
 Technology peripherals
AI
The ultimate question of explainability is, what is the first explanation? 20 CCF-A+ICLR papers give you answers
Technology peripherals
AI
The ultimate question of explainability is, what is the first explanation? 20 CCF-A+ICLR papers give you answers
The ultimate question of explainability is, what is the first explanation? 20 CCF-A+ICLR papers give you answers


Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
2. Trouver les causes profondes prouvables et vérifiables derrière les indicateurs de performance : combiner la généralisation et la robustesse du réseau neuronal La cause profonde des indicateurs de performance ultimes. telles que les performances sont décomposées en quelques logiques détaillées
- Voir 2 : https://zhuanlan.zhihu.com/p/361686461
- Voir 3 : https://zhuanlan.zhihu.com/p/704760363
- Voir 4 : https://zhuanlan.zhihu.com/p/468569001
3. Algorithme d'apprentissage en profondeur d'ingénierie unifié
1を参照: https://zhuanlan.zhihu.com/p/610774894 2を参照: https://zhuanlan.zhihu.com/p/546433296
1.Junpeng Zhang、Qing Li、Liang Lin、Quanshi Zhang、「相互作用の 2 相ダイナミクスが過適合特徴を学習する DNN の開始点を説明する」、arXiv: 2405.10262 2.Qihan Ren、Yang Xu、Junpeng Zhang、Yue Xin、Dongrui Liu、Quanshi Zhang、「シンボリック インタラクションを学習する DNN のダイナミクスに向けて」、arXiv:2407.19198

représenter une sortie scalaire du DNN sur l'échantillon
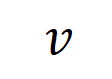
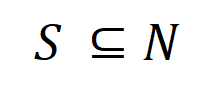 codées par le réseau neuronal. Par exemple, étant donné une phrase d’entrée
codées par le réseau neuronal. Par exemple, étant donné une phrase d’entrée 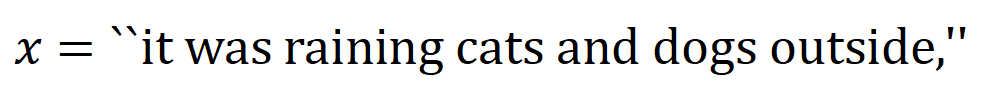 , un réseau de neurones pourrait modéliser une interaction entre
, un réseau de neurones pourrait modéliser une interaction entre 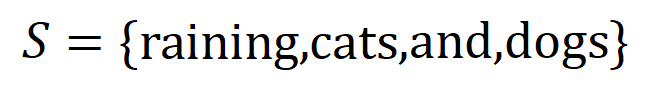 telle que
telle que 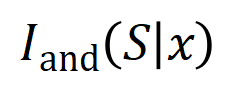 produit un utilitaire numérique qui pilote la « pluie » de sortie du réseau de neurones. Si une variable d'entrée dans
produit un utilitaire numérique qui pilote la « pluie » de sortie du réseau de neurones. Si une variable d'entrée dans 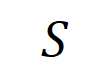 est occultée, cet utilitaire numérique sera supprimé de la sortie du réseau neuronal. De même, l'équivalence ou l'interaction
est occultée, cet utilitaire numérique sera supprimé de la sortie du réseau neuronal. De même, l'équivalence ou l'interaction 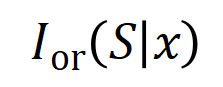 représente la « relation OU » entre les variables d'entrée au sein de
représente la « relation OU » entre les variables d'entrée au sein de  modélisée par le réseau neuronal. Par exemple, étant donné une phrase d'entrée
modélisée par le réseau neuronal. Par exemple, étant donné une phrase d'entrée 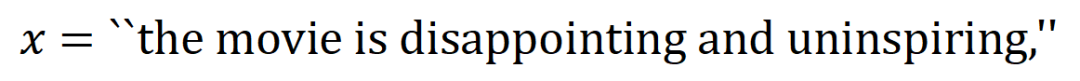 , tant qu'un mot dans
, tant qu'un mot dans 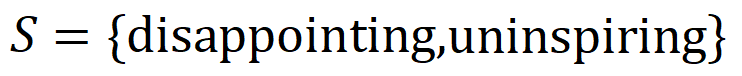 apparaît, cela pilotera la sortie du réseau neuronal pour classer les émotions négatives.
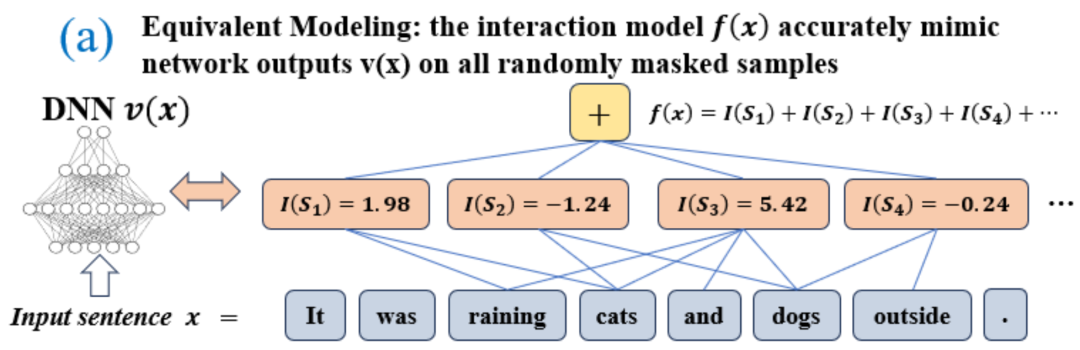
apparaît, cela pilotera la sortie du réseau neuronal pour classer les émotions négatives. Ajustement infini : Comme le montrent les figures 4 et 5, pour tout échantillon d'occlusion, la sortie du réseau neuronal sur l'échantillon peut être ajustée par la somme des utilités de différents concepts d'interaction. Autrement dit, nous pouvons construire un modèle logique basé sur l'interaction. Quelle que soit la manière dont nous bloquons l'échantillon d'entrée, ce modèle logique peut toujours ajuster avec précision la valeur de sortie du modèle dans n'importe quel état bloqué de l'échantillon d'entrée. Sparsity : Les réseaux de neurones pour les tâches de classification ne modélisent souvent qu'un petit nombre de concepts interactifs significatifs, et la plupart des concepts interactifs sont du bruit avec une utilité numérique proche de 0. Transférabilité entre échantillons : Les interactions sont transférables entre différents échantillons, c'est-à-dire que les concepts d'interaction significatifs modélisés par des réseaux de neurones sur différents échantillons (de la même catégorie) se chevauchent souvent beaucoup.
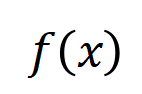 に基づくロジック モデルによって正確に適合できます。各相互作用は、特定の入力変数セット
に基づくロジック モデルによって正確に適合できます。各相互作用は、特定の入力変数セット 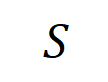 をモデル化するニューラル ネットワーク間の非線形関係の尺度です。セット内の変数が同時に出現する場合にのみ、トリガーおよび相互作用し、出力
をモデル化するニューラル ネットワーク間の非線形関係の尺度です。セット内の変数が同時に出現する場合にのみ、トリガーおよび相互作用し、出力 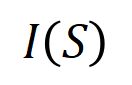 に数値スコアを提供します。セット
に数値スコアを提供します。セット  内の変数が出現すると、トリガーまたは相互作用します。
内の変数が出現すると、トリガーまたは相互作用します。 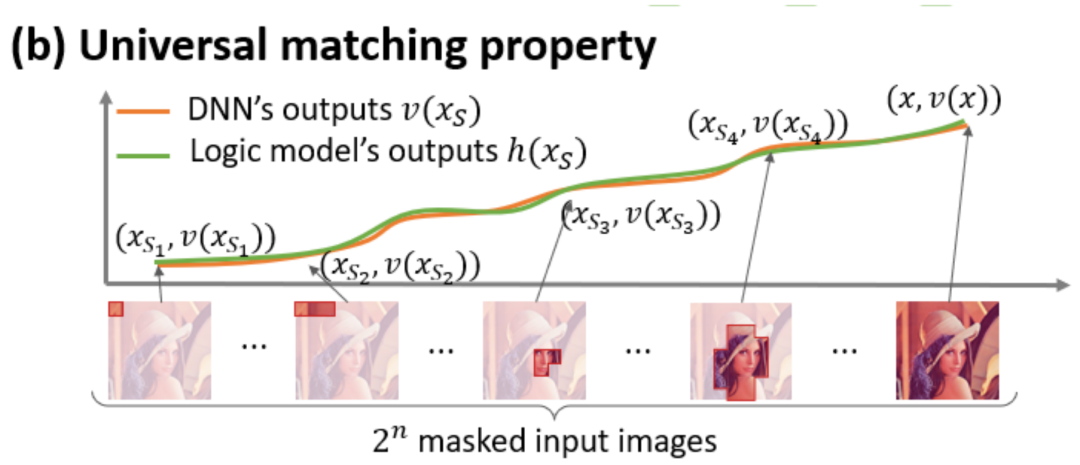
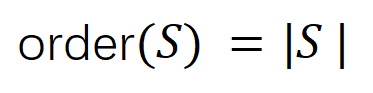
を使用して順序のすべての正の有意な相互作用の強度を測定し、
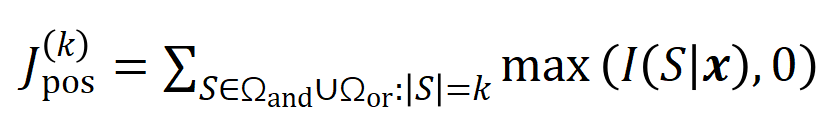 と
と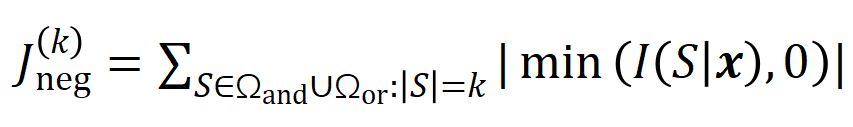 は有意な相互作用のセットを表し、
は有意な相互作用のセットを表し、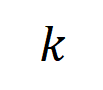 は有意な相互作用のしきい値を表します交流。
は有意な相互作用のしきい値を表します交流。 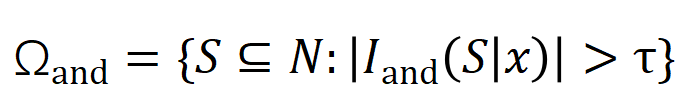
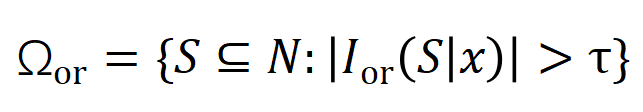

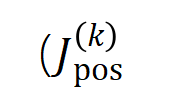 および
および 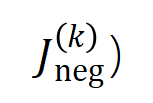 。異なるデータセットおよび異なるタスクでトレーニングされたさまざまなニューラル ネットワークのトレーニング プロセスには 2 段階の現象があります。最初の 2 つの選択された時点は第 1 フェーズに属し、最後の 2 つの時点は第 2 フェーズに属します。ニューラル ネットワークのトレーニング プロセスの第 2 段階に入った直後に、ニューラル ネットワークのテスト損失とトレーニング損失の間の損失ギャップが大幅に増加し始めます (最後のコラムを参照)。これは、ニューラル ネットワーク トレーニングの 2 段階の現象が、モデルの損失ギャップの変化に合わせて「調整」されていることを示しています。詳しい実験結果については論文をご覧ください。
。異なるデータセットおよび異なるタスクでトレーニングされたさまざまなニューラル ネットワークのトレーニング プロセスには 2 段階の現象があります。最初の 2 つの選択された時点は第 1 フェーズに属し、最後の 2 つの時点は第 2 フェーズに属します。ニューラル ネットワークのトレーニング プロセスの第 2 段階に入った直後に、ニューラル ネットワークのテスト損失とトレーニング損失の間の損失ギャップが大幅に増加し始めます (最後のコラムを参照)。これは、ニューラル ネットワーク トレーニングの 2 段階の現象が、モデルの損失ギャップの変化に合わせて「調整」されていることを示しています。詳しい実験結果については論文をご覧ください。 - ニューラル ネットワークのトレーニング
- の最初の段階では、ニューラル ネットワークによってエンコードされた高次および中次の相互作用の強度が徐々に弱まり、低次の相互作用の強度が徐々に増加します。最終的に、高次および中次の相互作用は徐々に排除され、ニューラル ネットワークは低次の相互作用のみをエンコードします。
上記の 2 段階の現象は、異なるタスク、異なるデータセットで異なる構造を持つニューラル ネットワークのトレーニング プロセスに広く存在します。 VGG-11/13/16 を画像データセット (CIFAR-10 データセット、MNIST データセット、CUB200-2011 データセット (写真から切り取った鳥の画像を使用) および Tiny-ImageNet データセット) と AlexNet でトレーニングしました。 SST-2 データセットで感情意味分類のために Bert-Medium/Tiny モデルをトレーニングし、3D 点群データを分類するために ShapeNet データセットで DGCNN をトレーニングしました。上の図は、異なるトレーニング エポックで異なるニューラル ネットワークによって抽出された、異なる次数の重要な相互作用の分布を示しています。私たちは、これらのニューラル ネットワークのトレーニング プロセス中に 2 段階の現象を発見しました。実験結果と詳細については、論文を参照してください。
5.2 ニューラルネットワークによってモデル化された相互作用の順序とその汎化能力の関係
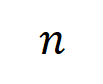 入力変数を含む入力サンプル
入力変数を含む入力サンプル  が与えられた場合、入力サンプル
が与えられた場合、入力サンプル  から抽出された
から抽出された  次の交互作用を
次の交互作用を 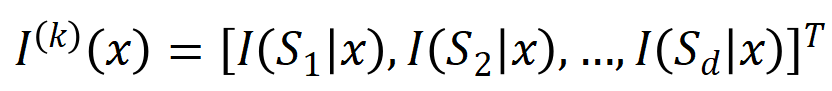 ベクトル化します。ここで、
ベクトル化します。ここで、 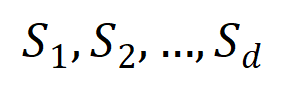 は
は 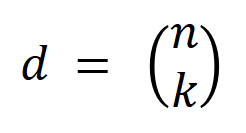
 次の相互作用を表します。次に、分類タスクでカテゴリ
次の相互作用を表します。次に、分類タスクでカテゴリ 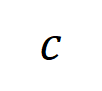 を持つすべてのサンプルから抽出された次数 の平均交互作用ベクトルを計算します。これは
を持つすべてのサンプルから抽出された次数 の平均交互作用ベクトルを計算します。これは 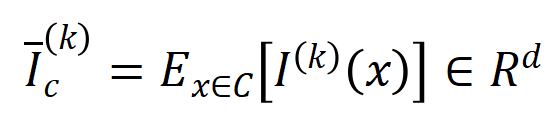 として表されます。ここで、
として表されます。ここで、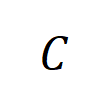 はカテゴリ
はカテゴリ  を持つサンプルのセットを表します。다음으로, 분류 작업에서 카테고리
を持つサンプルのセットを表します。다음으로, 분류 작업에서 카테고리 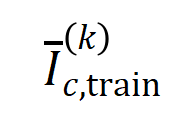 를 갖는 샘플의 를 측정하기 위해 훈련 샘플에서 추출된 순서
를 갖는 샘플의 를 측정하기 위해 훈련 샘플에서 추출된 순서 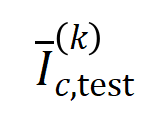 의 평균 상호 작용 벡터 와 테스트 샘플에서 추출된 순서 의 평균 상호 작용 벡터
의 평균 상호 작용 벡터 와 테스트 샘플에서 추출된 순서 의 평균 상호 작용 벡터 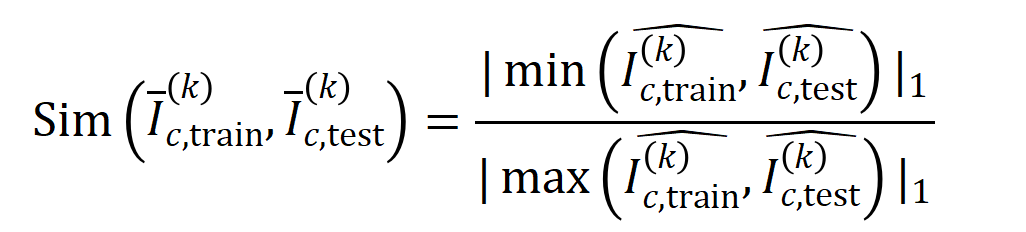
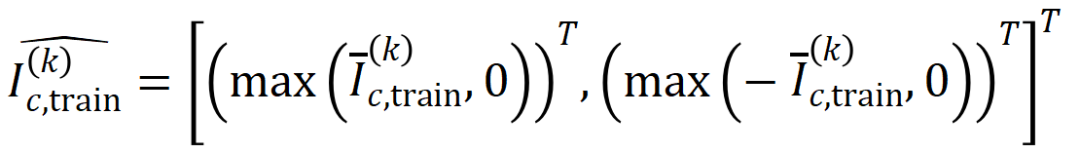 where,
where, 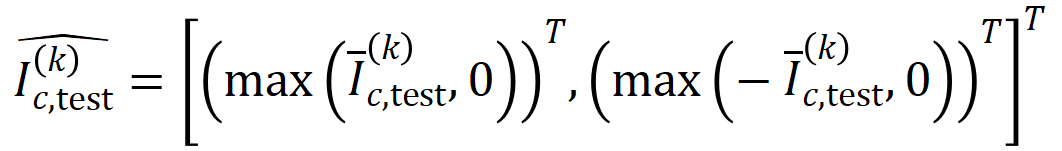 및
및 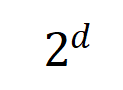 는 Jaccard 유사성을 계산하기 위해 두 개의
는 Jaccard 유사성을 계산하기 위해 두 개의 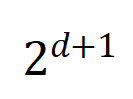 차원 상호 작용 벡터를 두 개의
차원 상호 작용 벡터를 두 개의 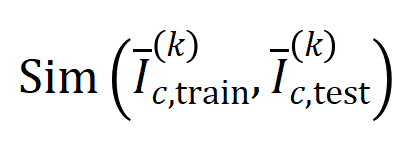 다양한 상호작용 순서를 계산하는 실험을 진행했습니다
다양한 상호작용 순서를 계산하는 실험을 진행했습니다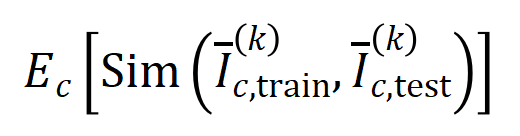 . 우리는 MNIST 데이터세트로 훈련된 LeNet, CIFAR-10 데이터세트로 훈련된 VGG-11, CUB200-2011 데이터세트로 훈련된 VGG-13, Tiny-ImageNet 데이터세트로 훈련된 AlexNet을 테스트했습니다. 계산 비용을 줄이기 위해 상위 10개 카테고리
. 우리는 MNIST 데이터세트로 훈련된 LeNet, CIFAR-10 데이터세트로 훈련된 VGG-11, CUB200-2011 데이터세트로 훈련된 VGG-13, Tiny-ImageNet 데이터세트로 훈련된 AlexNet을 테스트했습니다. 계산 비용을 줄이기 위해 상위 10개 카테고리
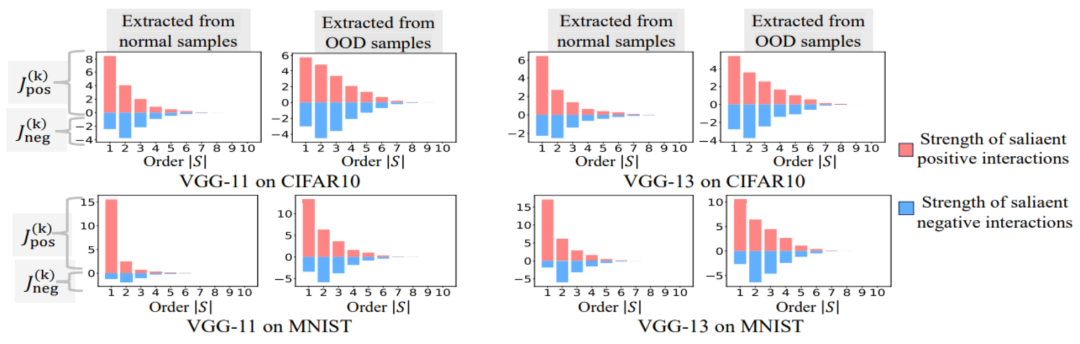
5.3 The two-stage phenomenon and the change in loss gap during the neural network training process are relatively consistent
We found that the above two-stage phenomenon can fully represent the generalization dynamics of the neural network. A very interesting phenomenon is that the two-stage phenomenon in the neural network training process and the changes in the loss gap of the neural network in the test set and training set are aligned in time
5.4 Theoretically prove the two-stage phenomenon
1. Prove the “spindle” interaction distribution for initialization neural network modeling.
and variance
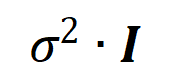
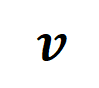 on a specific sample as a weighted sum of different interaction trigger functions:
on a specific sample as a weighted sum of different interaction trigger functions:  where
where  is a scalar weight, satisfying
is a scalar weight, satisfying  . The function
. The function  is an interactive trigger function, which satisfies
is an interactive trigger function, which satisfies  on any occlusion sample
on any occlusion sample  . The specific form of function
. The specific form of function  can be derived from Taylor expansion. Please refer to the paper and will not be described here.
can be derived from Taylor expansion. Please refer to the paper and will not be described here.
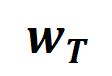 of the interactive trigger function. Furthermore, the laboratory's preliminary work [3] found that different neural networks fully trained on the same task tend to model similar interactions, so we can regard the learning of neural networks as a series of potential ground truth interactions. fitting. Therefore, the interaction modeled by the neural network when it is trained to convergence can be seen as the solution obtained when minimizing the following objective function:
of the interactive trigger function. Furthermore, the laboratory's preliminary work [3] found that different neural networks fully trained on the same task tend to model similar interactions, so we can regard the learning of neural networks as a series of potential ground truth interactions. fitting. Therefore, the interaction modeled by the neural network when it is trained to convergence can be seen as the solution obtained when minimizing the following objective function:  where
where  represents a series of potential ground truth interactions that the neural network needs to fit.
represents a series of potential ground truth interactions that the neural network needs to fit.  and
and 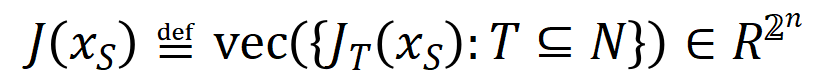 respectively represent the vector obtained by putting together all the weights and the vector obtained by putting together the values of all interaction trigger functions.
respectively represent the vector obtained by putting together all the weights and the vector obtained by putting together the values of all interaction trigger functions.
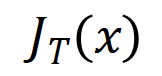
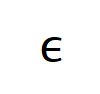 satisfies
satisfies 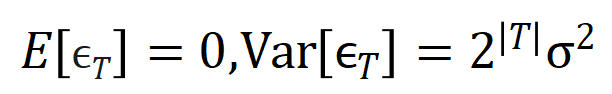 . And as the training proceeds, the variance of the noise
. And as the training proceeds, the variance of the noise 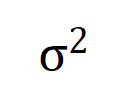 gradually becomes smaller.
gradually becomes smaller.  , the analytical solution of the optimal interaction weight
, the analytical solution of the optimal interaction weight  can be obtained, as shown in the theorem in the figure below.
can be obtained, as shown in the theorem in the figure below. 
becomes smaller), the ratio of low- and medium-order interaction strengths to high-order interaction strengths gradually decreases (as shown in the theorem below). This explains the phenomenon in which the neural network gradually learns higher-order interactions during the second phase of training. 
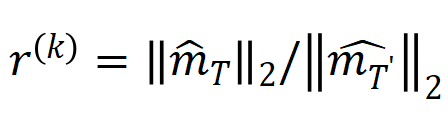 , where
, where 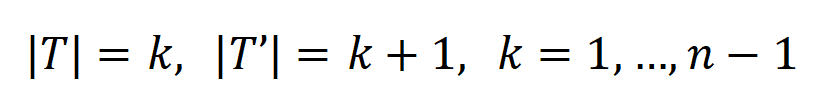 , can be used to approximately measure the ratio of the strength of the kth-order interaction to the k+1th-order interaction. In the figure below, we can find that under different number of input units n and different orders k, the ratio will gradually decrease as decreases.
, can be used to approximately measure the ratio of the strength of the kth-order interaction to the k+1th-order interaction. In the figure below, we can find that under different number of input units n and different orders k, the ratio will gradually decrease as decreases. 
diminuera progressivement . Cela montre qu'à mesure que l'entraînement progresse (c'est-à-dire que devient progressivement plus petit), le rapport entre l'intensité d'interaction d'ordre inférieur et l'intensité d'interaction d'ordre élevé devient progressivement plus petit et le réseau neuronal apprend progressivement les interactions d'ordre supérieur.  avec la distribution de chaque ordre d'interaction au cours du processus de formation réel
avec la distribution de chaque ordre d'interaction au cours du processus de formation réel 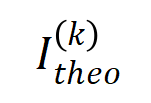 et avons constaté que le théorie La distribution des interactions peut bien prédire la distribution de l'intensité des interactions à chaque instant de l'entraînement réel.
et avons constaté que le théorie La distribution des interactions peut bien prédire la distribution de l'intensité des interactions à chaque instant de l'entraînement réel. 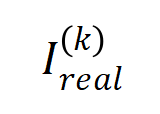

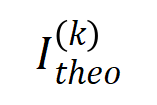 (파란색 히스토그램)과 실제 상호 작용 분포
(파란색 히스토그램)과 실제 상호 작용 분포 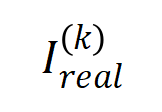 (주황색 히스토그램) 비교. 이론적 상호작용 분포는 훈련의 두 번째 단계에서 다양한 시점의 실제 상호작용 분포를 잘 예측하고 일치시킵니다. 더 많은 결과를 보려면 논문을 참조하세요.
(주황색 히스토그램) 비교. 이론적 상호작용 분포는 훈련의 두 번째 단계에서 다양한 시점의 실제 상호작용 분포를 잘 예측하고 일치시킵니다. 더 많은 결과를 보려면 논문을 참조하세요.  이 점차 감소할 때 가중치 의 최적 솔루션의 변화로 설명할 수 있다면 첫 번째 단계는 초기 무작위 상호작용은 점차적으로 최적의 솔루션으로 수렴됩니다.
이 점차 감소할 때 가중치 의 최적 솔루션의 변화로 설명할 수 있다면 첫 번째 단계는 초기 무작위 상호작용은 점차적으로 최적의 솔루션으로 수렴됩니다. 등가 상호 작용 이론 시스템
[1] Huiqi Deng, Na Zou, Mengnan Du, Weifu Chen, Guocan Feng, Ziwei Yang, Zheyang Li, Quanshi Zhang. Taylor 상호 작용을 통해 14가지 사후 기여 분석 방법 통합. 패턴 분석 및 기계 지능(IEEE T-PAMI)에 대한 IEEE 트랜잭션, 2024.
[2] Xu Cheng, Lei Cheng , Zhaoran Peng, Yang Xu, Tian Han 및 Quanshi Zhang. ICML, 2024.
[3] Qihan Ren, Jiayang Gao, Wen Shen 및 Quanshi Zhang. AI 모델에서 희소 상호 작용 프리미티브의 출현 증명, 2024.
[4] Lu Chen, Siyu Lou, Benhao Huang 및 Quanshi Zhang ICLR에서 일반화 가능한 상호 작용 프리미티브 정의 및 추출, 2024.
[5] Huilin Zhou, Hao Zhang, Huiqi Deng, Dongrui Liu, Wen Shen, Shih-Han Chan 및 Quanshi Zhang. 대화형 개념을 사용하여 DNN의 일반화 기능 설명, 2024.
[ 6 ] Dongrui Liu, Huiqi Deng, Xu Cheng, Qihan Ren, Kangrui Wang 및 Quanshi Zhang. 다양한 복잡성의 개념을 학습하기 위한 심층 신경망의 어려움, 2023.
[7] Quanshi Zhang, Jie Ren, Ge Huang, Ruiming Cao, Ying Nian Wu und Song-Chun Zhu. Gewinnung interpretierbarer AOG-Darstellungen aus Faltungsnetzwerken über aktive Fragebeantwortung (IEEE T -PAMI), 2020.
[8] Xin Wang, Jie Ren, Shuyun Lin, Xiangming Zhu, Yisen Wang und Quanshi Zhang. Ein einheitlicher Ansatz zur Interpretation und Steigerung der kontradiktorischen Übertragbarkeit [9] Hao Zhang, Sen Li, Yinchao Ma, Mingjie Li, Yichen Xie und Quanshi Zhang . Kodiert ein neuronales Netzwerk wirklich ein symbolisches Konzept? . ICML, 2023.
[12] Qihan Ren, Huiqi Deng, Yunuo Chen, Siyu Lou und Quanshi Zhang. Vermeiden Sie die Kodierung störungsempfindlicher und komplexer Konzepte ] Jie Ren, Mingjie Li, Qirui Chen, Huiqi Deng und Quanshi Zhang: Definition und Quantifizierung der Entstehung spärlicher Konzepte in DNNs, 2023.
[14] Jie Ren, Mingjie Li, Meng Zhou, Shih- Han Chan und Quanshi Zhang. Auf dem Weg zur theoretischen Analyse der Transformationskomplexität von ReLU-DNNs, 2022.
[15] Jie Ren, Die Zhang, Yisen Wang, Lu Chen, Zhanpeng Zhou, Yiting Chen, Xu Cheng, Xin Wang, Meng Zhou, Jie Shi und Quanshi Zhang. Eine einheitliche spieltheoretische Interpretation der gegnerischen Robustheit DNNs für die 3D-Punktwolkenverarbeitung.
[17] Xin Wang, Shuyun Lin, Hao Zhang, Yufei Zhu und Quanshi Zhang. ] Wen Shen, Zhihua Wei, Shikun Huang, Binbin Zhang, Panyue Chen, Ping Zhao und Quanshi Zhang: Interpreting Utilities of Network Architectures for 3D Point Cloud Processing, 2021.
[19] Hao Zhang, Yichen Xie , Longjie Zheng, Die Zhang und Quanshi Zhang. Interpreting Multivariate Shapley Interactions in DNNs, 2021. Mengyue Wu und Quanshi Zhang. Aufbau interpretierbarer Interaktionsbäume für Deep NLP-Modelle, 2021.
The above is the detailed content of The ultimate question of explainability is, what is the first explanation? 20 CCF-A+ICLR papers give you answers. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
In modern manufacturing, accurate defect detection is not only the key to ensuring product quality, but also the core of improving production efficiency. However, existing defect detection datasets often lack the accuracy and semantic richness required for practical applications, resulting in models unable to identify specific defect categories or locations. In order to solve this problem, a top research team composed of Hong Kong University of Science and Technology Guangzhou and Simou Technology innovatively developed the "DefectSpectrum" data set, which provides detailed and semantically rich large-scale annotation of industrial defects. As shown in Table 1, compared with other industrial data sets, the "DefectSpectrum" data set provides the most defect annotations (5438 defect samples) and the most detailed defect classification (125 defect categories
 Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Editor |KX To this day, the structural detail and precision determined by crystallography, from simple metals to large membrane proteins, are unmatched by any other method. However, the biggest challenge, the so-called phase problem, remains retrieving phase information from experimentally determined amplitudes. Researchers at the University of Copenhagen in Denmark have developed a deep learning method called PhAI to solve crystal phase problems. A deep learning neural network trained using millions of artificial crystal structures and their corresponding synthetic diffraction data can generate accurate electron density maps. The study shows that this deep learning-based ab initio structural solution method can solve the phase problem at a resolution of only 2 Angstroms, which is equivalent to only 10% to 20% of the data available at atomic resolution, while traditional ab initio Calculation
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
For AI, Mathematical Olympiad is no longer a problem. On Thursday, Google DeepMind's artificial intelligence completed a feat: using AI to solve the real question of this year's International Mathematical Olympiad IMO, and it was just one step away from winning the gold medal. The IMO competition that just ended last week had six questions involving algebra, combinatorics, geometry and number theory. The hybrid AI system proposed by Google got four questions right and scored 28 points, reaching the silver medal level. Earlier this month, UCLA tenured professor Terence Tao had just promoted the AI Mathematical Olympiad (AIMO Progress Award) with a million-dollar prize. Unexpectedly, the level of AI problem solving had improved to this level before July. Do the questions simultaneously on IMO. The most difficult thing to do correctly is IMO, which has the longest history, the largest scale, and the most negative
 PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
In 2023, almost every field of AI is evolving at an unprecedented speed. At the same time, AI is constantly pushing the technological boundaries of key tracks such as embodied intelligence and autonomous driving. Under the multi-modal trend, will the situation of Transformer as the mainstream architecture of AI large models be shaken? Why has exploring large models based on MoE (Mixed of Experts) architecture become a new trend in the industry? Can Large Vision Models (LVM) become a new breakthrough in general vision? ...From the 2023 PRO member newsletter of this site released in the past six months, we have selected 10 special interpretations that provide in-depth analysis of technological trends and industrial changes in the above fields to help you achieve your goals in the new year. be prepared. This interpretation comes from Week50 2023
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
Editor | KX Retrosynthesis is a critical task in drug discovery and organic synthesis, and AI is increasingly used to speed up the process. Existing AI methods have unsatisfactory performance and limited diversity. In practice, chemical reactions often cause local molecular changes, with considerable overlap between reactants and products. Inspired by this, Hou Tingjun's team at Zhejiang University proposed to redefine single-step retrosynthetic prediction as a molecular string editing task, iteratively refining the target molecular string to generate precursor compounds. And an editing-based retrosynthetic model EditRetro is proposed, which can achieve high-quality and diverse predictions. Extensive experiments show that the model achieves excellent performance on the standard benchmark data set USPTO-50 K, with a top-1 accuracy of 60.8%.
 Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Editor | ScienceAI Based on limited clinical data, hundreds of medical algorithms have been approved. Scientists are debating who should test the tools and how best to do so. Devin Singh witnessed a pediatric patient in the emergency room suffer cardiac arrest while waiting for treatment for a long time, which prompted him to explore the application of AI to shorten wait times. Using triage data from SickKids emergency rooms, Singh and colleagues built a series of AI models that provide potential diagnoses and recommend tests. One study showed that these models can speed up doctor visits by 22.3%, speeding up the processing of results by nearly 3 hours per patient requiring a medical test. However, the success of artificial intelligence algorithms in research only verifies this
