

PRO | Why are large models based on MoE more worthy of attention?

In 2023, almost every field of AI is evolving at an unprecedented speed. At the same time, AI is constantly pushing the technological boundaries of key tracks such as embodied intelligence and autonomous driving. Under the multi-modal trend, will Transformer be shaken as the mainstream architecture for large AI models? Why has exploring large models based on MoE (Mixture of Experts) architecture become a new trend in the industry? Can Large Vision Model (LVM) become a new breakthrough in general vision? ...From the 2023 PRO member newsletter of this site released in the past six months, we have selected 10 special interpretations that provide in-depth analysis of technological trends and industrial changes in the above fields to help you achieve your goals in the new year. be prepared. This interpretation comes from the 2023 Week50 industry newsletter ?

Date: December 12
Event: Mistral AI open sourced the model Mixtral 8x7B based on the MoE (Mixture-of-Experts, expert mixture) architecture, and its performance reached the level of Llama 2 70B and GPT-3.5" event was held Extended interpretation.
First, let’s figure out what MoE is and its ins and outs
1. Concept:
MoE (Mixture of Experts) is a hybrid model composed of multiple sub-models (ie experts), each sub-model It is a local model that specializes in processing a subset of the input space. The core idea of MoE is to use a gating network to decide which model should be trained by each data, thereby mitigating the interference between different types of samples.
2. , Main components:
Mixed expert model technology (MoE) is a deep learning technology controlled by sparse gates composed of expert models and gated models. MoE realizes the distribution of tasks/training data among different expert models through the gated network, allowing everyone to Each model focuses on the tasks it is best at, thereby achieving the sparsity of the model.
① In the training of the gated network, each sample will be assigned to one or more experts;
② In the training of the expert network. , each expert will be trained to minimize the error of the samples assigned to it.
3. The "predecessor" of MoE:
The "predecessor" of MoE is Ensemble Learning. Ensemble learning is the process of training multiple models (base learners) to solve the same problem, and simply combining their predictions (such as voting or averaging). The main goal of ensemble learning is to improve prediction performance by reducing overfitting and improving generalization capabilities. Common ensemble learning methods include Bagging, Boosting and Stacking.
4. MoE historical source:
① The roots of MoE can be traced back to the 1991 paper "Adaptive Mixture of Local Experts". The idea is similar to ensemble approaches, in that it aims to provide a supervisory process for a system composed of different sub-networks, with each individual network or expert specializing in a different region of the input space. The weight of each expert is determined through a gated network. During the training process, both experts and gatekeepers are trained.
② Between 2010 and 2015, two different research areas contributed to the further development of MoE:
One is experts as components: In a traditional MoE setup, the entire system consists of a gated network and Multiple experts. MoEs as whole models have been explored in support vector machines, Gaussian processes, and other methods. The work "Learning Factored Representations in a Deep Mixture of Experts" explores the possibility of MoEs as components of deeper networks. This allows the model to be large and efficient at the same time.
The other is conditional computation: traditional networks process all input data through each layer. During this period, Yoshua Bengio investigated ways to dynamically activate or deactivate components based on input tokens.
③ As a result, people began to explore expert mixture models in the context of natural language processing. In the paper "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer", it was extended to a 137B LSTM by introducing sparsity, thereby achieving fast reasoning at high scale.
Why are MoE-based large models worthy of attention?
1. Generally speaking, the expansion of model scale will lead to a significant increase in training costs, and the limitation of computing resources has become a bottleneck for large-scale intensive model training. To solve this problem, a deep learning model architecture based on sparse MoE layers is proposed.
2. The Sparse Mixed Expert Model (MoE) is a special neural network architecture that can add learnable parameters to large language models (LLM) without increasing the cost of inference, while instruction tuning ) is a technique for training LLM to follow instructions.
3. The combination of MoE+ instruction fine-tuning technology can greatly improve the performance of language models. In July 2023, researchers from Google, UC Berkeley, MIT and other institutions published the paper "Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models", which proved that the hybrid expert model (MoE) and instruction tuning The combination can greatly improve the performance of large language models (LLM).
① Specifically, the researchers used sparse activation MoE in a set of instruction-fine-tuned sparse hybrid expert model FLAN-MOE, and replaced the feedforward component of the Transformer layer with the MoE layer to provide better model capacity and computing flexibility. performance; secondly, fine-tune FLAN-MOE based on the FLAN collective data set.
② Based on the above method, the researchers studied direct fine-tuning on a single downstream task without instruction tuning, in-context few-shot or zero-shot generalization on the downstream task after instruction tuning, and in the instruction tuning Then we further fine-tune a single downstream task and compare the performance differences of LLM under the three experimental settings.
③ Experimental results show that without the use of instruction tuning, MoE models often perform worse than dense models with comparable computational power. But when combined with directive tuning, things change. The instruction-tuned MoE model (Flan-MoE) outperforms the larger dense model on multiple tasks, even though the MoE model is only one-third as computationally expensive as the dense model. Compared to dense models. MoE models gain more significant performance gains from instruction tuning, so when computing efficiency and performance are considered, MoE will become a powerful tool for large language model training.
4. This time, the Mixtral 8x7B model released also uses a sparse mixed expert network.
① Mixtral 8x7B is a decoder-only model. The feedforward module selects from 8 different sets of parameters. In each layer of the network, for each token, the router network selects two of the eight groups (experts) to process the token and aggregate their outputs.
② Mixtral 8x7B model matches or outperforms Llama 2 70B and GPT3.5 on most benchmarks, with inference speeds 6x faster.
Important advantages of MoE: What is sparsity?
1. In traditional dense models, each input needs to be calculated in the complete model. In the sparse mixed expert model, only a few expert models are activated and used when processing input data, while most of the expert models are in an inactive state. This state is "sparse". And sparsity is an important aspect of the mixed expert model. Advantages are also the key to improving the efficiency of model training and inference processes

The above is the detailed content of PRO | Why are large models based on MoE more worthy of attention?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1243
24
14
1423
52
1317
25
1268
29
1243
24

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
In modern manufacturing, accurate defect detection is not only the key to ensuring product quality, but also the core of improving production efficiency. However, existing defect detection datasets often lack the accuracy and semantic richness required for practical applications, resulting in models unable to identify specific defect categories or locations. In order to solve this problem, a top research team composed of Hong Kong University of Science and Technology Guangzhou and Simou Technology innovatively developed the "DefectSpectrum" data set, which provides detailed and semantically rich large-scale annotation of industrial defects. As shown in Table 1, compared with other industrial data sets, the "DefectSpectrum" data set provides the most defect annotations (5438 defect samples) and the most detailed defect classification (125 defect categories
 Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Editor |KX To this day, the structural detail and precision determined by crystallography, from simple metals to large membrane proteins, are unmatched by any other method. However, the biggest challenge, the so-called phase problem, remains retrieving phase information from experimentally determined amplitudes. Researchers at the University of Copenhagen in Denmark have developed a deep learning method called PhAI to solve crystal phase problems. A deep learning neural network trained using millions of artificial crystal structures and their corresponding synthetic diffraction data can generate accurate electron density maps. The study shows that this deep learning-based ab initio structural solution method can solve the phase problem at a resolution of only 2 Angstroms, which is equivalent to only 10% to 20% of the data available at atomic resolution, while traditional ab initio Calculation
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
For AI, Mathematical Olympiad is no longer a problem. On Thursday, Google DeepMind's artificial intelligence completed a feat: using AI to solve the real question of this year's International Mathematical Olympiad IMO, and it was just one step away from winning the gold medal. The IMO competition that just ended last week had six questions involving algebra, combinatorics, geometry and number theory. The hybrid AI system proposed by Google got four questions right and scored 28 points, reaching the silver medal level. Earlier this month, UCLA tenured professor Terence Tao had just promoted the AI Mathematical Olympiad (AIMO Progress Award) with a million-dollar prize. Unexpectedly, the level of AI problem solving had improved to this level before July. Do the questions simultaneously on IMO. The most difficult thing to do correctly is IMO, which has the longest history, the largest scale, and the most negative
 PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
In 2023, almost every field of AI is evolving at an unprecedented speed. At the same time, AI is constantly pushing the technological boundaries of key tracks such as embodied intelligence and autonomous driving. Under the multi-modal trend, will the situation of Transformer as the mainstream architecture of AI large models be shaken? Why has exploring large models based on MoE (Mixed of Experts) architecture become a new trend in the industry? Can Large Vision Models (LVM) become a new breakthrough in general vision? ...From the 2023 PRO member newsletter of this site released in the past six months, we have selected 10 special interpretations that provide in-depth analysis of technological trends and industrial changes in the above fields to help you achieve your goals in the new year. be prepared. This interpretation comes from Week50 2023
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
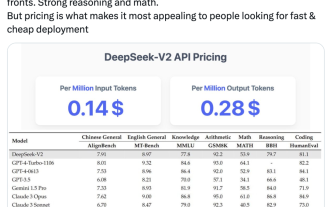 Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
May 07, 2024 pm 05:34 PM
Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
May 07, 2024 pm 05:34 PM
The latest large-scale domestic open source MoE model has become popular just after its debut. The performance of DeepSeek-V2 reaches GPT-4 level, but it is open source, free for commercial use, and the API price is only one percent of GPT-4-Turbo. Therefore, as soon as it was released, it immediately triggered a lot of discussion. Judging from the published performance indicators, DeepSeekV2's comprehensive Chinese capabilities surpass those of many open source models. At the same time, closed source models such as GPT-4Turbo and Wenkuai 4.0 are also in the first echelon. The comprehensive English ability is also in the same first echelon as LLaMA3-70B, and surpasses Mixtral8x22B, which is also a MoE. It also shows good performance in knowledge, mathematics, reasoning, programming, etc. And supports 128K context. Picture this
