As the iteration speed of large models becomes faster and faster, the scale of training clusters becomes larger and larger, and high-frequency software and hardware failures have become pain points that hinder the further improvement of training efficiency. The checkpoint system is responsible for the status during the training process. Storage and recovery have become the key to overcoming training failures, ensuring training progress and improving training efficiency.
Recently, the ByteDance Beanbao model team and the University of Hong Kong jointly proposed ByteCheckpoint. This is a large model checkpointing system native to PyTorch, compatible with multiple training frameworks, and supports efficient reading and writing of checkpoints and automatic re-segmentation. Compared with existing methods, it has significant performance improvements and ease-of-use advantages. This article introduces the challenges faced by Checkpoint in improving large model training efficiency, summarizes ByteCheckpoint’s solution ideas, system design, I/O performance optimization technology, and experimental results in storage performance and read performance testing.
Meta officials recently disclosed the failure rate of Llama3 405B training on 16384 H100 80GB training clusters - in just 54 days, 419 interruptions occurred, with an average crash every three hours, attracting the attention of many practitioners. .
As a common saying in the industry says, the only certainty for large-scale training systems is software and hardware failure. As the training scale and model size increase, overcoming software and hardware failures and improving training efficiency have become important influencing factors for large model iterations.
Checkpoint has become the key to improving training efficiency. In the Llama training report, the technical team mentioned that in order to combat the high failure rate, frequent checkpoints need to be performed during the training process to save the status of the model, optimizer, and data reader during training to reduce the loss of training progress.
The ByteDance Beanbao large model team and the University of Hong Kong recently released the results - ByteCheckpoint, a PyTorch native, compatible with multiple training frameworks, and a large model Checkpointing system that supports efficient reading and writing of Checkpoint and automatic re-segmentation.
Compared with the baseline method, ByteCheckpoint improves performance by up to 529.22 times on checkpoint saving and up to 3.51 times on loading. The minimalist user interface and Checkpoint automatic re-segmentation function significantly reduce user acquisition and usage costs and improve the ease of use of the system.
The results of the paper have now been made public. 
- ByteCheckpoint: A Unified Checkpointing System for LLM Development
- Paper link: https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-for-llm-development?view_from =research
Technical challenges of Checkpoint technology in large model training Current Checkpoint related technologies face a total of four challenges in supporting large model training efficiency: - The existing system design has flaws, which significantly increases the additional I/O overhead of training
In the process of training industrial-level large language models (LLM), the training status needs to pass checkpoint technology (Checkpointing) for saving and persistence. Typically, a Checkpoint consists of 5 parts (model, optimizer, data reader, random number and user-defined configuration). This process often brings minutes-level blockage to training, seriously affecting training efficiency. In large-scale training scenarios using remote persistent storage systems, the existing Checkpointing system does not fully utilize the GPU to CPU memory copy (D2H copy), serialization, local save, and upload to storage during the Checkpoint save process. Execution independence of each stage of the system. In addition, the parallel processing potential of different training processes sharing Checkpoint access tasks has not been fully explored. These system design deficiencies increase the additional I/O overhead caused by Checkpoint training. - Checkpoint is difficult to re-segment, and the development and maintenance overhead of manual segmentation script is too high
In different training stages of LLM (pre-training to SFT or RLHF) and different tasks (from When migrating Checkpoints between training tasks (pulling Checkpoints from different stages for automatic evaluation), it is usually necessary to re-segment the Checkpoints stored in the persistent storage system (Checkpoint Resharding) to adapt to the new parallelism configuration of the downstream tasks. and quotas for available GPU resources. Existing checkpointing systems [1, 2, 3, 4] all assume that the parallelism configuration and GPU resources remain unchanged during storage and loading, and cannot handle the need for checkpoint re-segmentation. A common solution currently in the industry is to customize Checkpoint merging or re-splitting scripts for different models. This method brings a lot of development and maintenance overhead, and has poor scalability. - The Checkpoint modules of different training frameworks are fragmented, which brings challenges to the unified management and performance optimization of Checkpoint
On the training platform in the industry, engineers and scientists often work together based on task characteristics , select the appropriate framework (Megatron-LM [5], FSDP [6], DeepSpeed [7], veScale [8, 9]) for training, and save the Checkpoint to the storage system. However, these different training frameworks have their own independent checkpoint formats and reading and writing modules. The checkpoint module designs of different training frameworks are different, which brings challenges to the unified checkpoint management and performance optimization of the underlying system. - Users of distributed training systems face multiple problems
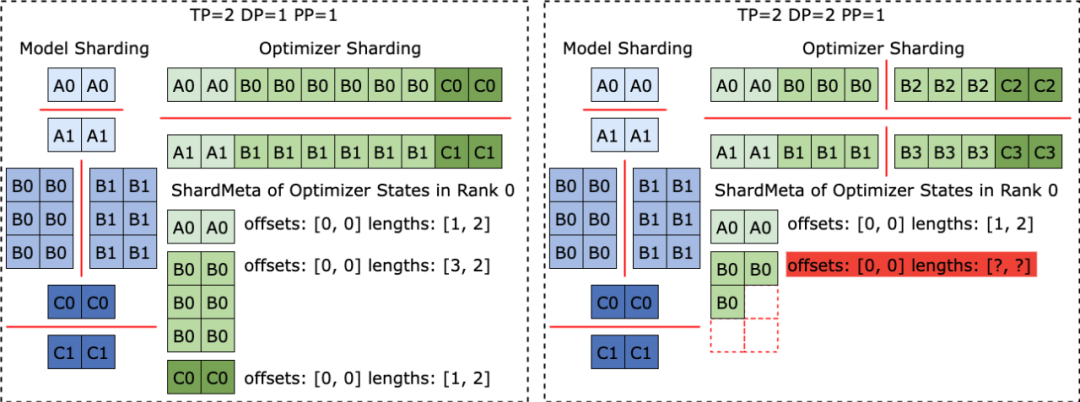
From the perspective of users of training systems (AI research scientists or engineers), when users use distributed training systems, The checkpoint direction is often troubled by three problems: 1) How to store checkpoints efficiently and save checkpoints without affecting training efficiency. 2) How to re-segment the Checkpoint and read it correctly according to the new parallelism for the Checkpoint stored under one degree of parallelism. 3) How to upload the trained products to a cloud storage system (HDFS, S3, etc.) and manually manage multiple storage systems, which is costly for users to learn and use. In response to the above problems, the ByteDance Beanbao model team and the laboratory of Professor Wu Chuan of the University of Hong Kong jointly launched ByteCheckpoint. ByteCheckpoint is a high-performance distributed checkpointing system that is unified with multiple training frameworks, supports multiple storage backends, and has the ability to automatically re-segment checkpoints. ByteCheckpoint provides a simple and easy-to-use user interface, implements a large number of I/O performance optimization technologies to improve storage and reading checkpoint performance, and supports flexible migration of checkpoints in tasks with different parallelism configurations. ByteCheckpoint adopts a metadata/tensor data separated storage architecture to realize the decoupling of Checkpoint management and training framework and parallelism .Tensor slices (Tensor Shard) of models in different training frameworks and optimizers are stored in storage files, and meta information (TensorMeta, ShardMeta, ByteMeta) is stored in a globally unique metadata file.
When using different parallelism configurations to read Checkpoint, as shown in the figure below, each training process only needs to set the query meta-information according to the current parallelism to obtain the storage location of the tensor required by the process. Then read directly according to the position to realize automatic checkpoint re-segmentation.
Clever solution to irregular tensor segmentationWhen different training frameworks are running, they often flatten the shape of the tensor in the model or optimizer into one dimension, thereby improving the set Communication performance. This flattening operation brings the challenge of irregular tensor sharding (Irregular Tensor Sharding) to Checkpoint storage. As shown in the figure below, in Megatron-LM (distributed large model training framework developed by NVIDIA) and veScale (PyTorch native distributed large model training framework developed by ByteDance), the model parameters correspond to The optimizer state will be flattened into one dimension, merged, and then split according to data parallelism. This results in tensors being irregularly split into different processes, and the meta-information of tensor slices cannot be represented using offset and length tuples, making storage and reading difficult.
The problem of irregular tensor segmentation also exists in the FSDP framework. To eliminate irregularly cut tensor slices, the FSDP framework will perform all-gather set communication and D2H copy operations on one-dimensional tensor slices on all processes before storing Checkpoints to obtain complete irregular cuts. divided tensor. This solution brings huge communication and frequent GPU-CPU synchronization overhead, which seriously affects the performance of Checkpoint storage. To address this problem, ByteCheckpoint proposed the Asynchronous Tensor Merging technology. ByteCheckpoint first finds out the irregularly divided tensors in different processes, and then uses asynchronous P2P communication to distribute these irregular tensors to different processes for merging. All P2P communication waits (Wait) and tensor D2H copy operations for these irregular tensors are postponed until they are about to enter the serialization phase, thereby eliminating frequent synchronization overhead and increasing communication with other Checkpoint storage processes. Perform overlap. The following figure shows the system architecture of ByteCheckpoint: The API layer provides simple, easy-to-use and unified reading and writing for different training frameworks ( Save ) and read (Load) interface. The Planner layer will generate access plans for different training processes based on the access objects, and hand them over to the Execution layer to perform the actual I/O tasks. The Execution layer performs I/O tasks and interacts with the Storage layer, using various I/O optimization technologies for high-performance checkpoint access. The Storage layer manages different storage backends and performs corresponding optimizations according to different storage backends during I/O tasks. The layered design enhances the scalability of the system to support more training frameworks and storage backends in the future.
ByteCheckpoint’s API use cases are as follows:
ByteCheckpoint は最小限の API を提供し、ユーザーの開始コストを削減します。チェックポイントを保存および読み取りする場合、ユーザーはストレージ関数とロード関数を呼び出して、保存および読み取りの対象となるコンテンツ、ファイル システム パス、およびさまざまなパフォーマンス最適化オプションを渡すだけで済みます。 teCheckpoint 完全に非同期のストレージ パイプラインを設計しました ( Save Pipeline) は、チェックポイント ストレージのさまざまなステージ (P2P テンソル転送、D2H レプリケーション、シリアル化、ローカル ファイル システムの保存およびファイル システムのアップロード) を分割して、効率的なパイプラインの実行を実現します。
D2H コピー プロセスでは、ByteCheckpoint は固定メモリ プール (Pinned Memory Pool) を使用し、繰り返しメモリ割り当ての時間オーバーヘッドを削減します。 さらに、高頻度のストレージ シナリオで固定メモリ プールのリサイクルを同期的に待機することによって生じる追加の時間オーバーヘッドを削減するために、ByteCheckpoint は固定メモリ プールに基づくピンポン バッファリング メカニズムを追加します。 2 つの独立したメモリ プールが交互に読み取りバッファと書き込みバッファの役割を果たし、後続の I/O 操作を実行する GPU および I/O ワーカーと対話して、ストレージ効率をさらに向上させます。
データ並列 (Data-Parallel または DP) トレーニングでは、モデルは異なるデータ並列プロセス グループ (DP グループ) 間で冗長化され、負荷分散アルゴリズムが採用され、冗長性が均等に分散されます。ストレージ用にテンソルをさまざまなプロセス グループにモデル化し、チェックポイントのストレージ効率を効果的に向上させます。図に示すように、チェックポイントを読み取るために並列処理を変更する場合、新しいトレーニング プロセスは、オリジナル テンソル スライスからその一部を読み取ります。 ByteCheckpoint は、オンデマンドの部分ファイル読み取り (部分ファイル読み取り) テクノロジーを使用して、リモート ストレージから必要なファイルの断片を直接読み取り、不要なデータのダウンロードや読み取りを回避します。 データ並列 (Data-Parallel または DP) トレーニングでは、モデルは異なるデータ並列プロセス グループ (DP グループ) 間で冗長であり、異なるプロセス グループは同じテンソル スライスを繰り返し読み取ります。大規模なトレーニング シナリオでは、さまざまなプロセス グループがリモート永続ストレージ システム (HDFS など) に同時に大量のリクエストを送信するため、ストレージ システムに大きな負荷がかかります。
繰り返しのデータ読み取りを排除し、トレーニング プロセスによって HDFS に送信されるリクエストを削減し、読み込みパフォーマンスを最適化するために、ByteCheckpoint は同じテンソル スライス読み取りタスクを異なるプロセスに均等に分散し、フェッチ中にリモート ファイルを読み取ります。 、GPU 間のアイドル帯域幅はテンソル スライスの送信に使用されます。 experimperimperimperimperimperimperimpalimpalimpalimpalimpermental configuration densegptモデルとsparsegptモデル(GPT-3 [10]構造に基づいて実装)を使用し、異なるモデルパラメーター量と異なるものを使用します。トレーニング フレームワーク ByteCheckpoint のチェックポイント アクセスの正確性、ストレージ パフォーマンス、および読み取りパフォーマンスが、さまざまなサイズのトレーニング タスクで評価されました。実験構成と正確性テストの詳細については、完全な論文を参照してください。
ストレージ パフォーマンス テストでは、チームはトレーニング プロセス中にさまざまなモデル サイズとトレーニング フレームワークを比較し、合計 50 ステップまたは 100 ステップごとに Checkpoint、Bytecheckpoint、および Baseline メソッドを保存しました。トレーニングによって発生するブロック時間 (チェックポイントの停止)。 書き込みパフォーマンスの徹底的な最適化のおかげで、ByteCheckpoint は、576 カードの SparseGPT 110B - Megatron-LM トレーニング タスクで、ベースラインより 10% 高いパフォーマンスを達成しました。パフォーマンスの向上は 66.65 ~ 74.55 倍であり、256 カードの DenseGPT 10B-FSDP トレーニング タスクでは 529.22 倍のパフォーマンス向上に達することもあります。
読み取りパフォーマンス テストでは、チームはダウンストリーム タスクの並列性に基づいて、チェックポイントを読み取るさまざまなメソッドの読み込み時間を比較しました。 ByteCheckpoint は、ベースライン手法と比較して 1.55 ~ 3.37 倍のパフォーマンス向上を達成します。 チームは、ByteCheckpoint のパフォーマンス向上が Megatron-LM ベースライン手法と比較してより顕著であることを観察しました。これは、Megatron-LM が、チェックポイントを新しい並列処理構成に読み取る前に、オフライン スクリプトを実行して分散チェックポイントを再シャードする必要があるためです。対照的に、ByteCheckpoint は、オフライン スクリプトを実行せずに自動チェックポイント再セグメント化を直接実行し、読み取りを効率的に完了できます。
最後に、ByteCheckpoint の将来の計画に関して、チームは 2 つの側面から開始したいと考えています: まず、超大規模 GPU クラスター トレーニング タスクの効率的なチェックポイント設定をサポートするという長期目標を達成します。 2 番目に、大規模モデルのトレーニングのライフサイクル全体のチェックポイント管理を実現し、事前トレーニング (Pre-Training) から教師あり微調整 (SFT)、強化学習 (RLHF) までのすべてのシナリオでチェックポイントをサポートします。 )と評価(Evaluation)およびその他のシナリオ。 ByteDance Beanbao ビッグ モデル チームは 2023 年に設立されました。業界で最先端の AI ビッグ モデル テクノロジーを開発し、世界クラスの研究チームになることに尽力しています。技術と社会の発展に貢献します。 現在、チームには引き続き優秀な人材が入社しており、そのキーワードはハードコア、オープン、そして革新的な精神に満ちており、チームメンバーを奨励し、前向きな職場環境を作り出すことに尽力しています。学び、成長し続けること、そして挑戦を恐れず卓越性を追求すること。 革新的な精神と責任感を持った技術人材と協力して、大規模モデルトレーニングの効率向上を促進し、より多くの進歩と結果を達成したいと考えています。 [1] Mohan、Jayashree、Amar Phanishaye、Vijay Chidambaram: 頻繁な{きめ細かな{DNN} チェックポイント。」ファイルおよびストレージ テクノロジー (FAST 21)。[2] アイゼンマン、アサフ他「{Check-N-Run}: 第 19 回 USENIX シンポジウム」ネットワーク化されたシステムの設計と実装 (NSDI 22) について。[3] Wang、Zhuang 他「Gemini: 第 29 回シンポジウムの議事録」オペレーティング システムの原則について。2023 年。[4] Gupta、Tanmaey、他「ジャストインタイム チェックポイント: ディープ ラーニング トレーニングの失敗からの低コストのエラー回復」システム。2024.[5] Shoeybi、Mohammad、他「Megatron-lm: モデル並列処理を使用した数十億パラメータ言語モデルのトレーニング。arXiv プレプリント arXiv:1909.08053 (2019)」 [6] Zhao、Yanli、他「Pytorch fsdp: 完全にシャード化されたデータの並列スケーリングに関する経験。」arXiv プレプリント arXiv:2304.11277 (2023)。[7] Rasley、Jeff、他。 「Deepspeed: システムの最適化により、1,000 億を超えるパラメーターを使用した深層学習モデルのトレーニングが可能になります。2020 年の第 26 回 ACM SIGKDD 国際会議の議事録。」[8] Jiang、Ziheng、他。 「{MegaScale}: 大規模な言語モデルのトレーニングを 10,000 個を超える {GPU} に拡張する。」第 21 回 USENIX Symposium on Networked Systems Design and Implementation (NSDI 24)。[9] veScale: A PyTorch Native LLM。トレーニング フレームワーク https://github.com/volcengine/veScale[10] Brown、Tom、他「言語モデルはニューラル情報処理システムの進歩 33 (2020)」 : 1877-1901.The above is the detailed content of Llama3 training crashes every 3 hours? Big bean bag model and HKU team improve crispy Wanka training. For more information, please follow other related articles on the PHP Chinese website!




























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



