
 Technology peripherals
AI
ICML 2024 | Character interaction images, now I understand your prompt words better, Peking University launches a character interaction image generation framework based on semantic perception
Technology peripherals
AI
ICML 2024 | Character interaction images, now I understand your prompt words better, Peking University launches a character interaction image generation framework based on semantic perception
ICML 2024 | Character interaction images, now I understand your prompt words better, Peking University launches a character interaction image generation framework based on semantic perception


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Character interaction image generation refers to generating images that meet text description requirements, and the content is the interaction between people and objects, and the image is required to be as realistic and semantic as possible. In recent years, text-generated image models have made significant progress in generating real-life images, but these models still face challenges in generating high-fidelity images with human interaction as the main content. The difficulty mainly stems from two aspects: first, the complexity and diversity of human postures bring challenges to reasonable character generation; second, the unreliable generation of interactive boundary areas (interactive semantic-rich areas) may lead to the failure of character interactive semantic expression. insufficient.
In response to the above problems, a research team from Peking University proposed a posture and interaction-aware human interaction image generation framework (SA-HOI), which uses the generation quality of human postures and interaction boundary area information as a guide for the denoising process. More reasonable and realistic character interaction images are generated. In order to comprehensively evaluate the quality of generated images, they also proposed a comprehensive human interaction image generation benchmark.

Paper link: https://proceedings.mlr.press/v235/xu24e.html
Project homepage: https://sites.google.com/view/sa-hoi/
Source code link: https://github.com/XZPKU/SA-HOI
Lab homepage: http://www.wict.pku.edu.cn/mipl
SA-HOI is A semantic-aware human interaction image generation method improves the overall quality of human interaction image generation and reduces existing generation problems from both human body posture and interactive semantics. By combining the image inversion method, an iterative inversion and image correction process is generated, which can gradually self-correct the generated image and improve the quality.
In the paper, the research team also proposed the first human interaction image generation benchmark covering human-object, human-animal and human-human interactions, and designed targeted evaluation indicators for human interaction image generation. Extensive experiments show that this method outperforms existing diffusion-based image generation methods under both evaluation metrics for human interaction image generation and conventional image generation.
Method Introduction
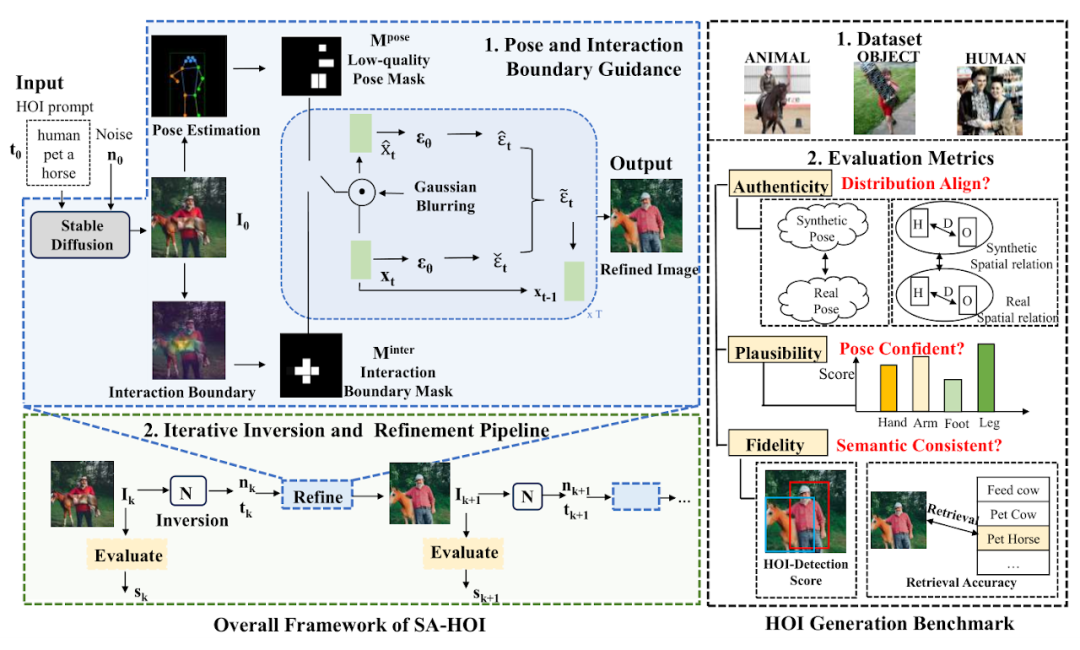
Method introduction Posture and interactive guidance(Pose and Interaction Guidance, PIG) and
Iterative Inversion and Refinement Pipeline(Iterative Inversion and Refinement Pipeline, IIR). In PIG, for a given character interaction text description For interactive guidance, the segmentation model is used to locate the interaction boundary area, obtain key points The pseudocode of pose and interaction guided sampling is shown in Figure 2. In each denoising step, we first obtain the predicted noise ϵt and intermediate reconstruction ϵt as designed in the stable diffusion model (Stable Diffusion). We then apply Gaussian blur G on to obtain the degraded latent features and , and subsequently introduce the information in the corresponding latent features into the denoising process. Where where ϕt is the threshold that generates the mask at time step t. Similarly, for interactive guidance, the author of the paper uses the segmentation model to obtain the object's outer contour point O and the human body joint point C, calculates the distance matrix D between the person and the object, and samples the key points of the interaction boundary Iterative inversion and image correction process 生成された画像の品質評価をリアルタイムで取得するために、論文の著者は反復 操作のガイドとして品質評価器 Q を導入しています。 k 番目のラウンド画像 しかし、そのようなノイズはすぐには入手できないため、画像反転法 反復前後の品質スコアを比較することで、最適化を継続するかどうかを判断できます。 キャラクターインタラクション画像生成ベンチマーク ヒューマンインタラクション画像生成タスク用に設計された既存のモデルやベンチマークが存在しないことを考慮すると、著者は、この論文では、150 のヒューマン インタラクション カテゴリを含む実際のヒューマン インタラクション画像データ セットと、ヒューマン インタラクション画像生成用にカスタマイズされたいくつかの評価指標を含む、ヒューマン インタラクション画像生成ベンチマークを収集および統合しました。 このデータセットは、オープンソースの人間インタラクション検出データセット HICO-DET [5] からフィルタリングされ、人間と物体、人間と動物、人間と人間の 3 つの異なるインタラクション シナリオをカバーする 150 の人間インタラクション カテゴリを取得します。この論文では、生成された人間のインタラクション画像の品質を評価するための参照データ セットとして、合計 5,000 枚の人間のインタラクションの実際の画像が収集されました。 生成されたキャラクターインタラクション画像の品質をより良く評価するために、論文の著者は、信頼性(Authenticity)、実現可能性(Plausibility)、忠実性(Fidelity)の観点から、キャラクターインタラクション生成のいくつかの評価基準をカスタマイズしました。生成された画像の。信頼性の観点から、論文の著者は、生成された結果が実際の画像に近いかどうかを評価するために、姿勢分布距離と人物-オブジェクト距離分布を導入しました。生成された結果が分布という意味で実際の画像に近いほど、優れています。品質。実現可能性の観点から、生成された人間の関節の信頼性と合理性を測定するためにポーズ信頼度スコアが計算されます。忠実度の観点からは、人間のインタラクション検出タスクと画像テキスト検索タスクを使用して、生成された画像と入力テキストの間の意味上の一貫性を評価します。 実験結果 既存手法との比較実験結果を表1、表2に示します。それぞれ、キャラクターインタラクション画像生成指標と従来の画像生成指標の性能を比較しています。表 2: 従来の画像生成指標における既存手法との実験結果の比較 さらに、論文の著者は主観的な評価も実施し、多くのユーザーに人体の品質、オブジェクトの外観、インタラクティブなセマンティクス、全体的な品質などの複数の観点から評価してもらいました。実験結果は、SA-HOI 手法が優れていることを証明しています。あらゆる角度から人間の美学に沿って。 既存手法による主観評価結果 定性的実験において、以下の図は、同じキャラクター インタラクション カテゴリの説明に対して、さまざまな方法で生成された結果の比較を示しています。上記の写真群では、新しい手法を用いたモデルは「キス」の意味を正確に表現しており、生成された人体の姿勢もより合理的になっています。以下の写真群では、論文の手法も他の手法に存在する人体の歪みや歪みを軽減することに成功しており、手がかかる部分にスーツケースのレバーを生成することで「スーツケースを取る」というインタラクションを強化しています。スーツケースと対話することで、人体の姿勢と対話セマンティクスの両方において他の方法よりも優れた結果が得られます。 。 [1] Rombach, R.、Blattmann, A.、Lorenz, D.、Esser, P.、および Ommer, B. 潜在拡散モデルによる高解像度画像合成。 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)、pp. 10684–10695、2022 年 6 月 [2] HuggingFace、2022。URL https://huggingface 。 co/CompVis/stable-diffusion-v1-4. [3] Chen、K.、Wang、J.、Pang、J.、Cao、Y.、Xiong、Y.、Li、X。 、Sun、S.、Feng、W.、Liu、Z.、Xu、J.、Zhang、Z.、Cheng、D.、Zhu、C .、Cheng、T.、Zhao、Q.、Li、 B.、Lu, X.、Zhu, R.、Wu, Y.、Dai, J.、Wang, J.、Shi, J.、Ouyang, W.、Loy, C.C.、および Lin, D. MM検出: オープンmmlab 検出ツールボックスとベンチマーク。arXiv プレプリント arXiv:1906.07155、2019。[4] Ron Mokady、Amir Hertz、Kfir Aberman、Yael Pritch、および Daniel Cohen-Or。 arXiv:2211.09794、2022。 [5] Yu-Wei Chao、Zhan Wang、Yugeng He、Jiaxuan Wang、Jia Deng . HICO: 画像内の人間とオブジェクトの相互作用を認識するためのベンチマーク、2015 年の IEEE 国際会議の議事録。 and noise
and noise  , a stable diffusion model (Stable Diffusion [2]) is first used to generate
, a stable diffusion model (Stable Diffusion [2]) is first used to generate  as an initial image, and a pose detector [3] is used to obtain the human body joint positions
as an initial image, and a pose detector [3] is used to obtain the human body joint positions  and the corresponding confidence score
and the corresponding confidence score  , constructing a pose mask
, constructing a pose mask  that highlights low-quality pose regions.
that highlights low-quality pose regions.  and corresponding confidence scores
and corresponding confidence scores  , and highlight the interaction area in the interaction mask
, and highlight the interaction area in the interaction mask  to enhance the semantic expression of the interaction boundary. For each denoising step,
to enhance the semantic expression of the interaction boundary. For each denoising step,  and
and  are used as constraints to correct these highlighted areas, thereby reducing the generation problems existing in these areas. In addition, IIR is combined with the image inversion model N to extract the noise n and the embedding t of the text description from the image that needs further correction, and then use PIG to perform the next correction on the image, and use the quality evaluator Q to evaluate the quality of the corrected image. Evaluate and use operations to gradually improve image quality. 🎙
are used as constraints to correct these highlighted areas, thereby reducing the generation problems existing in these areas. In addition, IIR is combined with the image inversion model N to extract the noise n and the embedding t of the text description from the image that needs further correction, and then use PIG to perform the next correction on the image, and use the quality evaluator Q to evaluate the quality of the corrected image. Evaluate and use operations to gradually improve image quality. 🎙  and
and  are used to generate
are used to generate  and
and  , and highlight low pose quality areas in
, and highlight low pose quality areas in  and
and  to guide the model to reduce distortion generation in these areas. In order to guide the model to improve low-quality areas, low pose score areas will be highlighted through the following formula:
to guide the model to reduce distortion generation in these areas. In order to guide the model to improve low-quality areas, low pose score areas will be highlighted through the following formula: 
 , x, y are the pixel-by-pixel coordinates of the image, H, W are the image sizes, and σ is the variance of the Gaussian distribution.
, x, y are the pixel-by-pixel coordinates of the image, H, W are the image sizes, and σ is the variance of the Gaussian distribution.  represents the attention centered on the i-th joint. By combining the attention of all joints, we can form the final attention map
represents the attention centered on the i-th joint. By combining the attention of all joints, we can form the final attention map  and use a threshold to convert into a mask .
and use a threshold to convert into a mask .  from it, and uses and posture guidance The same method generates interactive attention
from it, and uses and posture guidance The same method generates interactive attention  and mask and is applied to calculate the final prediction noise.
and mask and is applied to calculate the final prediction noise.  については、評価子 Q を使用してその品質スコア
については、評価子 Q を使用してその品質スコア  を取得し、その後
を取得し、その後  に基づいて
に基づいて  が生成されます。最適化後に の主な内容を保持するには、対応するノイズがノイズ除去の初期値として必要です。
が生成されます。最適化後に の主な内容を保持するには、対応するノイズがノイズ除去の初期値として必要です。  が導入され、そのノイズ潜在的特徴
が導入され、そのノイズ潜在的特徴  とテキスト埋め込み
とテキスト埋め込み  を PIG の入力として取得し、最適化された結果
を PIG の入力として取得し、最適化された結果  を生成します。
を生成します。  と
と に有意差がない場合、つまり閾値θを下回っている場合は、プロセスに問題がある可能性があると考えられます。画像に十分な改善が加えられたため、最適化が終了し、最高品質スコアの画像が出力されました。
に有意差がない場合、つまり閾値θを下回っている場合は、プロセスに問題がある可能性があると考えられます。画像に十分な改善が加えられたため、最適化が終了し、最高品質スコアの画像が出力されました。  ヒューマンインタラクション画像生成ベンチマーク(データセット+評価指標)
ヒューマンインタラクション画像生成ベンチマーク(データセット+評価指標) 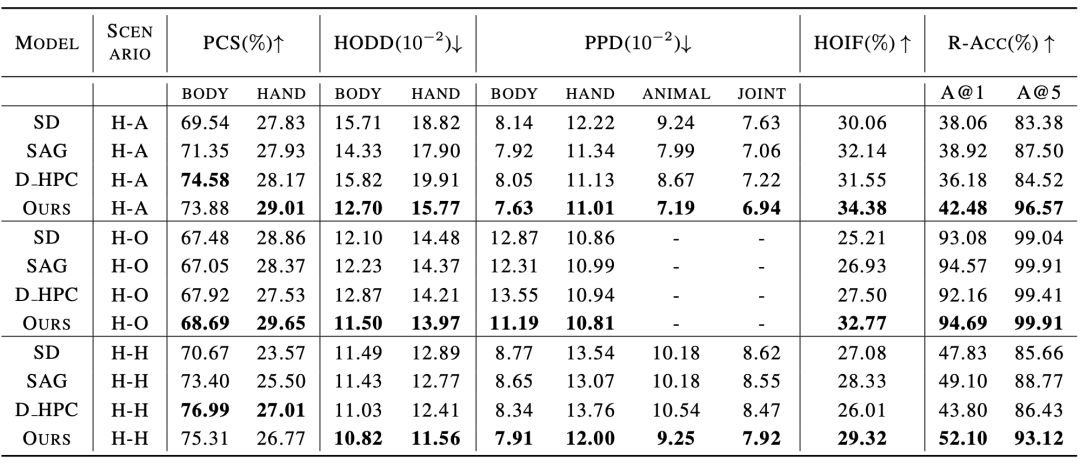

The above is the detailed content of ICML 2024 | Character interaction images, now I understand your prompt words better, Peking University launches a character interaction image generation framework based on semantic perception. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
 Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Conference Introduction With the rapid development of science and technology, artificial intelligence has become an important force in promoting social progress. In this era, we are fortunate to witness and participate in the innovation and application of Distributed Artificial Intelligence (DAI). Distributed artificial intelligence is an important branch of the field of artificial intelligence, which has attracted more and more attention in recent years. Agents based on large language models (LLM) have suddenly emerged. By combining the powerful language understanding and generation capabilities of large models, they have shown great potential in natural language interaction, knowledge reasoning, task planning, etc. AIAgent is taking over the big language model and has become a hot topic in the current AI circle. Au
