
 Technology peripherals
It Industry
Reddit CEO: Microsoft and other companies must pay to scrape data
Technology peripherals
It Industry
Reddit CEO: Microsoft and other companies must pay to scrape data
Reddit CEO: Microsoft and other companies must pay to scrape data

According to news from this website on August 1, Reddit CEO Steve Hoffman recently stated that if companies such as Microsoft want to continue to crawl the website’s data, they must pay. Reddit has previously reached agreements with Google and OpenAI.

Image via Pexels
Hoffman noted that without these agreements, Reddit has no control or visibility into how its data is used, forcing them to block companies that are unwilling to accept the terms on which their data is used. He singled out three companies, Microsoft, Anthropic and Perplexity, for refusing to negotiate and called blocking them "very troublesome."
In recent months, Reddit has been increasing its efforts to crack down on scrapers. In early July, Reddit updated its robots.txt file to block unauthorized web crawlers. It was later discovered that Reddit content only appeared in Google search results and was not visible on other search engines such as Bing.
Hoffman accused Microsoft of using Reddit data to train AI without authorization, summarizing Reddit content in Bing search results, and even selling this data to other search engines through the Bing API. He also responded to Microsoft AI chief Mustafa Suleiman’s previous remarks about Internet public data being “free software,” saying that companies such as Microsoft believe that all content on the Internet is free for them to use and that this is theirs. True position.
This site noticed that in response to the disappearance of Reddit search results from Bing, Microsoft search director Jody Ribas said on social media that Reddit blocked Bing’s crawlers and favored another search engine, affecting Bing and Bing-based Search engine competition. Microsoft spokesperson Caitlin Lawton also said the company respects websites’ wishes not to have their content used in generative AI models.
Hoffman used OpenAI’s SearchGPT as an example to emphasize the importance of paid agreements. Earlier this year, Reddit and OpenAI reached an agreement to allow SearchGPT to display Reddit content. Reddit spokesman Tim Rutschmidt said that none of the current content licensing agreements involve exclusive data use rights.
Reddit’s request for payment is similar to traditional media publishers who also hope to gain revenue from allowing content to be used for generative AI. Hoffman believes that the traditional value exchange of search engines has changed. Search, summary and training are integrating, and the model of simply relying on crawling content in exchange for traffic has become blurred.
The above is the detailed content of Reddit CEO: Microsoft and other companies must pay to scrape data. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Users encounter rare glitches: Samsung Watch smartwatches suddenly experience white screen issues
Apr 03, 2024 am 08:13 AM
Users encounter rare glitches: Samsung Watch smartwatches suddenly experience white screen issues
Apr 03, 2024 am 08:13 AM
You may have encountered the problem of green lines appearing on the screen of your smartphone. Even if you have never seen it, you must have seen related pictures on the Internet. So, have you ever encountered a situation where the smart watch screen turns white? On April 2, CNMO learned from foreign media that a Reddit user shared a picture on the social platform, showing the screen of the Samsung Watch series smart watches turning white. The user wrote: "I was charging when I left, and when I came back, it was like this. I tried to restart, but the screen was still like this during the restart process." Samsung Watch smart watch screen turned white. The Reddit user did not specify the smart watch. Specific model. However, judging from the picture, it should be Samsung Watch5. Previously, another Reddit user also reported
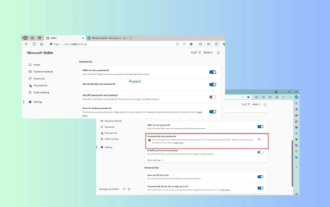 Microsoft Edge upgrade: Automatic password saving function banned? ! Users were shocked!
Apr 19, 2024 am 08:13 AM
Microsoft Edge upgrade: Automatic password saving function banned? ! Users were shocked!
Apr 19, 2024 am 08:13 AM
News on April 18th: Recently, some users of the Microsoft Edge browser using the Canary channel reported that after upgrading to the latest version, they found that the option to automatically save passwords was disabled. After investigation, it was found that this was a minor adjustment after the browser upgrade, rather than a cancellation of functionality. Before using the Edge browser to access a website, users reported that the browser would pop up a window asking if they wanted to save the login password for the website. After choosing to save, Edge will automatically fill in the saved account number and password the next time you log in, providing users with great convenience. But the latest update resembles a tweak, changing the default settings. Users need to choose to save the password and then manually turn on automatic filling of the saved account and password in the settings.
 Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
According to news from this site on August 14, during today’s August Patch Tuesday event day, Microsoft released cumulative updates for Windows 11 systems, including the KB5041585 update for 22H2 and 23H2, and the KB5041592 update for 21H2. After the above-mentioned equipment is installed with the August cumulative update, the version number changes attached to this site are as follows: After the installation of the 21H2 equipment, the version number increased to Build22000.314722H2. After the installation of the equipment, the version number increased to Build22621.403723H2. After the installation of the equipment, the version number increased to Build22631.4037. The main contents of the KB5041585 update for Windows 1121H2 are as follows: Improvement: Improved
 Microsoft Win11's function of compressing 7z and TAR files has been downgraded from 24H2 to 23H2/22H2 versions
Apr 28, 2024 am 09:19 AM
Microsoft Win11's function of compressing 7z and TAR files has been downgraded from 24H2 to 23H2/22H2 versions
Apr 28, 2024 am 09:19 AM
According to news from this site on April 27, Microsoft released the Windows 11 Build 26100 preview version update to the Canary and Dev channels earlier this month, which is expected to become a candidate RTM version of the Windows 1124H2 update. The main changes in the new version are the file explorer, Copilot integration, editing PNG file metadata, creating TAR and 7z compressed files, etc. @PhantomOfEarth discovered that Microsoft has devolved some functions of the 24H2 version (Germanium) to the 23H2/22H2 (Nickel) version, such as creating TAR and 7z compressed files. As shown in the diagram, Windows 11 will support native creation of TAR
 Microsoft Edge browser update: Added "zoom in image" function to improve user experience
Mar 21, 2024 pm 01:40 PM
Microsoft Edge browser update: Added "zoom in image" function to improve user experience
Mar 21, 2024 pm 01:40 PM
According to news on March 21, Microsoft recently updated its Microsoft Edge browser and added a practical "enlarge image" function. Now, when using the Edge browser, users can easily find this new feature in the pop-up menu by simply right-clicking on the image. What’s more convenient is that users can also hover the cursor over the image and then double-click the Ctrl key to quickly invoke the function of zooming in on the image. According to the editor's understanding, the newly released Microsoft Edge browser has been tested for new features in the Canary channel. The stable version of the browser has also officially launched the practical "enlarge image" function, providing users with a more convenient image browsing experience. Foreign science and technology media also paid attention to this
 Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
According to news on June 3, Microsoft is actively sending full-screen notifications to all Windows 10 users to encourage them to upgrade to the Windows 11 operating system. This move involves devices whose hardware configurations do not support the new system. Since 2015, Windows 10 has occupied nearly 70% of the market share, firmly establishing its dominance as the Windows operating system. However, the market share far exceeds the 82% market share, and the market share far exceeds that of Windows 11, which will be released in 2021. Although Windows 11 has been launched for nearly three years, its market penetration is still slow. Microsoft has announced that it will terminate technical support for Windows 10 after October 14, 2025 in order to focus more on
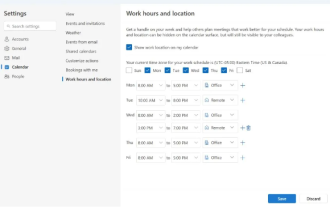 Microsoft launches new version of Outlook for Windows: comprehensive upgrade of calendar functions
Apr 27, 2024 pm 03:44 PM
Microsoft launches new version of Outlook for Windows: comprehensive upgrade of calendar functions
Apr 27, 2024 pm 03:44 PM
In news on April 27, Microsoft announced that it will soon release a test of a new version of Outlook for Windows client. This update mainly focuses on optimizing the calendar function, aiming to improve users’ work efficiency and further simplify daily workflow. The improvement of the new version of Outlook for Windows client lies in its more powerful calendar management function. Now, users can more easily share personal working time and location information, making meeting planning more efficient. In addition, Outlook has also added user-friendly settings, allowing users to set meetings to automatically end early or start later, providing users with more flexibility, whether they want to change meeting rooms, take a break or enjoy a cup of coffee. arrange. according to
 Microsoft plans to phase out NTLM in Windows 11 in the second half of 2024 and fully shift to Kerberos authentication
Jun 09, 2024 pm 04:17 PM
Microsoft plans to phase out NTLM in Windows 11 in the second half of 2024 and fully shift to Kerberos authentication
Jun 09, 2024 pm 04:17 PM
In the second half of 2024, the official Microsoft Security Blog published a message in response to the call from the security community. The company plans to eliminate the NTLAN Manager (NTLM) authentication protocol in Windows 11, released in the second half of 2024, to improve security. According to previous explanations, Microsoft has already made similar moves before. On October 12 last year, Microsoft proposed a transition plan in an official press release aimed at phasing out NTLM authentication methods and pushing more enterprises and users to switch to Kerberos. To help enterprises that may be experiencing issues with hardwired applications and services after turning off NTLM authentication, Microsoft provides IAKerb and
