
 Backend Development
Golang
We Chose Meilisearch Over Other Search Engines Despite a Major Drawback
Backend Development
Golang
We Chose Meilisearch Over Other Search Engines Despite a Major Drawback
We Chose Meilisearch Over Other Search Engines Despite a Major Drawback

Is it worth investing resources in a third-party search engine? Here are our reasons.
We are continuously working on improving our product Feedback by Hexmos day by day for the upcoming release.
New features and pages are coming up, the UI is changing, bugs are being noticed and fixed, and many changes are happening in the product. As the product grows, we realize we need to improve the navigation across the product.
We already have a sidebar and a client-side search package cmdk to navigate to different screens, but difficulties arise when we want to search for different user profiles, teams, team performance, etc., which forces us to integrate a better third party search engine for Feedback.
Another reason for a dedicated search engine is that we have other products in the chain such as FeedZap, which requires a complex text search operations in future.
Considering this, we are planning to put effort into implementing a dedicated, powerful search engine that adapts to our use cases and resource availability.
How to Choose the Right Search Engine that fit your Needs
There are a lot of search engines available, including open-source search engines, serverless, server-based, etc.
Before diving in to figure out the right one, it's always better to do an analysis of your requirements and infrastructure, including present and future needs.
For some products, searchable data are minimal but require a decent search feature with minimal operation, yet can't afford a dedicated server.
For other products, the dataset is larger, requires additional complex search operations and have enough resources to load a dedicated search engine.
Based on this, I reviewed a few popular search engines.
Need Decent Performance, Dataset Is Small, and Can't Afford a Server
PostgreSQL Full-Text Search
If you are using PostgreSQL and don't want to maintain any other index-based database, then PostgreSQL Full-Text Search (PSFTS) is a good option. However, it is not recommended for large use cases where you deal with millions of transactions and extensive data management.
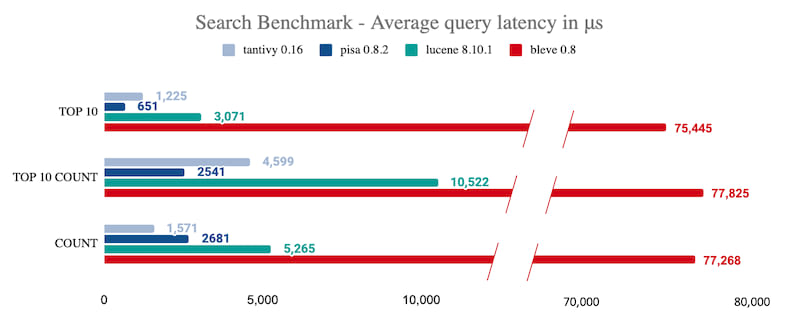
Bleve
Bleve is another option to consider if your project is within the Go ecosystem. It is recommended if you can't rely on powerful server-based search engine services. Here is the benchmark report on Bleve.
Tantivy
Tantivy is written in Rust and is particularly useful for Rust-based projects. It has received numerous positive feedbacks and is a good option to consider.
Need Powerful Performance, Large Dataset, and Can Afford a Server
Need Powerful Performance, Large Dataset, and Can Afford a Server
If you own a server or cloud instance and require a powerful, scalable search engine with full control, then a server-based option is the way to go.
Our considerations and requirements led us to choose a server-based search engine. We have enough resources to host it, and it is better than serverless options for
- Long-term use
- Scalability
- Additional support for complex search operations such as:
- Facet search: it means when shopping online, you might search for "laptops" and then use facet search to narrow down results by selecting filters like "price under $1000," "brand: Apple," and "RAM: 16GB."
- Multisearch: Consider travel website which might let users search for flights, hotels, and car rentals all at once and display back the integrated results.
- Search-as-you-type: It provides real-time search results based on each key stroke.
- Common search system for mulitiple products.
After extensive filtering, we narrowed it down to four options in this category such as:
- Meilisearch
- Typesense
- PISA Search
- Manticore
Here is a comparison between them:
| Criteria | meiliSearch | Typesense | Pisa Search | Manticore |
|---|---|---|---|---|
| Search-as-you-type | yes | yes | No | No |
| facet search | yes | yes | No | No |
| multiple schema/product support | yes | yes | - | yes |
| RAM usage | for 224 MB disk:~305 MB RAM prmary index location is disk | primary index location is RAM, for 100MB disk requires 300MB RAM | - | - |
| CPU Usage | for 12 core machine it uses maximum 6 core github issues related to high cpu usage | for 4vCPU handle 104 concurrent search/seconds | - | - |
| typo, synonyms handling | yes | yes | - | - |
We filtered out PISA Search and Manticore because neither of them offers search-as-you-type and facet search features, which are required for our application.
Continue reading the full article here: https://journal.hexmos.com/we-chose-meilisearch-over-10-other-search-engines-despite-a-major-drawback/
The above is the detailed content of We Chose Meilisearch Over Other Search Engines Despite a Major Drawback. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1663
1663
 14
1419
52
1313
25
1264
29
1237
24
14
1419
52
1313
25
1264
29
1237
24

 Golang's Purpose: Building Efficient and Scalable Systems
Apr 09, 2025 pm 05:17 PM
Golang's Purpose: Building Efficient and Scalable Systems
Apr 09, 2025 pm 05:17 PM
Go language performs well in building efficient and scalable systems. Its advantages include: 1. High performance: compiled into machine code, fast running speed; 2. Concurrent programming: simplify multitasking through goroutines and channels; 3. Simplicity: concise syntax, reducing learning and maintenance costs; 4. Cross-platform: supports cross-platform compilation, easy deployment.
 Golang and C : Concurrency vs. Raw Speed
Apr 21, 2025 am 12:16 AM
Golang and C : Concurrency vs. Raw Speed
Apr 21, 2025 am 12:16 AM
Golang is better than C in concurrency, while C is better than Golang in raw speed. 1) Golang achieves efficient concurrency through goroutine and channel, which is suitable for handling a large number of concurrent tasks. 2)C Through compiler optimization and standard library, it provides high performance close to hardware, suitable for applications that require extreme optimization.
 Golang's Impact: Speed, Efficiency, and Simplicity
Apr 14, 2025 am 12:11 AM
Golang's Impact: Speed, Efficiency, and Simplicity
Apr 14, 2025 am 12:11 AM
Goimpactsdevelopmentpositivelythroughspeed,efficiency,andsimplicity.1)Speed:Gocompilesquicklyandrunsefficiently,idealforlargeprojects.2)Efficiency:Itscomprehensivestandardlibraryreducesexternaldependencies,enhancingdevelopmentefficiency.3)Simplicity:
 Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang is better than Python in terms of performance and scalability. 1) Golang's compilation-type characteristics and efficient concurrency model make it perform well in high concurrency scenarios. 2) Python, as an interpreted language, executes slowly, but can optimize performance through tools such as Cython.
 Golang vs. Python: Key Differences and Similarities
Apr 17, 2025 am 12:15 AM
Golang vs. Python: Key Differences and Similarities
Apr 17, 2025 am 12:15 AM
Golang and Python each have their own advantages: Golang is suitable for high performance and concurrent programming, while Python is suitable for data science and web development. Golang is known for its concurrency model and efficient performance, while Python is known for its concise syntax and rich library ecosystem.
 Golang and C : The Trade-offs in Performance
Apr 17, 2025 am 12:18 AM
Golang and C : The Trade-offs in Performance
Apr 17, 2025 am 12:18 AM
The performance differences between Golang and C are mainly reflected in memory management, compilation optimization and runtime efficiency. 1) Golang's garbage collection mechanism is convenient but may affect performance, 2) C's manual memory management and compiler optimization are more efficient in recursive computing.
 The Performance Race: Golang vs. C
Apr 16, 2025 am 12:07 AM
The Performance Race: Golang vs. C
Apr 16, 2025 am 12:07 AM
Golang and C each have their own advantages in performance competitions: 1) Golang is suitable for high concurrency and rapid development, and 2) C provides higher performance and fine-grained control. The selection should be based on project requirements and team technology stack.
 C and Golang: When Performance is Crucial
Apr 13, 2025 am 12:11 AM
C and Golang: When Performance is Crucial
Apr 13, 2025 am 12:11 AM
C is more suitable for scenarios where direct control of hardware resources and high performance optimization is required, while Golang is more suitable for scenarios where rapid development and high concurrency processing are required. 1.C's advantage lies in its close to hardware characteristics and high optimization capabilities, which are suitable for high-performance needs such as game development. 2.Golang's advantage lies in its concise syntax and natural concurrency support, which is suitable for high concurrency service development.
