B, and Llama-3-70BInstruct.
As shown in Figure 4, in the referential experiment, the authors used human-in-the-loop evaluation. The NPC randomly selects an object and describes it, and the human annotator selects an object based on the description. A reference is successful if the human annotator can find the correct object corresponding to the description. In grounding experiments, GPT-4o played the role of a human annotator, providing a description of an object that was then positioned by the NPC. Grounding is successful if the NPC is able to find the corresponding object.
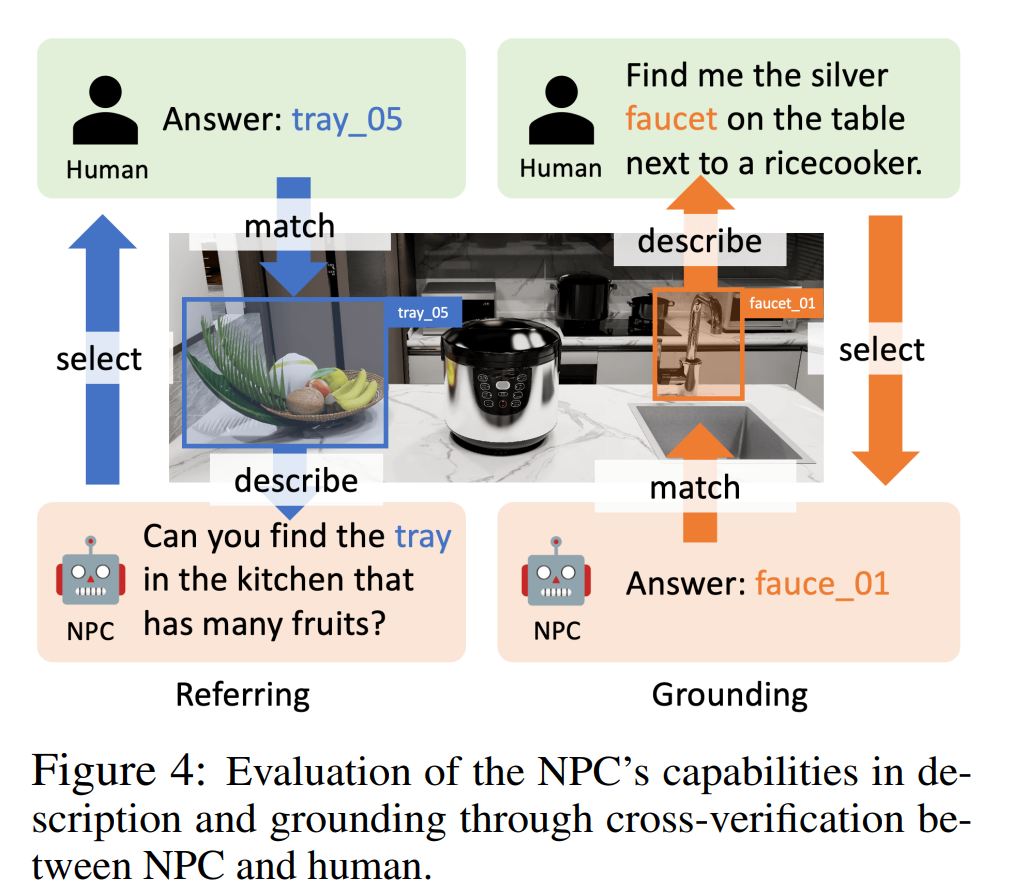
The success rates (referencing and grounding) in Table 2 show that the accuracy rates of different LLMs are 95.9%-100% and 83.3%-93.2% respectively, which verifies that our NPC framework can refer to different LLMs. and grounding accuracy.
In an object-centric QA experiment, the authors evaluated the NPC's ability to provide object-level information to the agent by answering questions in a navigation task. They designed a pipeline to generate object-centric navigation plots that simulate real-world scenarios. In these scenarios, the agent asks the NPC questions to obtain information and takes action based on the answers. Given an agent question, the authors evaluate the NPC based on the semantic similarity between its answer and the real answer. The overall scores shown in Table 2 (QA) indicate that NPCs can provide precise and useful navigation assistance.
GRBench: A Benchmark for Evaluating Embodied Agents
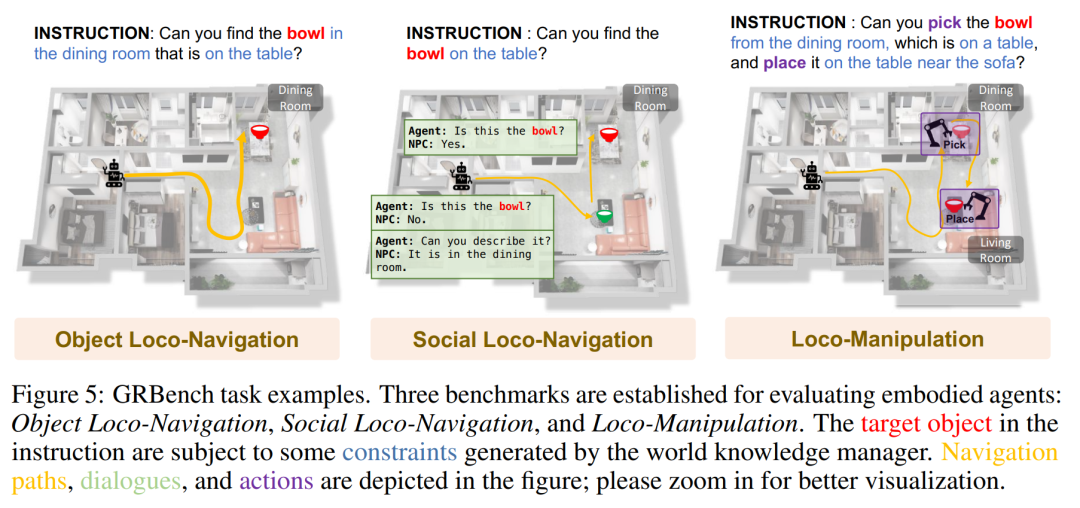
GRBench is a comprehensive evaluation tool for evaluating the capabilities of robotic agents. To evaluate the ability of robotic agents to handle everyday tasks, GRBench includes three benchmarks: object localization navigation, social localization navigation, and localization operations. These benchmarks gradually increase in difficulty and the requirements for the robot's skills increase accordingly.
Due to the legged robot’s excellent ability to cross terrain, the author prioritizes it as the main agent. However, in large-scale scenarios, it is challenging for current algorithms to simultaneously perform high-level perception, planning, and low-level control and achieve satisfactory results.
The latest progress of GRBench has proven the feasibility of training high-precision policies for single skills in simulation. Inspired by this, the initial version of GRBench will focus on high-level tasks and provide learning-based control strategies as APIs, such as walking. and pick and place. As a result, their benchmark provides a more realistic physical environment, bridging the gap between simulation and the real world.
The picture below is some examples of tasks of GRBench.
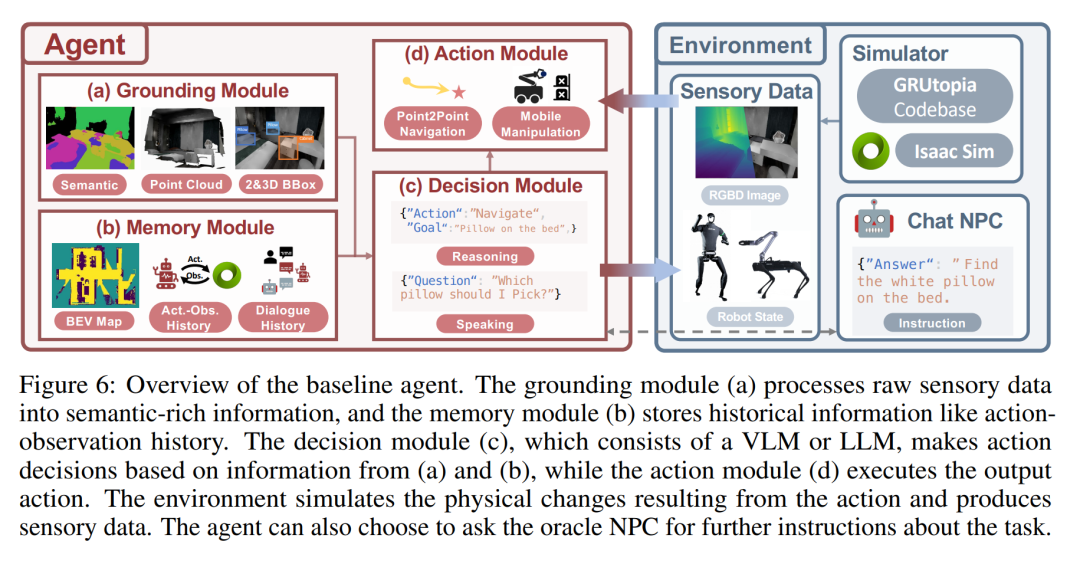
The following figure is an overview of the baseline agent. The grounding module (a) processes raw sensory data into semantically rich information, and the memory module (b) stores historical information such as action observation history. The decision module (c) consists of a VLM or LLM and makes action decisions based on the information from (a) and (b), while the action module (d) executes the output actions. The environment simulates the physical changes brought about by action and generates sensory data. The agent may choose to ask the advisor NPC for further instructions on the task.
Quantitative evaluation results
The author conducted a comparative analysis of large model-driven agent frameworks under different large model backends in three benchmark tests. As shown in Table 4, they found that the performance of the random strategy was close to 0, indicating that their task was not simple. They observed significantly better overall performance in all three benchmarks when using a relatively superior large model as the backend. It is worth mentioning that they observed that Qwen performed better than GPT-4o in dialogue (see Table 5).
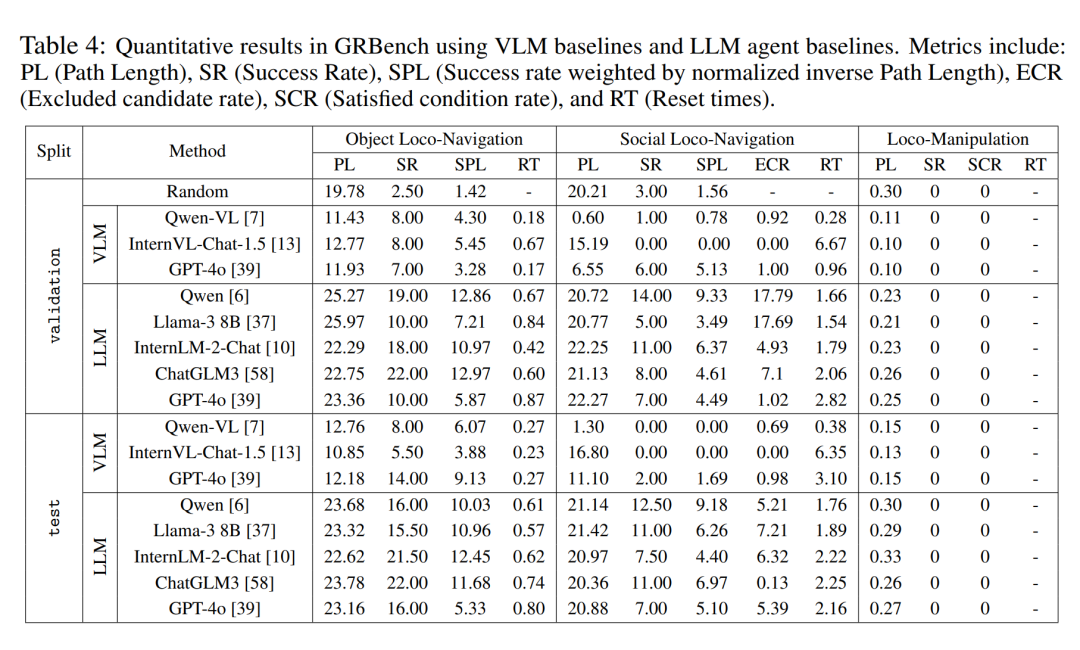

In addition, compared with directly using multi-modal large models for decision-making, the agent framework proposed in this article shows obvious superiority. This demonstrates that even current state-of-the-art multimodal large-scale models lack strong generalization capabilities to real-world embodied tasks. However, the method in this article also has considerable room for improvement. This shows that even a task like navigation that has been studied for many years is still far from fully solved when a task setting that is closer to the real world is introduced.
Qualitative evaluation results
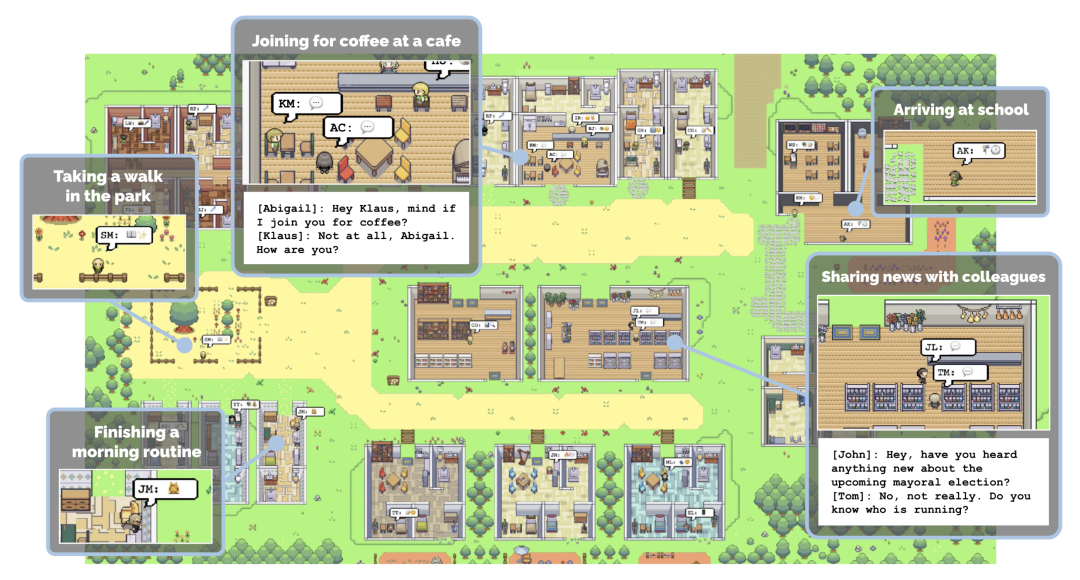
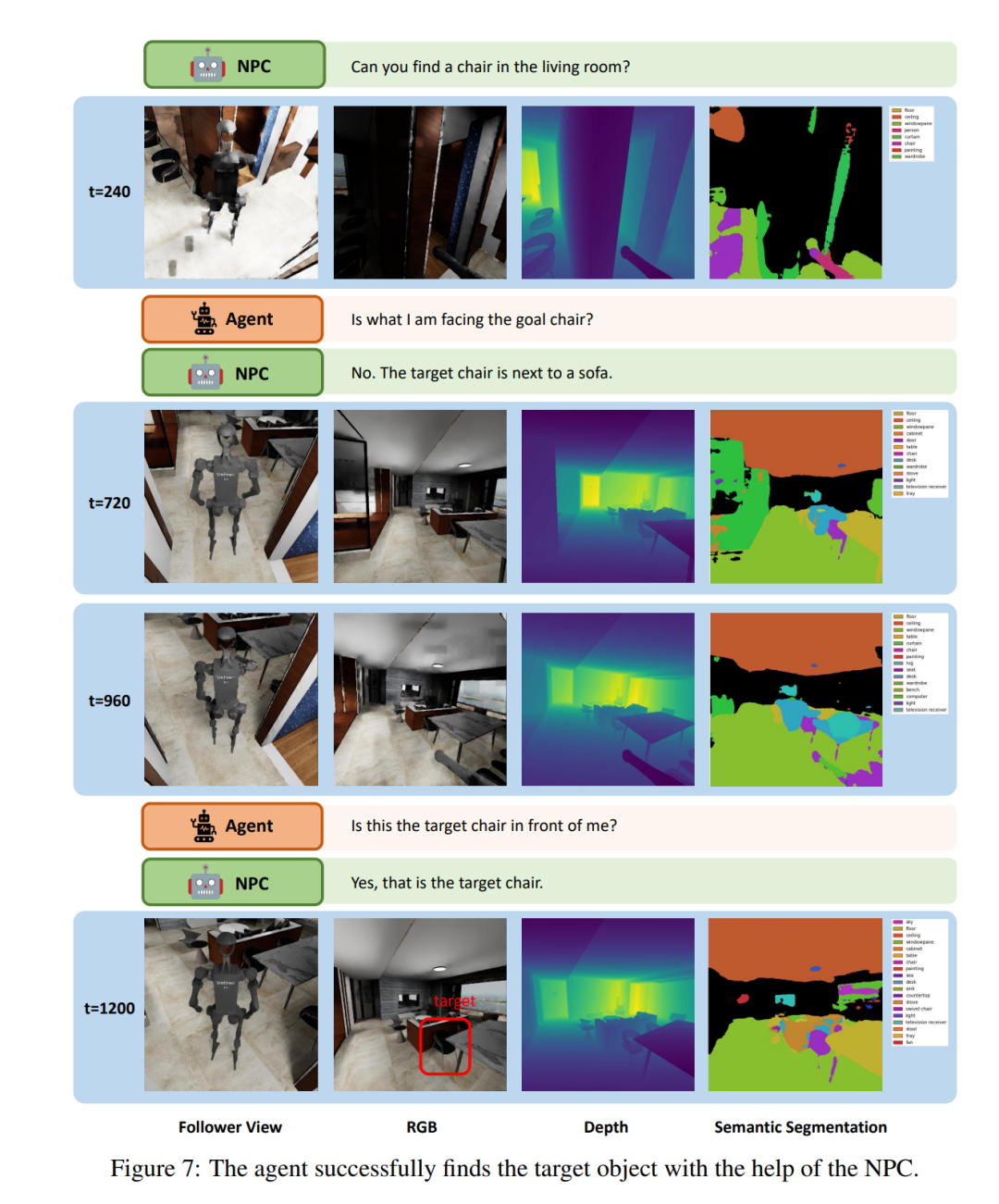
Figure 7 shows a small fragment performed by the LLM agent in the "Social Loco-Navigation" task to illustrate how the agent interacts with NPCs. The agent can talk to the NPC up to three times to query more task information. At t = 240, the agent navigates to a chair and asks the NPC if this chair is the target chair. The NPC then provides peripheral information about the target to reduce ambiguity. With the assistance of the NPC, the agent successfully identified the target chair through an interaction process similar to human behavior. This demonstrates that the NPCs in this paper can provide natural social interactions for studying human-robot interaction and collaboration.
The above is the detailed content of The robot version of 'Stanford Town' is here, specially built for embodied intelligence research. For more information, please follow other related articles on the PHP Chinese website!
 vim save and exit command
vim save and exit command
 How to set path environment variable
How to set path environment variable
 Mysql database migration method
Mysql database migration method
 C++ software Chinese change tutorial
C++ software Chinese change tutorial
 The difference between rest api and api
The difference between rest api and api
 How to use mysql workbench
How to use mysql workbench
 How to use nanosleep function
How to use nanosleep function
 What are the methods for restarting applications in Android?
What are the methods for restarting applications in Android?
 transactionscope usage
transactionscope usage








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



