
 Backend Development
Python Tutorial
timeit.repeat - playing with repetitions to understand patterns
Backend Development
Python Tutorial
timeit.repeat - playing with repetitions to understand patterns
timeit.repeat - playing with repetitions to understand patterns
Aug 09, 2024 am 07:25 AM1. The problem
Over your software engineering career, you might encounter a piece of code that performs poorly, taking way longer than acceptable. To make matters worse, the performance is inconsistent and quite variable across multiple executions.
At this point in time, you would have to accept that when it comes to software performance, there is a lot of non-determinism at play. The data can be distributed within a window and sometimes follows a normal distribution. Other times, it can be erratic with no obvious patterns.
2. The approach
This is when benchmarking comes into play. Executing your code five times is good, but at the end of the day, you have just five data points, with too much value placed on each data point. We need to have a much bigger number of repetitions of the same code block to see a pattern.
3. The question
How many data points should one have? Much has been written about it, and one of the papers I covered
Rigorous performance evaluation requires benchmarks to be built,
executed and measured multiple times in order to deal with random
variation in execution times. Researchers should provide measures
of variation when reporting results.
Kalibera, T., & Jones, R. (2013). Rigorous benchmarking in reasonable time. Proceedings of the 2013 International Symposium on Memory Management. https://doi.org/10.1145/2491894.2464160
When measuring performance, we might want to measure CPU, memory, or disk usage to get a broader picture of the performance. It is usually best to start with something simple, like time elapsed, since it is easier to visualize. A 17% CPU usage doesn't tell us much. What should it be? 20% or 5? CPU Usage is not one of the natural ways in which humans perceive performance.
4. The experiment
I am going to use python's timeit.repeat method to repeat a simple code execution block. The code block just multiplies numbers from 1 to 2000.
1 2 |
|
This is the method signature
1 2 3 4 5 6 7 8 |
|
What are repeat and number?
Let's start with number. If the code block is too small, it will terminate so quickly that you would not be able to measure anything. This argument mentions the number of times the stmt has to be executed. You can consider this as the new code block. The float returned is for stmt X number execution time.
In our case, we will keep number as 1000 since multiplication up to 2000 is expensive.
Next, move on to repeat. This specifies the number of repetitions or the number of times the above block has to be executed. If repeat is 5, then the list[float] returns 5 elements.
Let's start with creating a simple execution block
1 2 3 4 5 6 7 |
|
We want to execute it in different repeat values
1 |
|
The code is pretty simple and straightforward
5. Exploring the Results
Now we reach the most important part of the experiment - which is to interpret data. Please be advised, that different people can interpret it differently and there is no single correct answer.
Your definition of correct answer depends a lot on what you are trying to achieve. Are you concerned with the performance degradation of 95% of your users? Or, are you worried about performance degradation of the tail 5% of your users who are quite vocal?
5.1. Execution Time Analysis Statistics for multiple values of repeat
As we can see, the min and max time are whacky. It shows how one datapoint can be enough to change the value of mean. The worst part is that high min and high max are for different value of repeats. There is no correlation and it just showcases the power of outliers.
Next we move to median and notice that as we increase number of repeats, the median goes down, except for 20. What can explain it? It just shows how smaller number of repeats implies that we don't necessarily get the full breath of possible values.
Moving to truncated mean, where the lowest 2.5% and highest 2.5% are trimmed off. This is useful when you don't care about outlier users and want to to focus on the performance of the middle 95% of your users.
Beware, trying to improve the performance of the middle 95% of the users carries the possibility of degrading the performance of the outlier 5% of the users.

5.2. Execution Time Distribution for multiple values of repeat
Next we want to see where all the data lies. We would use histogram with bin of 10 to see where the data falls. With repetitions of 5 we see that they are mostly equally spaced. This is not one usually expects as sampled data should follow a normal looking distribution.
In our case the value is bounded on the lower side and unbounded on the upper side, since it will take more than 0 seconds to run any code, but there is no upper time limit. This means our distribution should look like a normal distribution with a long right tail.
Going forward with higher values of repeat, we see a tail emerging on the right. I would expect with higher number of repeat, there would be a single histogram bar, which is tall enough that outliers are overshadowed.
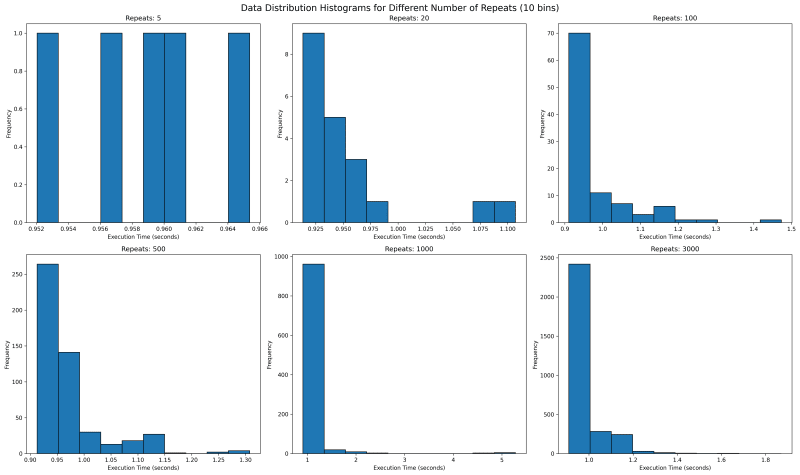
5.3. Execution Time Distribution for values 1000 and 3000
How about we look at larger values of repeat to get a sense? We see something unusual. With 1000 repeats, there are a lot of outliers past 1.8 and it looks a lot more tighter. The one on the right with 3000 repeat only goes upto 1.8 and has most of its data clustered around two peaks.
What can it mean? It can mean a lot of things including the fact that sometimes maybe the data gets cached and at times it does not. It can point to many other side effects of your code, which you might have never thought of. With the kind of distribution of both 1000 and 3000 repeats, I feel the TM95 for 3000 repeat is the most accurate value.

6. Appendix
6.1. Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 |
|
The above is the detailed content of timeit.repeat - playing with repetitions to understand patterns. For more information, please follow other related articles on the PHP Chinese website!

Hot Article
Hot tools Tags
Hot Article
Hot Article Tags

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How Do I Use Beautiful Soup to Parse HTML?
Mar 10, 2025 pm 06:54 PM
How Do I Use Beautiful Soup to Parse HTML?
Mar 10, 2025 pm 06:54 PM
How Do I Use Beautiful Soup to Parse HTML?

 How to Use Python to Find the Zipf Distribution of a Text File
Mar 05, 2025 am 09:58 AM
How to Use Python to Find the Zipf Distribution of a Text File
Mar 05, 2025 am 09:58 AM
How to Use Python to Find the Zipf Distribution of a Text File
 How to Work With PDF Documents Using Python
Mar 02, 2025 am 09:54 AM
How to Work With PDF Documents Using Python
Mar 02, 2025 am 09:54 AM
How to Work With PDF Documents Using Python
 How to Cache Using Redis in Django Applications
Mar 02, 2025 am 10:10 AM
How to Cache Using Redis in Django Applications
Mar 02, 2025 am 10:10 AM
How to Cache Using Redis in Django Applications
 How to Perform Deep Learning with TensorFlow or PyTorch?
Mar 10, 2025 pm 06:52 PM
How to Perform Deep Learning with TensorFlow or PyTorch?
Mar 10, 2025 pm 06:52 PM
How to Perform Deep Learning with TensorFlow or PyTorch?
 How to Implement Your Own Data Structure in Python
Mar 03, 2025 am 09:28 AM
How to Implement Your Own Data Structure in Python
Mar 03, 2025 am 09:28 AM
How to Implement Your Own Data Structure in Python
 Serialization and Deserialization of Python Objects: Part 1
Mar 08, 2025 am 09:39 AM
Serialization and Deserialization of Python Objects: Part 1
Mar 08, 2025 am 09:39 AM
Serialization and Deserialization of Python Objects: Part 1
