
 Technology peripherals
AI
Two papers were nominated for the Best Paper Honorable Mention at the same time. The first Real-Time Live Chinese team at SIGGRAPH uses generative AI to create a 3D world.
Technology peripherals
AI
Two papers were nominated for the Best Paper Honorable Mention at the same time. The first Real-Time Live Chinese team at SIGGRAPH uses generative AI to create a 3D world.
Two papers were nominated for the Best Paper Honorable Mention at the same time. The first Real-Time Live Chinese team at SIGGRAPH uses generative AI to create a 3D world.

SIGGRAPH, persidangan akademik global teratas yang memfokuskan pada grafik komputer, muncul dengan trend baharu.
Pada persidangan SIGGRAPH 2024 yang diadakan minggu lepas, antara kertas kerja terbaik dan anugerah lain, pasukan dari Makmal MARS Universiti Sains dan Teknologi Shanghai menerima dua pencalonan kehormat untuk kertas terbaik pada masa yang sama, dan hasil penyelidikannya adalah juga bergerak pantas ke arah perindustrian.
Pengarang menggunakan kaedah model generatif untuk membuka cara baharu untuk terus mengubah imaginasi kepada model 3D yang kompleks.文 Clay dan Dresscode, yang dicalonkan untuk kertas terbaik, adalah janaan 3D dan penjanaan pakaian 3D.

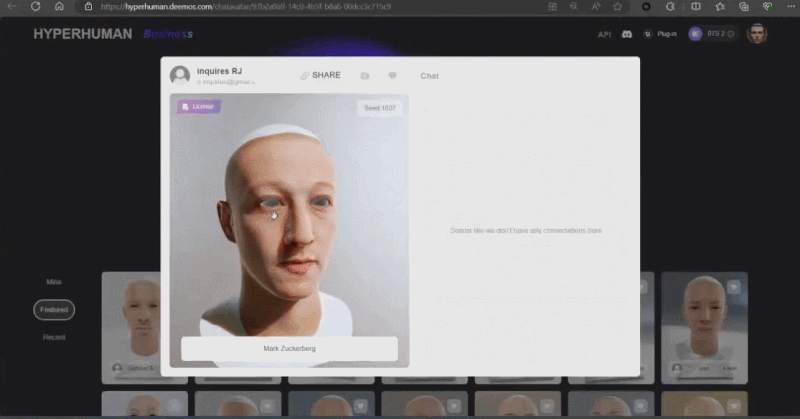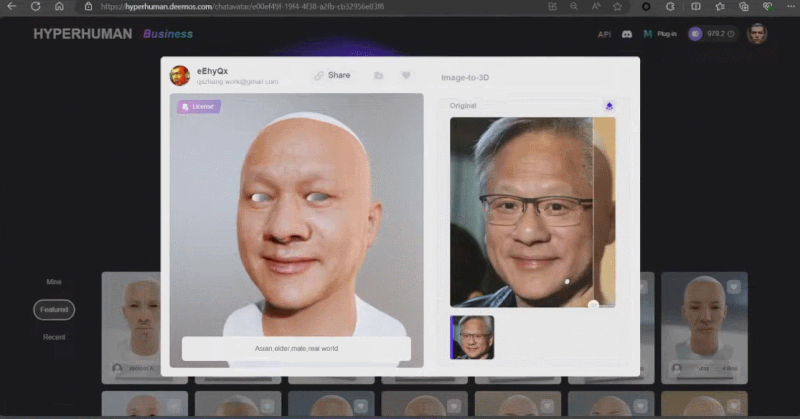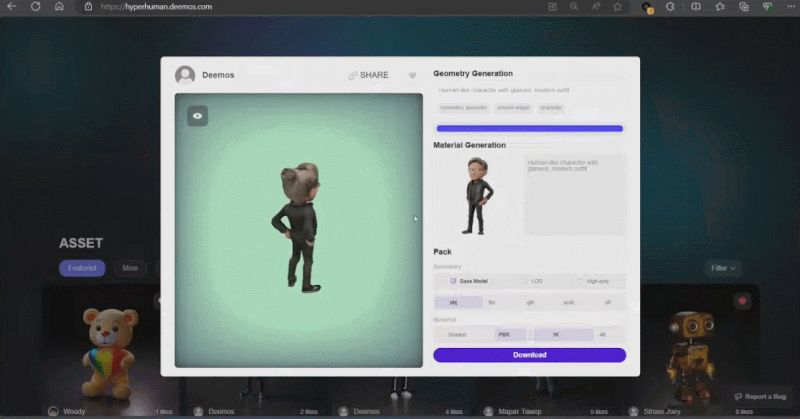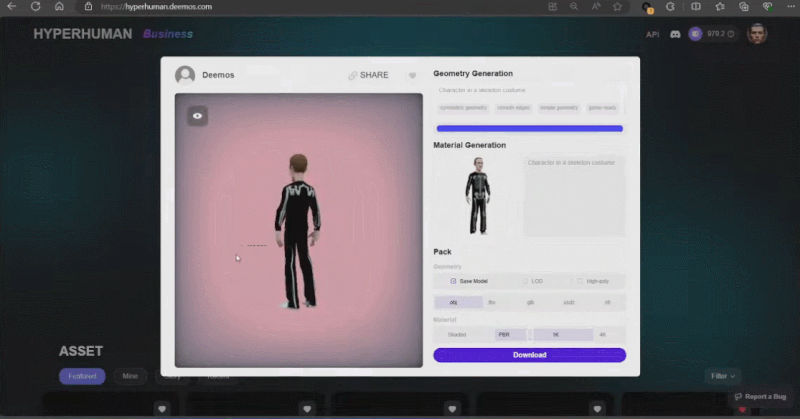
Zhang Qixuan, pengarang kertas kerja, pelajar siswazah tahun kedua dan CTO syarikat permulaan Yingmo Technology, mula-mula menunjukkan penyelesaian penjanaan 3D berdasarkan CLAY. Tahun lepas, pasukan Shadow Eye menggunakan gesaan teks ringkas (Prompt) untuk membina model 3D yang realistik untuk Zuckerberg dan Huang Jen-Hsun, menjadi pasukan China pertama yang mengambil bahagian dalam SIGGRAPH Real-Time Live. Tahun ini, penyelesaian penjanaan 3D mereka menggunakan satu imej sebagai input untuk menjana imej kartun Xiao Zha dan Lao Huang dalam gaya yang berbeza.
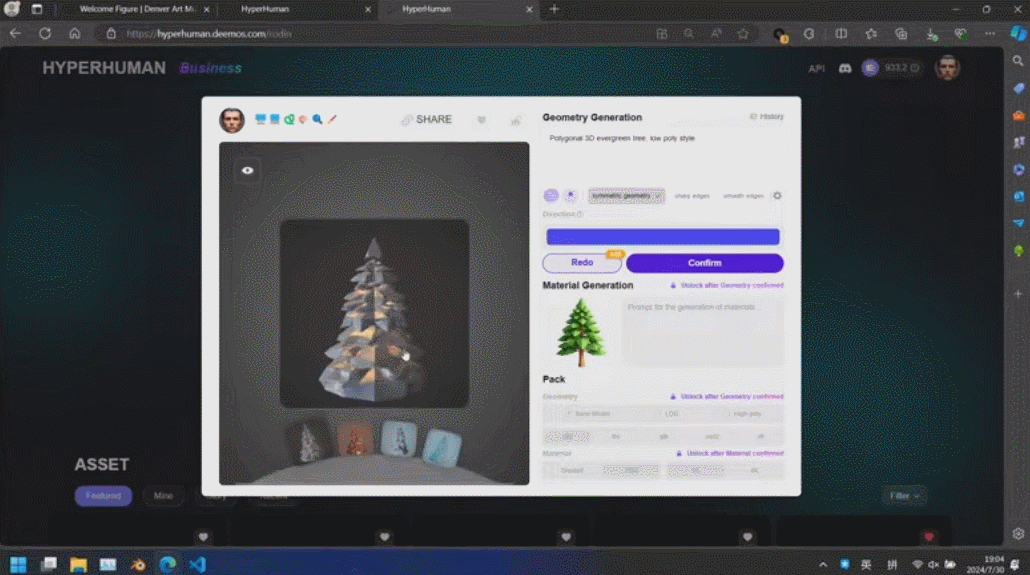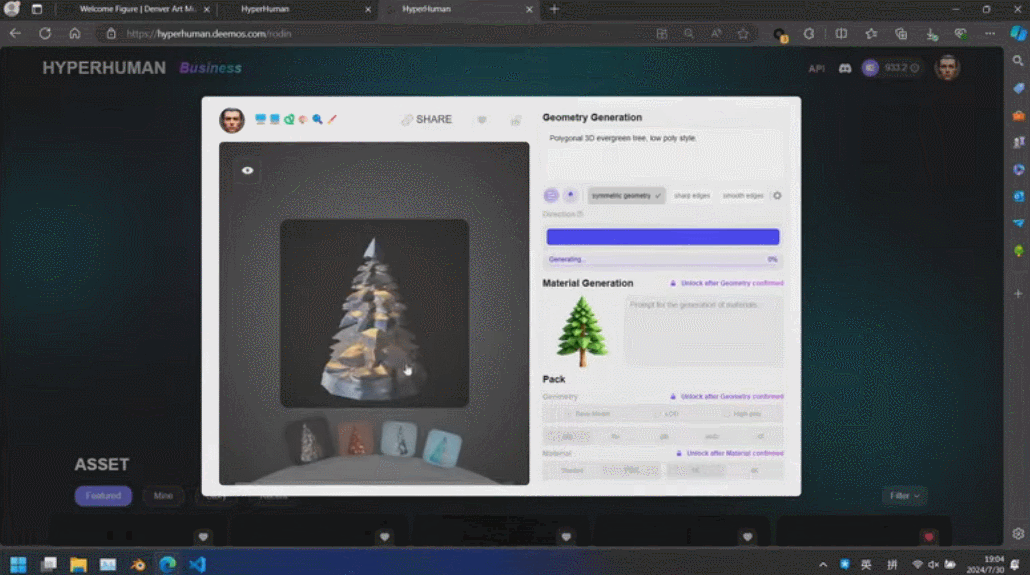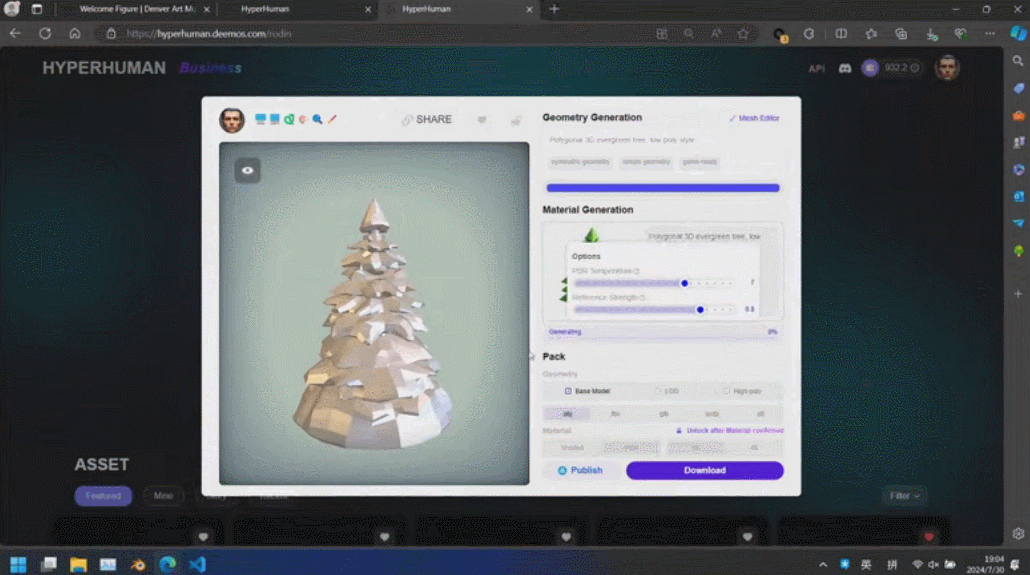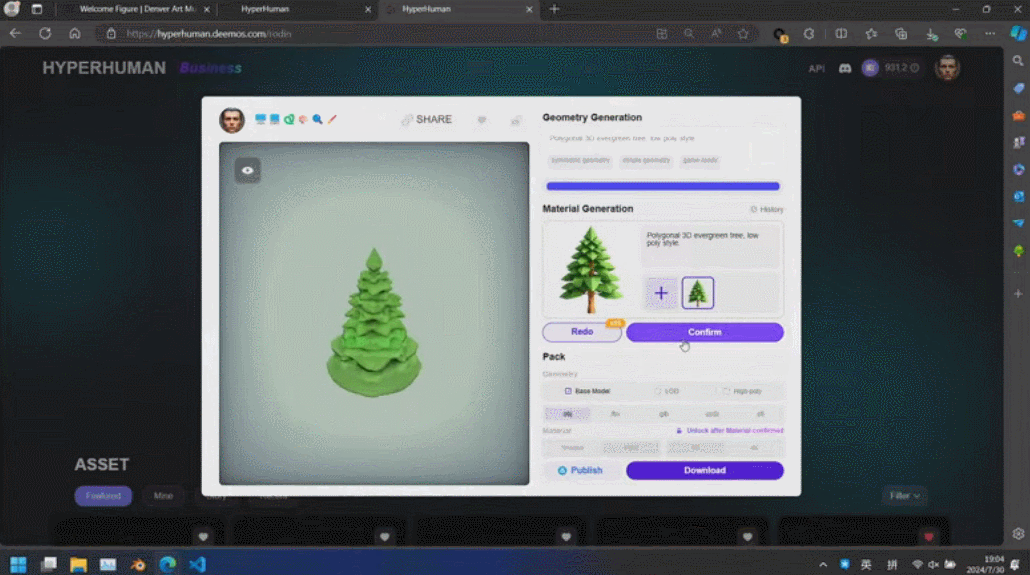
Di sebalik kandungan yang dijana ini ialah enjin AI 3D generasi baharu Rodin, yang memberi penghormatan kepada pengukir terkenal Rodin. Kandungan 3D yang dipaparkan di tapak dijana secara langsung daripada satu imej yang dimuat naik oleh pengguna, dan Rodin boleh terus menjana tekstur PBR dan permukaan segiempat untuk memudahkan pengubahsuaian dan penggunaan selanjutnya oleh artis.
 Dengan 3D ControlNet, Rodin boleh mengawal bentuk yang dijana AI. Diberikan secara ringkas sebagai panduan, elemen geometri mudah boleh ditukar kepada voxel dan diubah menjadi aset 3D yang diperlukan berdasarkan maklumat semantik imej rujukan.
Dengan 3D ControlNet, Rodin boleh mengawal bentuk yang dijana AI. Diberikan secara ringkas sebagai panduan, elemen geometri mudah boleh ditukar kepada voxel dan diubah menjadi aset 3D yang diperlukan berdasarkan maklumat semantik imej rujukan.
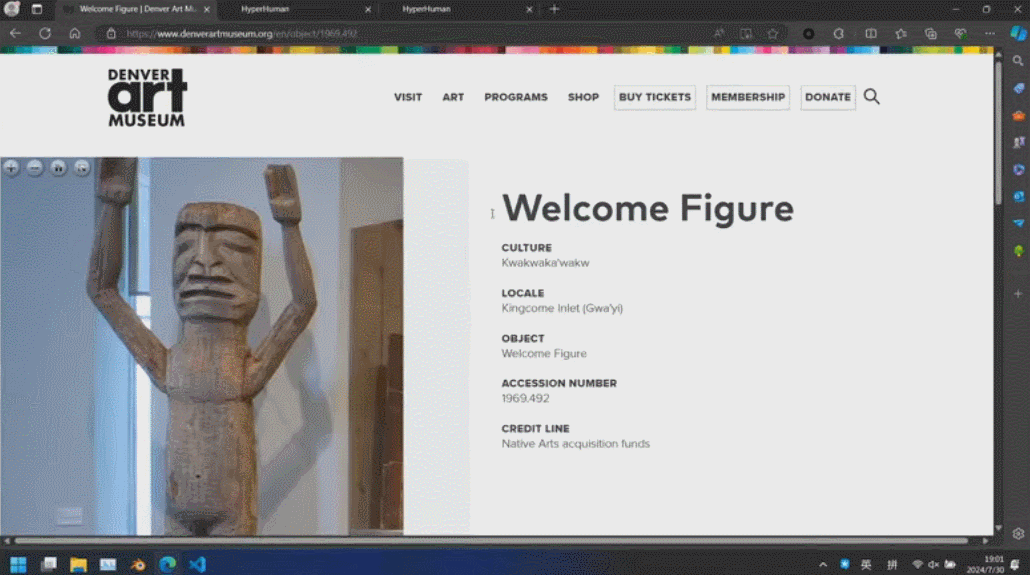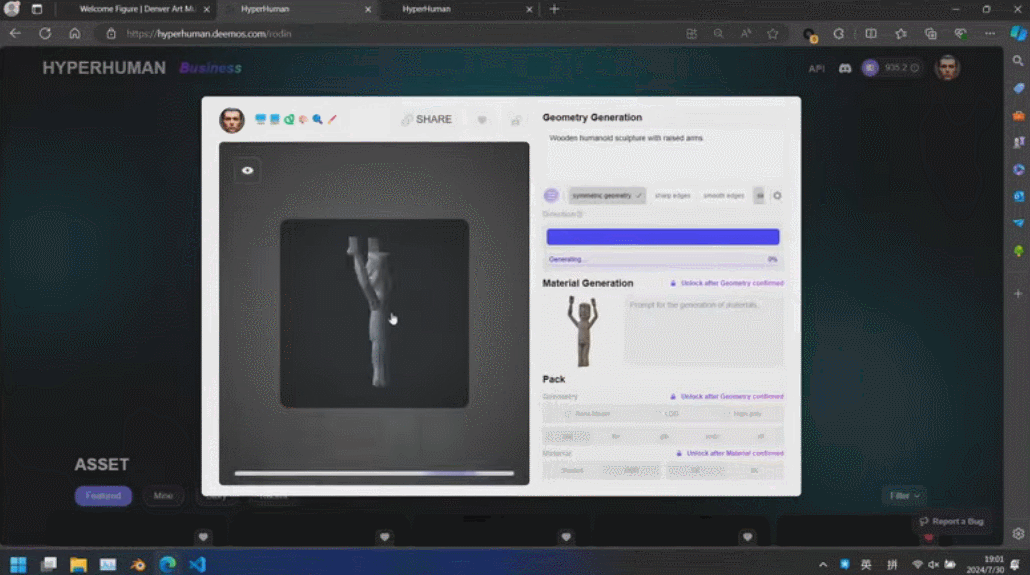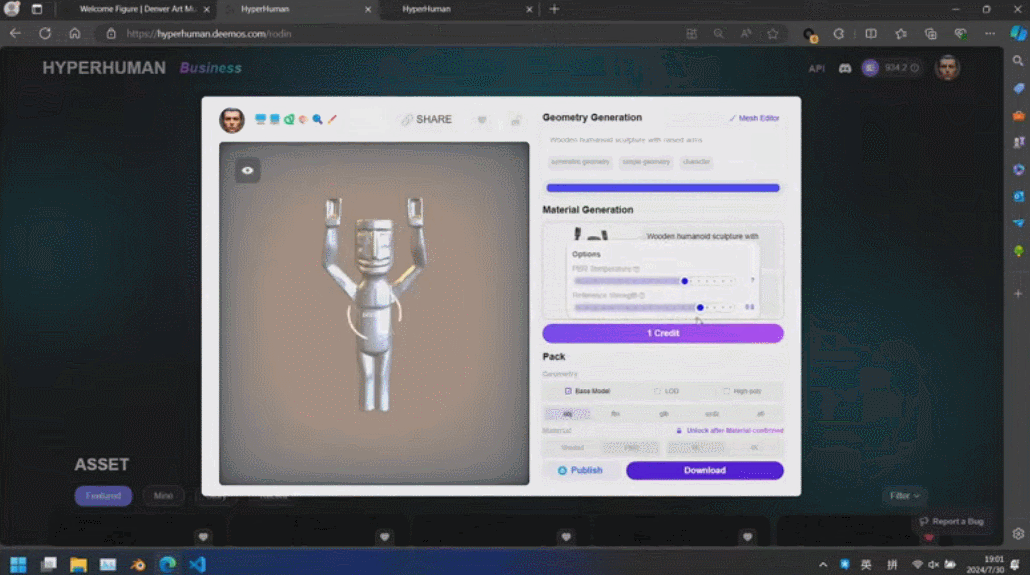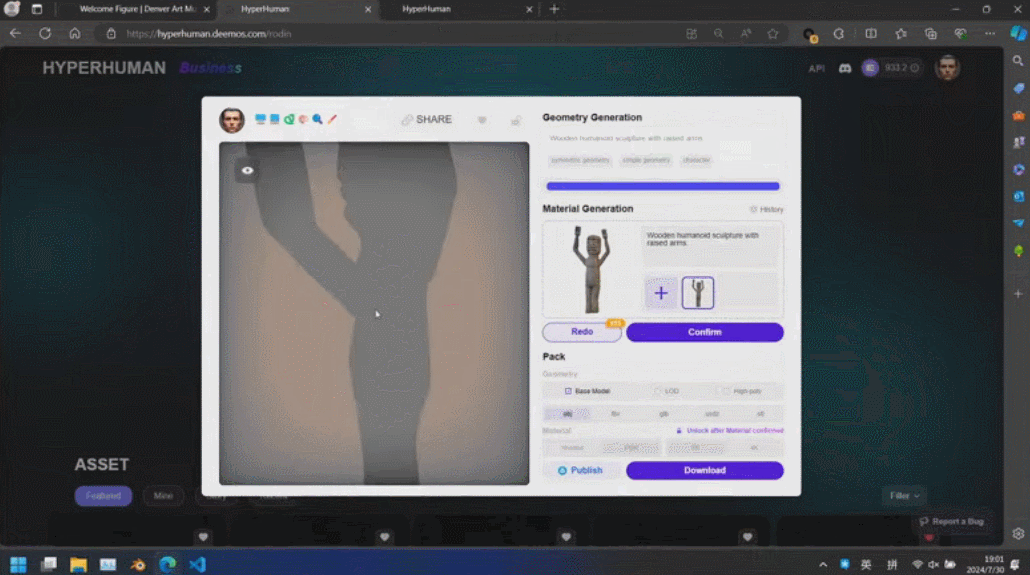 Rodin juga menyokong gambar lukisan tangan langsung, walaupun grafiti mudah. Beberapa foto telah digunakan untuk menjana aksara 3D, dan grafiti kanak-kanak menghasilkan pokok sebagai latar belakang Pembangun beroperasi di tapak dalam masa nyata, dan membina adegan pemodelan 3D yang lengkap dalam satu minit. Apabila tuan rumah bertanya siapa raksasa kecil di tengah itu, Zhang Qixuan berkata dengan lucu bahawa ini adalah AI.
Rodin juga menyokong gambar lukisan tangan langsung, walaupun grafiti mudah. Beberapa foto telah digunakan untuk menjana aksara 3D, dan grafiti kanak-kanak menghasilkan pokok sebagai latar belakang Pembangun beroperasi di tapak dalam masa nyata, dan membina adegan pemodelan 3D yang lengkap dalam satu minit. Apabila tuan rumah bertanya siapa raksasa kecil di tengah itu, Zhang Qixuan berkata dengan lucu bahawa ini adalah AI.
 Bercakap mengenainya, kali terakhir penjanaan model 3D keluar dari bulatan sebenarnya adalah pada SIGGRAPH: Pada tahun 2021, NVIDIA memperkenalkan kaedah membuat model 3D untuk Huang Renxun pada peringkat ini, mengejutkan dunia dengan palsu dan nyata kesan.
Bercakap mengenainya, kali terakhir penjanaan model 3D keluar dari bulatan sebenarnya adalah pada SIGGRAPH: Pada tahun 2021, NVIDIA memperkenalkan kaedah membuat model 3D untuk Huang Renxun pada peringkat ini, mengejutkan dunia dengan palsu dan nyata kesan.
Pada masa itu, penjanaan model 3D dianggap penting untuk teknologi seperti manusia digital dan realiti maya. Tetapi tidak syak lagi bahawa kos tinggi pengimbasan badan berketepatan tinggi + pembinaan semula pembelajaran mendalam menentukan bahawa ia ditakdirkan untuk tidak dimasukkan ke dalam pengeluaran besar-besaran.
Menggunakan penjanaan AI mungkin jalan yang lebih baik. Walau bagaimanapun, pada masa lalu, teknologi yang dicadangkan oleh orang ke arah ini sentiasa "dipuji tetapi tidak popular." 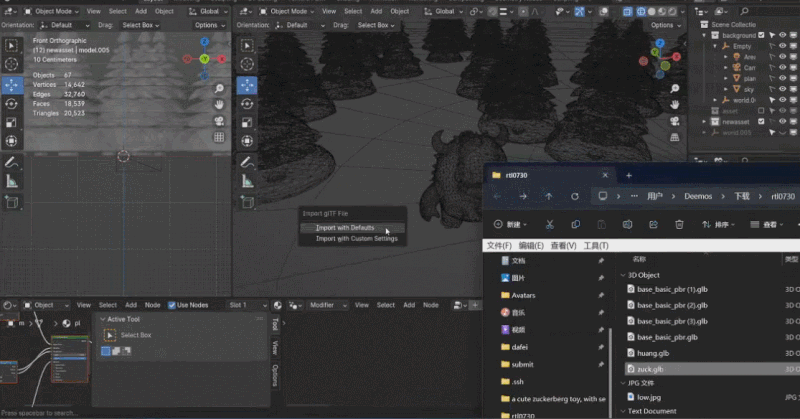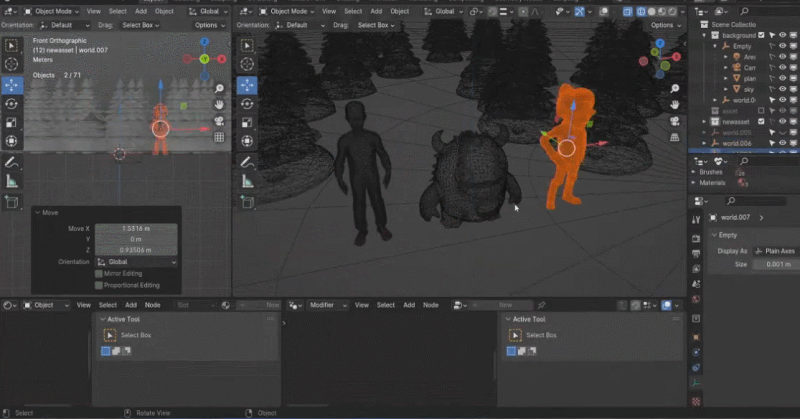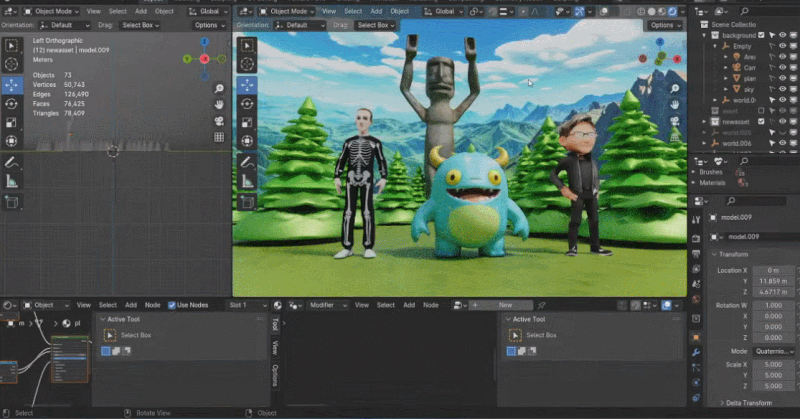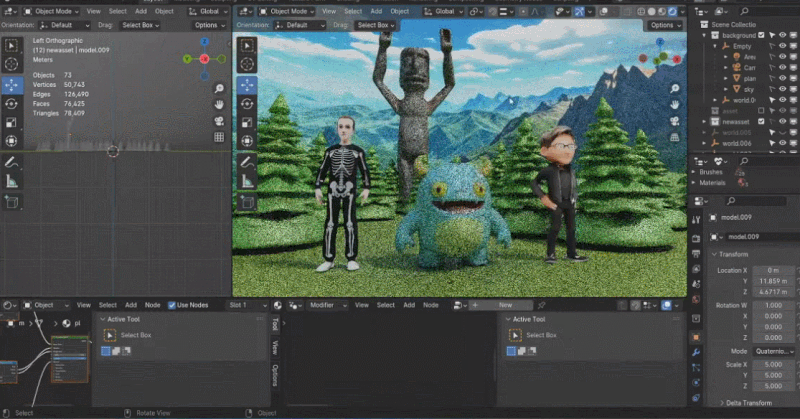
3D ialah masalah industri Tidak cukup untuk model berprestasi baik secara visual. Ia juga perlu mematuhi piawaian industri tertentu, seperti cara bahan diwakili, tampalan perancangan, Betapa munasabah strukturnya. Jika ia tidak dapat diselaraskan dengan piawaian industri manusia, hasil yang dihasilkan akan memerlukan banyak pelarasan dan sukar untuk digunakan pada pengeluaran.
Sama seperti model bahasa besar (LLM) perlu diselaraskan dengan nilai kemanusiaan, model AI yang dijana 3D perlu diselaraskan dengan piawaian industri 3D yang kompleks.
Penyelesaian yang lebih praktikal telah muncul: asli 3DSalah satu pencalonan kertas terbaik Makmal MARS Universiti Sains dan Teknologi Shanghai - CLAY telah membenarkan industri melihat penyelesaian yang boleh dilaksanakan untuk masalah di atas, iaitu 3D asli.
Kami tahu bahawa dalam dua tahun yang lalu, laluan teknikal untuk penjanaan 3D boleh dibahagikan secara kasar kepada dua kategori: peningkatan dimensi 2D dan 3D asli.
Peningkatan dimensi 2D ialah proses mencapai pembinaan semula tiga dimensi melalui model resapan 2D yang digabungkan dengan kaedah seperti NeRF. Oleh kerana mereka boleh dilatih mengenai sejumlah besar data imej 2D, model sedemikian cenderung untuk menghasilkan hasil yang pelbagai. Walau bagaimanapun, disebabkan oleh keupayaan terdahulu 3D model resapan 2D yang tidak mencukupi, model jenis ini mempunyai keupayaan terhad untuk memahami dunia 3D dan terdedah kepada menjana hasil dengan struktur geometri yang tidak munasabah (seperti manusia atau haiwan dengan berbilang kepala).

Satu siri usaha pembinaan semula berbilang paparan baru-baru ini telah mengurangkan masalah ini pada tahap tertentu dengan menambahkan imej 2D berbilang paparan aset 3D pada data latihan model penyebaran 2D. Tetapi hadnya ialah titik permulaan kaedah sedemikian ialah imej 2D, jadi mereka menumpukan pada kualiti imej yang dijana daripada cuba mengekalkan kesetiaan geometri, jadi geometri yang dihasilkan sering tidak lengkap dan kurang terperinci.
Dalam erti kata lain, data 2D hanya merekodkan satu sisi, atau unjuran, dunia sebenar Imej dari pelbagai sudut tidak dapat menerangkan sepenuhnya kandungan tiga dimensi Oleh itu, masih terdapat banyak maklumat yang hilang dalam perkara yang dipelajari oleh model. dan hasil yang dihasilkan masih Ia memerlukan banyak pengubahsuaian dan sukar untuk memenuhi piawaian industri.
Memandangkan pengehadan ini, pasukan penyelidik CLAY memilih jalan lain - asli 3D.
Laluan ini melatih model generatif terus daripada set data 3D, mengekstrak prior 3D yang kaya daripada pelbagai geometri 3D. Hasilnya, model boleh "memahami" dengan lebih baik dan mengekalkan ciri geometri.
Walau bagaimanapun, model jenis ini mestilah cukup besar untuk "muncul" dengan keupayaan penjanaan yang berkuasa, dan model yang lebih besar perlu dilatih pada set data yang lebih besar. Seperti yang kita sedia maklum, set data 3D berkualiti tinggi adalah sangat terhad dan mahal, yang merupakan masalah pertama yang mesti diselesaikan oleh laluan 3D asli.
Dalam kertas CLAY ini, penyelidik menggunakan saluran paip pemprosesan data tersuai untuk melombong berbilang set data 3D dan mencadangkan teknik yang berkesan untuk meningkatkan model generatif.
Secara khusus, proses pemprosesan data mereka bermula dengan algoritma reshing tersuai untuk menukar data 3D kepada jerat kedap air, dengan berhati-hati memelihara perkara seperti tepi keras dan permukaan rata. Selain itu, mereka memanfaatkan GPT-4V untuk mencipta anotasi terperinci yang menyerlahkan ciri geometri yang penting.
Selepas melalui proses pemprosesan di atas, banyak set data digabungkan ke dalam set data model 3D ultra-besar yang digunakan untuk latihan model CLAY. Sebelum ini, set data ini tidak pernah digunakan bersama untuk melatih model generatif 3D kerana format yang berbeza dan kekurangan konsistensi. Set data gabungan yang diproses mengekalkan perwakilan yang konsisten dan anotasi yang koheren, yang boleh meningkatkan generalisasi model generatif.
CLAY yang dilatih menggunakan set data ini mengandungi model generatif 3D dengan sehingga 1.5 bilion parameter. Untuk memastikan kehilangan maklumat daripada penukaran set data kepada ungkapan tersirat kepada output adalah sekecil mungkin, mereka menghabiskan masa yang lama untuk menapis dan menambah baik, dan akhirnya meneroka kaedah ekspresi 3D yang baharu dan cekap. Khususnya, mereka menggunakan reka bentuk medan saraf dalam 3DShape2VecSet untuk menggambarkan permukaan yang berterusan dan lengkap, dan menggabungkannya dengan VAE geometri berbilang resolusi yang direka khas untuk memproses awan titik resolusi yang berbeza, membolehkannya menyesuaikan diri dengan saiz vektor terpendam (laten saiz).

Untuk memudahkan pengembangan model, CLAY menggunakan Transformer resapan pendam minimalis (DiT). Ia terdiri daripada Transformer, boleh menyesuaikan diri dengan saiz vektor terpendam, dan mempunyai skalabiliti model yang besar. Selain itu, CLAY juga memperkenalkan skim latihan progresif dengan meningkatkan saiz vektor terpendam dan parameter model secara beransur-ansur. 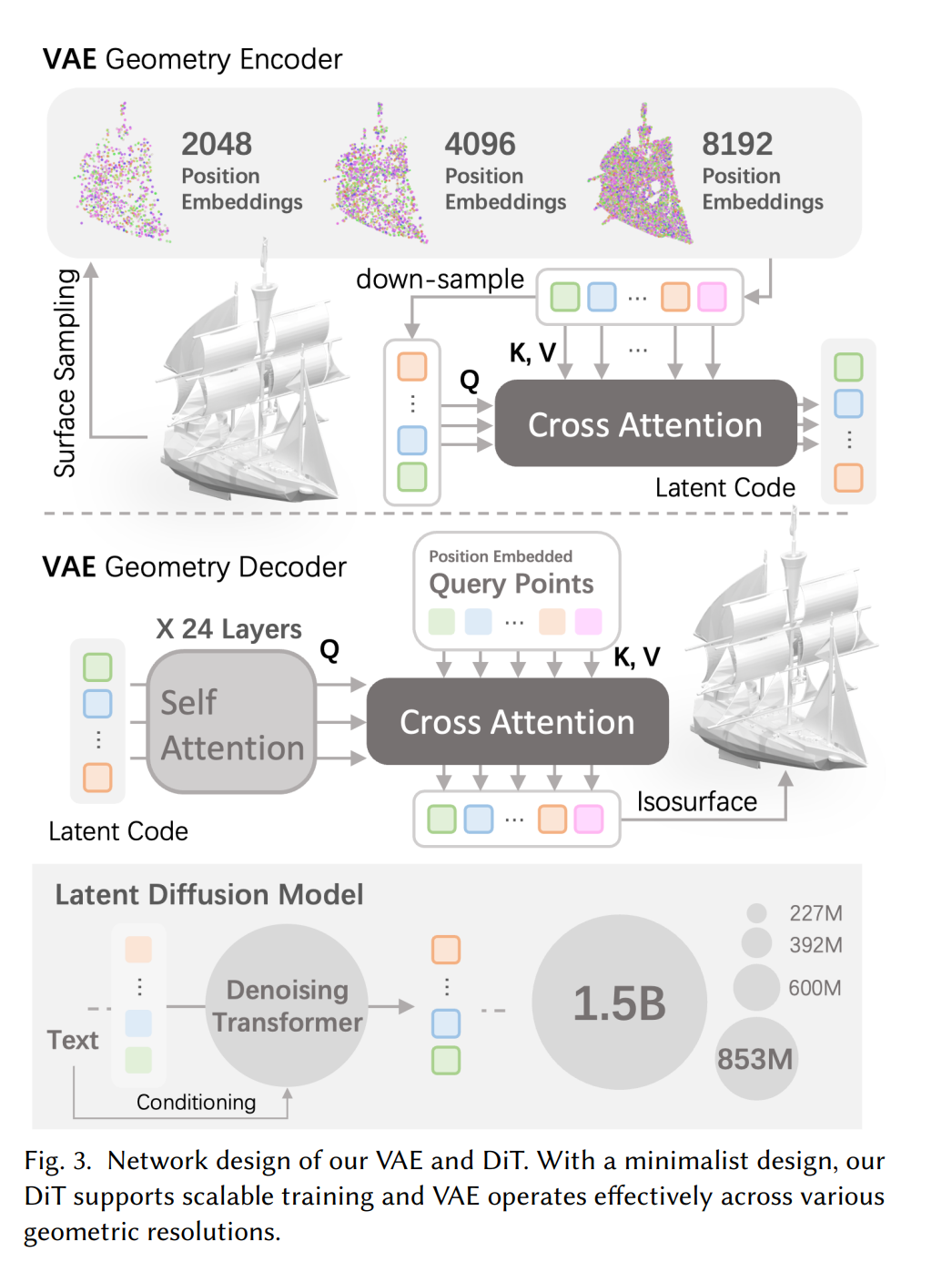
Akhir sekali, CLAY mencapai kawalan geometri yang tepat, dan pengguna boleh mengawal kerumitan, gaya, dsb. (walaupun aksara) penjanaan geometri dengan melaraskan perkataan segera. Berbanding dengan kaedah sebelumnya, CLAY dengan cepat boleh menjana geometri terperinci dan memastikan ciri-ciri geometri yang penting seperti permukaan rata dan integriti struktur.
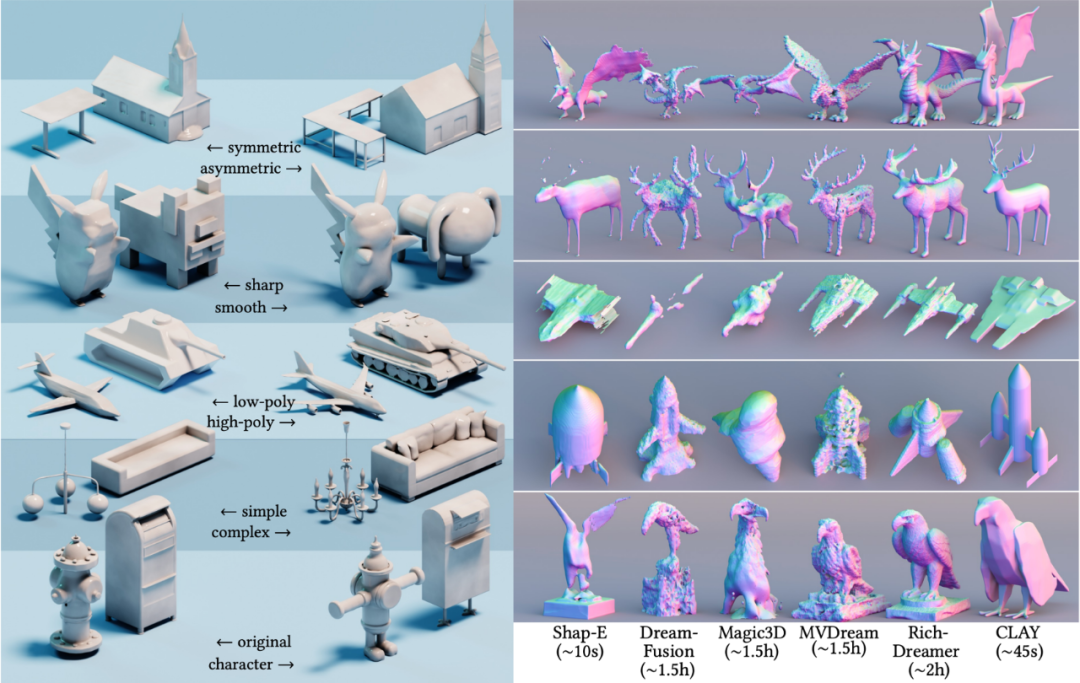
Sesetengah hasil dalam kertas kerja menunjukkan sepenuhnya kelebihan laluan 3D asli. Rajah di bawah menunjukkan tiga sampel jiran terdekat pertama yang diambil oleh penyelidik daripada set data. Geometri berkualiti tinggi yang dijana oleh CLAY sepadan dengan perkataan segera, tetapi berbeza daripada sampel dalam set data, menunjukkan kekayaan yang mencukupi dan keupayaan untuk muncul daripada model besar.

In order to enable the generated digital assets to be directly used in existing CG production pipelines, the researchers further adopted a two-stage solution:
1. Geometric optimization ensures structural integrity and compatibility while maintaining aesthetics and Functionally refine the shape of the model, such as quadrilateralization, UV expansion, etc.;
2. Material synthesis gives the model a realistic texture through real textures. Together, these steps transform a rough mesh into a more usable asset in a digital environment.
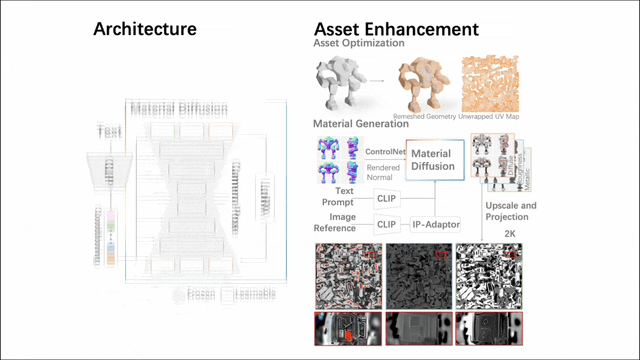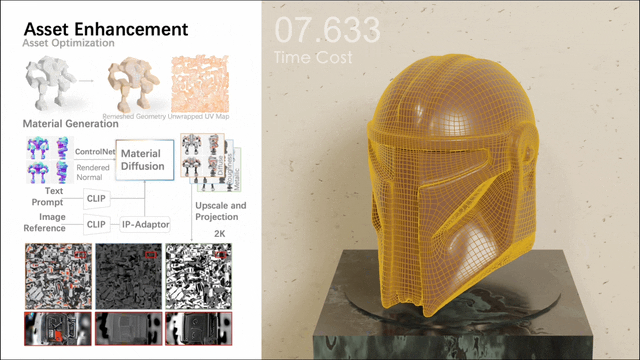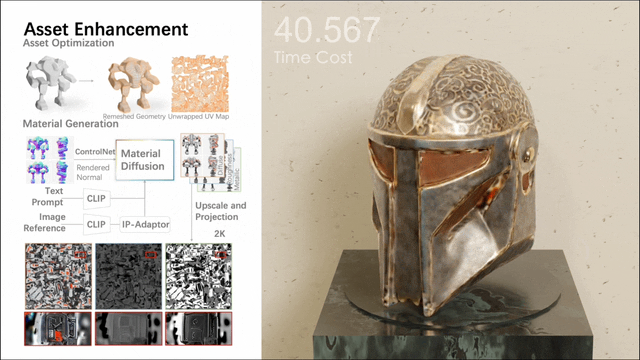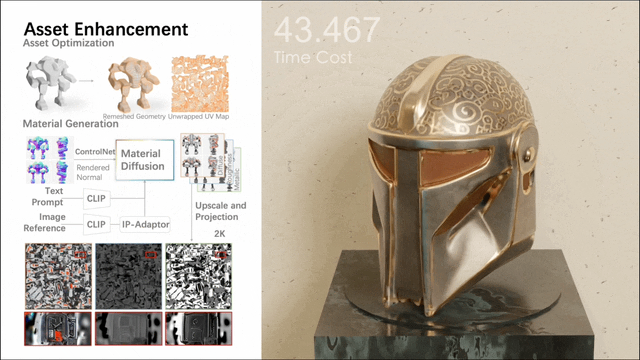
Among them, the second stage involves a multi-view material diffusion model with nearly 1 billion parameters. After mesh quadrification and UV unwrapping, it generates a PBR material via a multi-view approach, which is then back-projected onto UV maps. The model generates more realistic PBR materials than previous methods, resulting in realistic renderings.

In order to allow CLAY to support more tasks, the researchers also designed a 3D version of ControlNet. The minimalist architecture enables it to efficiently support condition control of various different modes. They implemented several example conditions that users can easily provide, including text (natively supported), as well as images/sketches, voxels, multiview images, point clouds, and bounding boxes. ) and a partial point cloud with a bounding box. These conditions can be applied individually or in combination, allowing the model to faithfully generate content based on a single condition, or combine multiple conditions to create 3D content with style and user control, offering a wide range of creative possibilities.
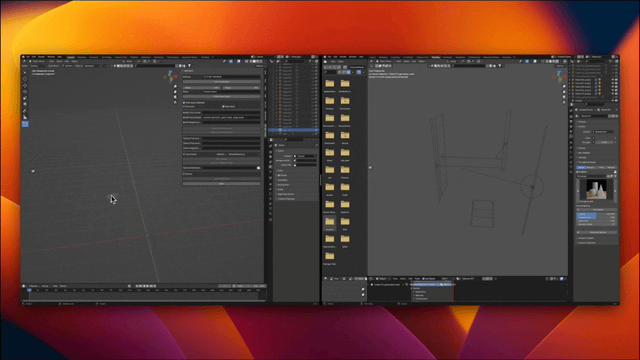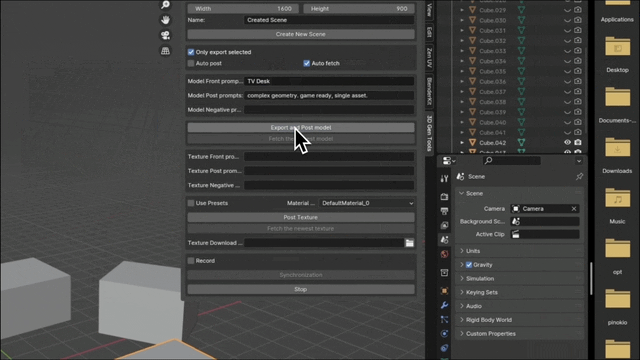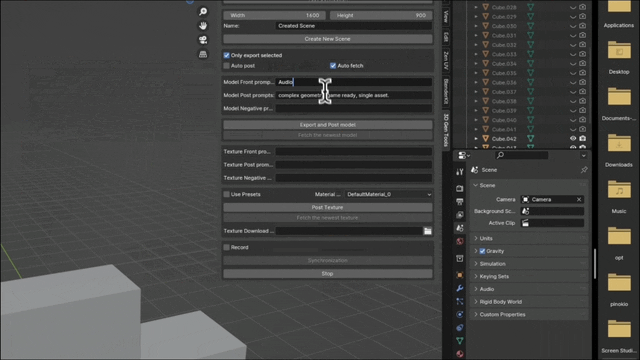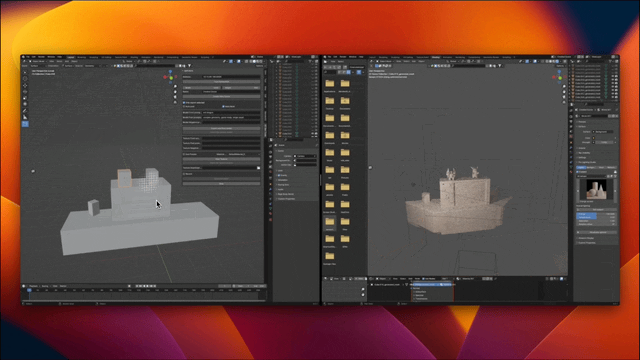
In addition, CLAY also directly supports Low-Rank Adaptation (LoRA) on DiT’s attention layers. This allows for efficient fine-tuning so that the generated 3D content can be tailored to a specific style.

It is not difficult to see from these designs that CLAY’s design has targeted application scenarios from the beginning, which is very different from some purely academic research.
This also allows the model to be implemented quickly: Rodin has now become a commonly used 3D generator for many 3D developers.文 You can click to read the original text and access the Rodin experience product (it is recommended to open the PC side).

The MARS laboratory team of Shanghai University of Science and Technology, which contributed to CLAY, became the first Chinese team to be selected for the Real-Time Live session in the 50 years since SIGGRAPH was founded in 2023. It has stood on this stage for the second consecutive year.
 Shadow Eye Technology is exploring the road of 3D native AI and building 3D products that are close to Production-Ready, significantly lowering the threshold for 3D creation.
Shadow Eye Technology is exploring the road of 3D native AI and building 3D products that are close to Production-Ready, significantly lowering the threshold for 3D creation.
CLAY-based 3D generation technology not only guides the direction of the industry, but will also play a positive role in the generation of images and videos. Because from the perspective of information entropy, the less information you provide, the greater the room for the model to play. 3D modeling can anchor the direction of convergence and improve the controllability of image and video generation.
However, the 3D field itself is not as simple as images and videos. Only by completing the complete chain will users truly begin to accept the capabilities of 3D + AI. This part of the work may be done through the partner's API, or by their team themselves. 
Dans l'attente de la poursuite de la mise en œuvre de nouvelles technologies à l'avenir.
The above is the detailed content of Two papers were nominated for the Best Paper Honorable Mention at the same time. The first Real-Time Live Chinese team at SIGGRAPH uses generative AI to create a 3D world.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
 Tested 7 'Sora-level' video generation artifacts. Who has the ability to ascend to the 'Iron Throne'?
Aug 05, 2024 pm 07:19 PM
Tested 7 'Sora-level' video generation artifacts. Who has the ability to ascend to the 'Iron Throne'?
Aug 05, 2024 pm 07:19 PM
Editor of Machine Power Report: Yang Wen Who can become the King of AI video circle? In the American TV series "Game of Thrones", there is an "Iron Throne". Legend has it that it was made by the giant dragon "Black Death" who melted thousands of swords discarded by enemies, symbolizing supreme authority. In order to sit on this iron chair, the major families started fighting and fighting. Since the emergence of Sora, a vigorous "Game of Thrones" has been launched in the AI video circle. The main players in this game include RunwayGen-3 and Luma from across the ocean, as well as domestic Kuaishou Keling, ByteDream, and Zhimo. Spectrum Qingying, Vidu, PixVerseV2, etc. Today we are going to evaluate and see who is qualified to sit on the "Iron Throne" of the AI video circle. -1- Vincent Video
