KAN leads in symbolic representation, but MLP is still a generalist.
Multi-Layer Perceptrons (MLP), also known as fully connected feedforward neural networks, are a basic component of today's deep learning models. The importance of MLP cannot be overstated as it is the default method for approximating nonlinear functions in machine learning. However, MLP also has certain limitations, such as the difficulty in interpreting the learned representations and the difficulty in flexibly scaling the network size. The emergence of KAN (Kolmogorov–Arnold Networks) provides an innovative alternative to traditional MLP. This method outperforms MLP in terms of accuracy and interpretability, and it is able to outperform MLPs running with much larger parameter sizes with a very small number of parameters. So, the question is, which one should I choose between KAN and MLP? Some people support MLP because KAN is just an ordinary MLP and cannot be replaced at all, but others believe that KAN is superior. The current comparison between the two is also limited to different parameters or FLOPs, and the experimental results are unfair. In order to explore the potential of KAN, it is necessary to comprehensively compare KAN and MLP in a fair setting. To this end, researchers from the National University of Singapore trained and evaluated KAN and MLP in tasks in different fields, including symbolic formula representation, machine learning, while controlling the parameters or FLOPs of KAN and MLP. Computer Vision, NLP and Audio Processing. Under these fair settings, they found that KAN only outperformed MLP on the symbolic formula representation task, while MLP generally outperformed KAN on other tasks.
- Paper address: https://arxiv.org/pdf/2407.16674
- Project link: https://github.com/yu-rp/KANbeFair
- Paper title: KAN or MLP: A Fairer Comparison
The author further found that KAN’s advantage in symbolic formula representation stems from its use of B-spline activation function. Initially, the overall performance of MLP lagged behind KAN, but after replacing MLP's activation function with B-splines, its performance matched or even exceeded KAN. However, B-splines cannot further improve the performance of MLP on other tasks such as computer vision. The authors also found that KAN actually performed no better than MLP on continuous learning tasks. The original KAN paper compared the performance of KAN and MLP on a continuous learning task using a series of one-dimensional functions, where each subsequent function is a translation of the previous function along the number axis. This paper compares the performance of KAN and MLP in a more standard class-incremental continuous learning setting. Under fixed training iteration conditions, they found that KAN’s forgetting problem was more serious than MLP. KAN, MLP brief introductionKAN has two branches, the first branch is the B-spline branch, and the other branch is the shortcut branch, that is, nonlinear activation and linear transformation are connected together . In the official implementation, the shortcut branch is a SiLU function followed by a linear transformation. Let x represent the feature vector of a sample. Then, the forward equation of the KAN spline branch can be written as: In the original KAN architecture, the spline function is chosen as the B-spline function. The parameters of each B-spline function are learned together with the other network parameters. Correspondingly, the forward equation of the single-layer MLP can be expressed as: This formula has the same form as the B-spline branch formula in KAN, except that it differs in the nonlinear function. Therefore, regardless of the original paper's interpretation of the KAN structure, KAN can also be regarded as a fully connected layer. Therefore, there are two main differences between KAN and ordinary MLP:
- The activation function is different. Usually the activation function in MLP includes ReLU, GELU, etc., which have no learnable parameters and are uniform for all input elements. In KAN, the activation function is a spline function with learnable parameters, and for each input The elements are all different.
- Sequence of linear and non-linear operations.일반적으로 연구자들은 MLP를 먼저 선형 변환을 수행한 다음 비선형 변환을 수행하는 것으로 개념화하는 반면 KAN은 실제로 비선형 변환을 먼저 수행한 다음 선형 변환을 수행합니다. 그러나 어느 정도 MLP의 완전 연결 레이어를 먼저 비선형으로 설명한 다음 선형으로 설명하는 것도 가능합니다.
KAN과 MLP를 비교함으로써 본 연구에서는 둘의 차이점은 주로 활성화 함수에 있다고 믿습니다. 따라서 그들은 활성화 함수의 차이로 인해 KAN과 MLP가 서로 다른 작업에 적합하고 결과적으로 두 모델 간의 기능적 차이가 발생한다는 가설을 세웠습니다. 이 가설을 테스트하기 위해 연구원들은 다양한 작업에서 KAN과 MLP의 성능을 비교하고 각 모델이 적합한 작업을 설명했습니다. 공정한 비교를 위해 본 연구에서는 먼저 KAN과 MLP의 매개변수 수와 FLOP를 계산하는 공식을 도출한다. 실험 프로세스는 KAN과 MLP의 성능을 비교하기 위해 동일한 수의 매개변수 또는 FLOP를 제어합니다.的 Kan 및 MLP의 매개변수 수와 FLOP의 제어 매개변수 수 ㅋㅋㅋ
🎜🎜🎜 🎜🎜🎜🎜🎜 🎜 🎜🎜🎜🎜🎜🎜, 단축 가중치, B 크기 가중치 가중치 및 편향항. 학습 가능한 매개변수의 총 개수는 다음과 같습니다. 🎜🎜🎜🎜🎜 여기서 d_in과 d_out은 신경망 계층의 입력 및 출력 차원을 나타내고, K는 공식 nn.Module의 매개변수 k에 해당하는 스플라인의 순서를 나타냅니다. 스플라인 함수의 다항식 기저의 차수인 KANLayer입니다. G는 공식 nn.Module KANLayer의 num 매개변수에 해당하는 스플라인 간격 수를 나타냅니다. 채우기 전의 B-스플라인 간격 수입니다. 채우기 전에는 제어점 수 - 1과 같습니다. 채우기 후에는 (K + G) 유효한 제어점이 있어야 합니다. 🎜🎜🎜🎜🎜따라서 MLP 레이어의 학습 가능한 매개 변수는 다음과 같습니다. 🎜🎜🎜🎜🎜🎜KAN 및 MLP의 FLOP🎜🎜🎜🎜🎜🎜저자의 평가에서 모든 산술 연산의 FLOP는 1로 간주됩니다. 부울 연산의 FLOP는 0으로 간주됩니다. De Boor-Cox 알고리즘의 0차 연산은 부동 소수점 연산이 필요하지 않은 일련의 부울 연산으로 변환될 수 있습니다. 따라서 이론적으로 FLOP는 0이다. 이는 부울 데이터를 연산을 위해 부동 소수점 데이터로 다시 변환하는 공식 KAN 구현과 다릅니다. 🎜🎜🎜🎜🎜저자의 평가에서는 하나의 샘플에 대해 FLOP를 계산했습니다. 공식 KAN 코드에서 De Boor-Cox 반복 공식을 사용하여 구현된 B-스플라인 FLOP는 다음과 같습니다. 🎜🎜🎜🎜🎜 지름길 경로의 FLOP와 두 분기를 병합하는 FLOP를 합하면 KAN 레이어의 전체 FLOP가 됩니다. 🎜🎜🎜🎜🎜 이에 따라 MLP 레이어의 FLOP는 다음과 같습니다. 🎜🎜🎜🎜🎜입력 차원과 출력 차원이 동일한 KAN 레이어와 MLP 레이어 간의 FLOP 차이는 다음과 같이 표현될 수 있습니다. 🎜🎜🎜🎜 🎜MLP가 비선형 연산도 먼저 수행하는 경우 최고항은 0이 됩니다. 🎜🎜🎜🎜🎜🎜 실험 🎜🎜🎜🎜🎜🎜저자의 목표는 매개변수 개수 또는 FLOP 개수가 동일할 때 KAN과 MLP의 성능 차이를 비교하는 것입니다. 실험은 기계 학습, 컴퓨터 비전, 자연어 처리, 오디오 처리 및 기호 수식 표현을 포함한 여러 영역을 다룹니다. 모든 실험은 Adam 최적화 프로그램을 사용했으며 모두 RTX3090 GPU에서 수행되었습니다. 🎜🎜🎜🎜🎜🎜성능 비교🎜🎜🎜🎜🎜🎜기계 학습. 저자들은 1개 또는 2개의 히든 레이어가 있는 KAN과 MLP를 사용하여 8개의 머신러닝 데이터세트에 대한 실험을 수행했으며, 각 데이터세트의 특성에 따라 신경망의 입력 및 출력 차원을 조정했습니다. 🎜🎜🎜🎜🎜MLP의 경우 숨겨진 레이어 너비가 32, 64, 128, 256, 512 또는 1024로 설정되고 활성화 함수로 GELU 또는 ReLU가 사용되는 반면 MLP에서는 정규화 레이어가 사용됩니다. KAN의 경우 숨겨진 레이어 너비는 2, 4, 8 또는 16이고 B-스플라인 메시 수는 3, 5, 10 또는 20이며 B-스플라인 각도는 2, 3 또는 5입니다.원래 KAN 아키텍처에는 정규화 계층이 포함되어 있지 않기 때문에 MLP에서 정규화 계층의 가능한 이점의 균형을 맞추기 위해 저자는 KAN 스플라인 함수의 값 범위를 확장했습니다. 모든 실험은 20회 훈련 동안 수행되었으며 그림 2와 3에 표시된 것처럼 훈련 과정 동안 테스트 세트에서 달성된 최고의 정확도가 기록되었습니다. 기계 학습 데이터 세트에서는 MLP가 일반적으로 이점을 유지합니다. 8개 데이터 세트에 대한 실험에서 MLP는 그 중 6개 데이터 세트에서 KAN보다 성능이 뛰어났습니다. 그러나 그들은 또한 한 데이터 세트에서는 MLP와 KAN의 성능이 거의 동일했지만 다른 데이터 세트에서는 KAN이 MLP보다 더 나은 성능을 발휘한다는 것을 관찰했습니다. 전반적으로 MLP는 여전히 기계 학습 데이터 세트에 대한 일반적인 이점을 가지고 있습니다. 컴퓨터 비전. 저자는 8개의 컴퓨터 비전 데이터세트에 대해 실험을 수행했습니다. 그들은 하나 또는 두 개의 숨겨진 레이어가 있는 KAN과 MLP를 사용하여 데이터 세트에 따라 신경망의 입력 및 출력 차원을 조정했습니다. 컴퓨터 비전 데이터 세트에서 KAN 의 스플라인 함수에 의해 도입된 처리 편향은 효과가 없으며 성능은 항상 동일한 수의 매개변수 또는 FLOP를 사용하는 MLP보다 열등합니다. 오디오 및 자연어 처리. 저자는 2개의 오디오 분류 데이터셋과 2개의 텍스트 분류 데이터셋에 대해 실험을 수행했습니다. 그들은 은닉층이 1~2개 있는 KAN과 MLP를 사용했고, 데이터 세트의 특성에 따라 신경망의 입력과 출력 차원을 조정했습니다. 두 오디오 데이터 세트 모두에서 MLP가 KAN보다 성능이 뛰어납니다. 텍스트 분류 작업에서 MLP는 AG News 데이터 세트에 대한 이점을 유지합니다. 그러나 CoLA 데이터세트에서는 MLP와 KAN의 성능에 큰 차이가 없습니다. KAN은 제어 매개변수의 수가 동일할 때 CoLA 데이터세트에 유리한 것으로 보입니다. 그러나 KAN의 스플라인에는 더 높은 FLOP가 필요하므로 이 이점은 제어된 FLOP를 사용한 실험에서 일관되게 나타나지 않습니다. FLOP를 제어할 때 MLP가 더 우수한 것으로 보입니다. 따라서 CoLA 데이터세트에서 어떤 모델이 더 나은지에 대한 명확한 대답은 없습니다. 전반적으로 MLP가 오디오 및 텍스트 작업 모두에서 여전히 더 나은 선택입니다. 기호 수식 표현. 저자는 8가지 기호 수식 표현 작업에서 KAN과 MLP의 차이점을 비교했습니다. 그들은 1~4개의 숨겨진 레이어가 있는 KAN과 MLP를 사용하여 데이터 세트에 따라 신경망의 입력 및 출력 차원을 조정했습니다. KAN은 매개변수 수를 제어하면서 8개 데이터 세트 중 7개에서 MLP보다 성능이 뛰어납니다. FLOP를 제어할 때 KAN은 대략 MLP와 동등한 성능을 발휘하여 두 데이터 세트에서 MLP보다 성능이 뛰어나고 스플라인으로 인해 발생하는 추가 계산 복잡성으로 인해 다른 데이터 세트에서는 MLP보다 열등합니다. 전반적으로 KAN은 기호식 표현 작업에서 MLP보다 성능이 뛰어납니다. The above is the detailed content of Reversed? In a new contest, KAN, which claims to replace MLP, only won one game. For more information, please follow other related articles on the PHP Chinese website!









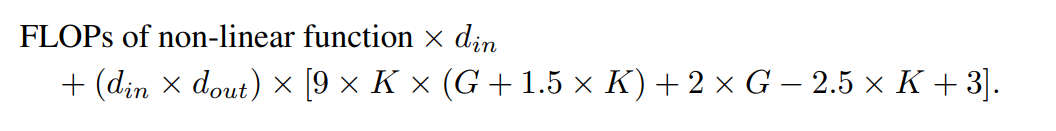










 What is the difference between legacy and uefi?
What is the difference between legacy and uefi?
 flex tutorial
flex tutorial
 Introduction to hard disk performance indicators
Introduction to hard disk performance indicators
 SpringBoot project building steps
SpringBoot project building steps
 Where are the number of online viewers at station b?
Where are the number of online viewers at station b?
 html web page production
html web page production
 What are the java text editors
What are the java text editors
 What should I do if msconfig cannot be opened?
What should I do if msconfig cannot be opened?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



