
 Technology peripherals
AI
Karpathy's views are controversial: RLHF is not real reinforcement learning, and Google and Meta are opposed to it
Technology peripherals
AI
Karpathy's views are controversial: RLHF is not real reinforcement learning, and Google and Meta are opposed to it
Karpathy's views are controversial: RLHF is not real reinforcement learning, and Google and Meta are opposed to it

Il semble que tout le monde ait encore des opinions différentes sur la question de savoir si RLHF et RL peuvent être classées dans la même catégorie. Le gourou de l'IA Karpathy est de nouveau là pour populariser le concept d'intelligence artificielle. Hier, il a tweeté : "L'apprentissage par renforcement basé sur le feedback humain (RLHF) n'est qu'un apprentissage par renforcement (RL)."

RLHF est la troisième méthode de formation de grands modèles de langage (LLM). Il y a trois (et dernières) étapes principales, les deux premières étapes sont la pré-formation et le réglage fin supervisé (SFT). Je pense que le RLHF est à peine un RL, il n'est pas largement reconnu. RL est puissant, mais RLHF ne l’est pas.
Regardons l'exemple d'AlphaGo, qui a été formé à l'aide d'un vrai RL. L'ordinateur jouait au jeu de Go et était entraîné sur des tours qui maximisaient la fonction de récompense (gagner la partie), surpassant finalement les meilleurs joueurs humains. AlphaGo n’a pas été formé à l’aide du RLHF, et si c’était le cas, il ne serait pas aussi efficace.
À quoi cela ressemblerait-il d'entraîner AlphaGo avec RLHF ? Tout d'abord, vous donnez aux annotateurs humains deux états du tableau Go et leur demandez lequel ils préfèrent :

Vous collecterez ensuite 100 000 comparaisons similaires et entraînerez un réseau neuronal de « modèle de récompense » (RM) pour simuler une vérification par vibration humaine de l'état de la carte. Vous l’entraînez à être d’accord avec le jugement humain moyen. Une fois que nous avons vérifié l'ambiance du modèle bonus, vous pouvez exécuter RL contre cela et apprendre à effectuer des mouvements qui apportent de bonnes vibrations. Évidemment, cela ne produit pas de résultats très intéressants en Go.
Cela s'explique principalement par deux raisons fondamentales et indépendantes :
1) L'ambiance peut être trompeuse, ce qui n'est pas la véritable récompense (gagner la partie). C’est un mauvais objectif d’agent. Pire encore, 2) vous constaterez que votre optimisation RL déraille car elle découvre rapidement que l'état du tableau est opposé au modèle de récompense. N'oubliez pas que le modèle de récompense est un réseau neuronal massif utilisant des milliards de paramètres pour simuler l'atmosphère. Certains états du conseil d'administration se situent en dehors de la plage de distribution de leurs propres données de formation et ne sont pas réellement de bons états, mais reçoivent des récompenses très élevées du modèle de récompense.
Pour la même raison, je suis parfois surpris que le travail du RLHF fonctionne pour le LLM. Le modèle de récompense que nous avons formé pour LLM effectue simplement la vérification des vibrations exactement de la même manière, en attribuant des scores élevés aux réponses de l'assistant que les évaluateurs humains semblent statistiquement apprécier. Ce n’est pas le but réel de résoudre le problème correctement, mais le but de ce que les humains pensent être bon en tant qu’agent.
Deuxièmement, vous ne pouvez même pas exécuter RLHF très longtemps car votre modèle apprend rapidement à réagir de manière à ce que le jeu le récompense. Ces prédictions auront l'air vraiment bizarres, et vous verrez votre assistant LLM commencer à répondre à de nombreuses invites avec des réponses dénuées de sens comme "Le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le Cela vous semble ridicule, mais ensuite vous regardez les contrôles d'ambiance du modèle bonus et vous réalisez que, pour une raison quelconque, le modèle bonus les trouve superbes.
Votre LLM a trouvé un exemple contradictoire qui se situe en dehors de la plage des données de formation du modèle de récompense et se situe dans une plage indéfinie. Vous pouvez atténuer ce problème en ajoutant ces exemples spécifiques à l'ensemble de formation à plusieurs reprises, tout en trouvant d'autres exemples contradictoires la prochaine fois. Vous ne pouvez même pas exécuter RLHF pour de nombreuses étapes d'optimisation. Vous devez l'appeler après quelques centaines ou milliers d'étapes, car votre optimisation commencera à jouer sur le modèle de récompense. Ce n'est pas RL comme AlphaGo.
Cependant, le RLHF est une étape très utile dans la construction d'un assistant LLM. Je pense qu'il y a plusieurs raisons subtiles à cela, dont ma préférée est qu'avec RLHF, l'assistant LLM bénéficie de l'écart générateur-discriminateur. Autrement dit, pour de nombreux types de questions, il est beaucoup plus facile pour un annotateur humain de sélectionner la meilleure réponse parmi plusieurs réponses candidates que d'écrire la réponse idéale à partir de zéro. Un bon exemple est une invite telle que « Générer un poème avec un trombone ». Un annotateur humain moyen aurait du mal à écrire un bon poème à partir de zéro pour l'utiliser comme exemple de mise au point supervisée, mais pourrait en choisir un meilleur étant donné plusieurs réponses candidates (poèmes). Le RLHF est donc un moyen de bénéficier du manque de « facilité » de la supervision humaine.
Il existe d'autres raisons pour lesquelles le RLHF aide à soulager les hallucinations. Si le modèle de récompense est un modèle suffisamment puissant pour repérer ce que le LLM invente pendant la formation, il peut apprendre à punir ce comportement avec de faibles récompenses, en apprenant au modèle à éviter de prendre des risques pour acquérir des connaissances factuelles lorsqu'elles sont incertaines. Mais le soulagement et la gestion satisfaisante des hallucinations sont une autre affaire et ne seront pas développés ici. En conclusion, RLHF fonctionne, mais ce n'est pas RL.
Jusqu'à présent, aucun RL de qualité production pour LLM n'a été implémenté et démontré de manière convaincante à grande échelle dans le domaine ouvert. Intuitivement, cela est dû au fait qu’il est très difficile d’obtenir des récompenses réelles (c’est-à-dire gagner la partie) dans des tâches ouvertes de résolution de problèmes. Dans un environnement fermé et ludique comme Go, tout est amusant. La dynamique est limitée, le coût d'évaluation de la fonction de récompense est très faible et le jeu est impossible.
Mais comment offrir une récompense objective pour la synthèse d’un article ? Ou répondre à une question ambiguë sur une certaine installation de pip ? Ou raconter une blague ? Ou réécrire du code Java en Python ? Y parvenir n’est pas impossible en principe, mais ce n’est pas facile et nécessite une certaine réflexion créative. Celui qui résoudra ce problème de manière convaincante sera capable d'exécuter un véritable RL, permettant à AlphaGo de battre les humains au Go. Avec RL, LLM a le potentiel de véritablement battre les humains dans la résolution de problèmes de domaine ouvert.
Le point de vue de Karpathy a été repris par certains qui ont souligné davantage de différences entre RLHF et RL. Par exemple, RLHF n'effectue pas de recherche appropriée et apprend principalement à utiliser un sous-ensemble de trajectoires pré-entraînées. En revanche, lors d'une RL appropriée, les distributions d'actions discrètes sont souvent bruitées en ajoutant un terme d'entropie à la fonction de perte. Kaypathy a fait valoir qu'en principe, vous pourriez facilement ajouter des récompenses d'entropie aux objectifs du RLHF, ce qui est également souvent fait dans le RL. Mais en réalité, cela semble rare.
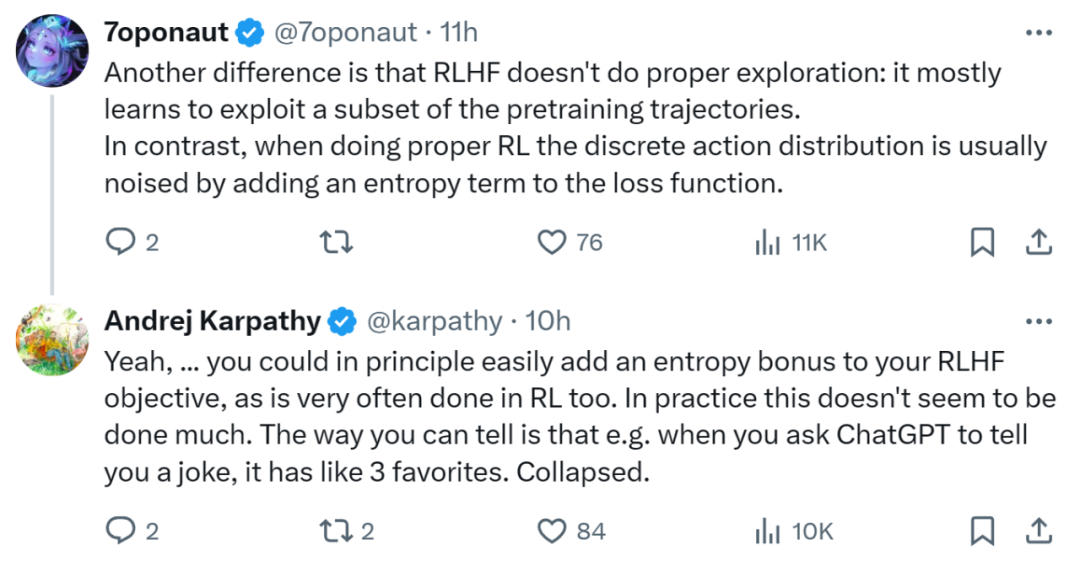
- He believes that RLHF is more like a context "bandit" with string value operations, where prompt is the context, so it cannot be called a complete RL.
- Also formalizing the rewards for daily tasks is the hard part (he thinks it might be called alignment).
However, Natasha Jaques, another senior research scientist at Google, thinks Karpathy is wrong. She believes that when agent interacts with people, giving answers that humans like is the real goal.
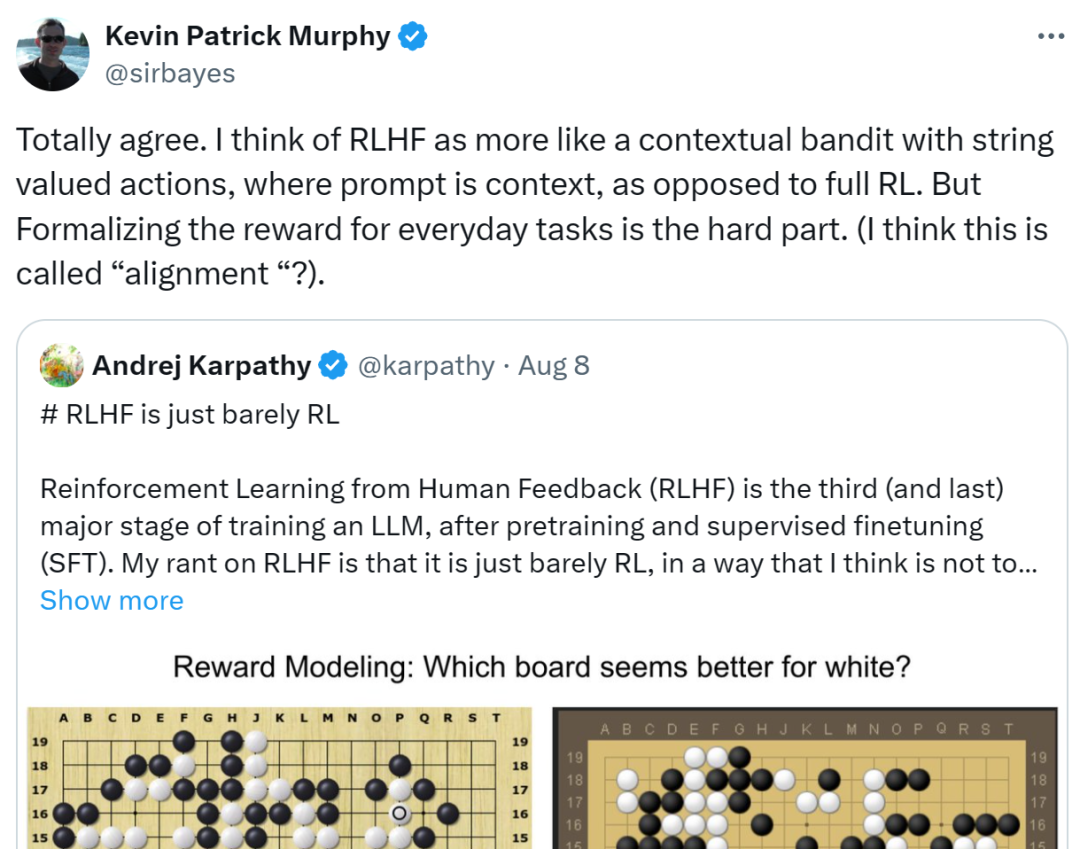
Out-of-distribution range is not a problem unique to RLHF. Just because human feedback is more constrained than running an infinite Go simulation doesn't mean it's not a problem worth solving, it just makes it a more challenging one. She hopes this becomes a more impactful issue, after all reducing bias in LLM makes more sense than beating humans at Go. Using derogatory terms like Karpathy saying the bonus model is a vibe check is silly. You can use the same argument against value estimates.
She feels that Karpathy's views will only serve to deter people from pursuing RLHF work, when it is currently the only viable way to mitigate the serious harm that LLM bias and illusion can cause.
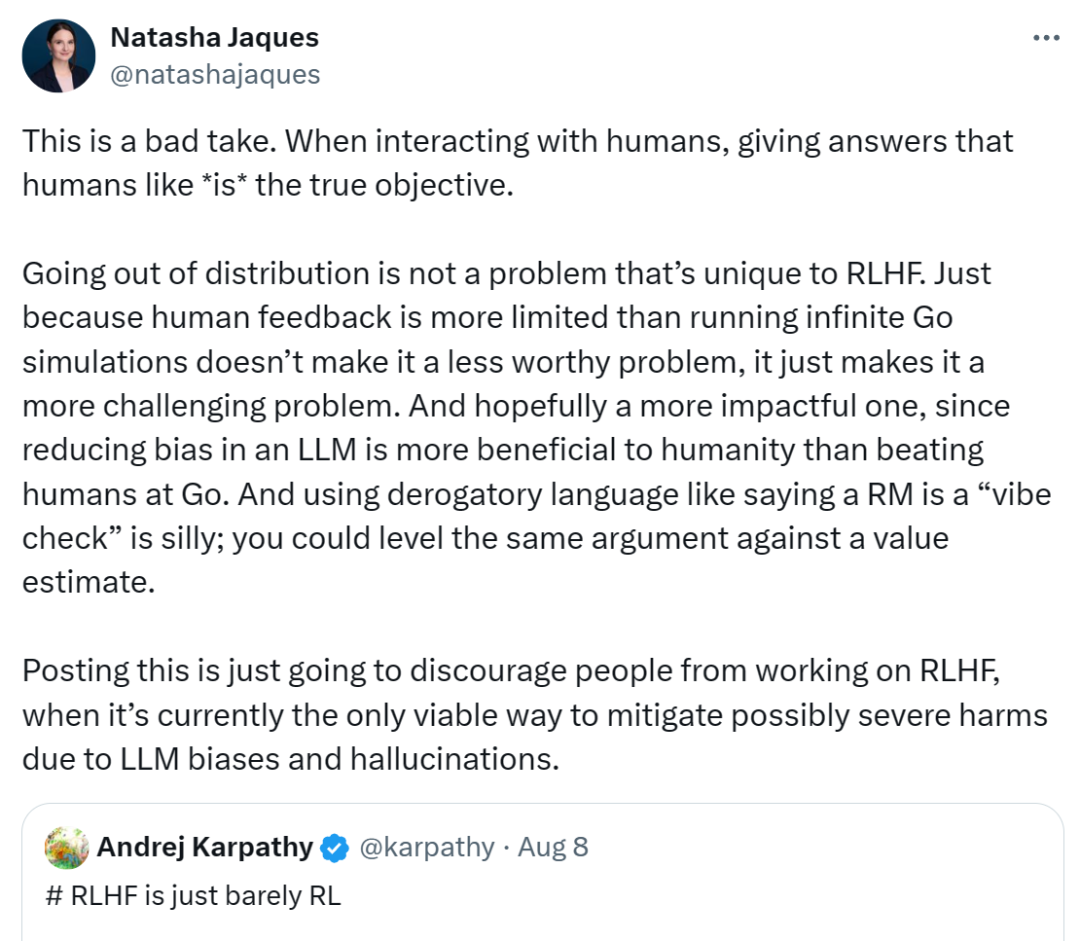
Meta researcher Pierluca D'Oro disagrees with Karpathy's main point, but agrees that "RLHF is just barely RL" This title. He argued that RLHF, which is commonly used to fine-tune LLM, is hardly RL.
The main points are as follows:
- In reinforcement learning, it is unrealistic to pursue a "perfect reward" concept, because in most complex tasks, in addition to the importance of the goal, the execution method is equally important.
- Although in tasks with clear rules such as Go, RL performs well. But when it comes to complex behaviors, the reward mechanism of traditional RL may not be able to meet the needs.
- He advocates studying how to improve the performance of RL under imperfect reward models, and emphasizes the importance of feedback loops, robust RL mechanisms, and human-machine collaboration.
Picture source: https://x.com/proceduralia/status/1821560990091128943 Whose view do you agree with? Welcome to leave a message in the comment area.

The above is the detailed content of Karpathy's views are controversial: RLHF is not real reinforcement learning, and Google and Meta are opposed to it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1242
24
14
1423
52
1317
25
1268
29
1242
24

 Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
In modern manufacturing, accurate defect detection is not only the key to ensuring product quality, but also the core of improving production efficiency. However, existing defect detection datasets often lack the accuracy and semantic richness required for practical applications, resulting in models unable to identify specific defect categories or locations. In order to solve this problem, a top research team composed of Hong Kong University of Science and Technology Guangzhou and Simou Technology innovatively developed the "DefectSpectrum" data set, which provides detailed and semantically rich large-scale annotation of industrial defects. As shown in Table 1, compared with other industrial data sets, the "DefectSpectrum" data set provides the most defect annotations (5438 defect samples) and the most detailed defect classification (125 defect categories
 Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Editor |KX To this day, the structural detail and precision determined by crystallography, from simple metals to large membrane proteins, are unmatched by any other method. However, the biggest challenge, the so-called phase problem, remains retrieving phase information from experimentally determined amplitudes. Researchers at the University of Copenhagen in Denmark have developed a deep learning method called PhAI to solve crystal phase problems. A deep learning neural network trained using millions of artificial crystal structures and their corresponding synthetic diffraction data can generate accurate electron density maps. The study shows that this deep learning-based ab initio structural solution method can solve the phase problem at a resolution of only 2 Angstroms, which is equivalent to only 10% to 20% of the data available at atomic resolution, while traditional ab initio Calculation
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
For AI, Mathematical Olympiad is no longer a problem. On Thursday, Google DeepMind's artificial intelligence completed a feat: using AI to solve the real question of this year's International Mathematical Olympiad IMO, and it was just one step away from winning the gold medal. The IMO competition that just ended last week had six questions involving algebra, combinatorics, geometry and number theory. The hybrid AI system proposed by Google got four questions right and scored 28 points, reaching the silver medal level. Earlier this month, UCLA tenured professor Terence Tao had just promoted the AI Mathematical Olympiad (AIMO Progress Award) with a million-dollar prize. Unexpectedly, the level of AI problem solving had improved to this level before July. Do the questions simultaneously on IMO. The most difficult thing to do correctly is IMO, which has the longest history, the largest scale, and the most negative
 PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
In 2023, almost every field of AI is evolving at an unprecedented speed. At the same time, AI is constantly pushing the technological boundaries of key tracks such as embodied intelligence and autonomous driving. Under the multi-modal trend, will the situation of Transformer as the mainstream architecture of AI large models be shaken? Why has exploring large models based on MoE (Mixed of Experts) architecture become a new trend in the industry? Can Large Vision Models (LVM) become a new breakthrough in general vision? ...From the 2023 PRO member newsletter of this site released in the past six months, we have selected 10 special interpretations that provide in-depth analysis of technological trends and industrial changes in the above fields to help you achieve your goals in the new year. be prepared. This interpretation comes from Week50 2023
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
Editor | KX Retrosynthesis is a critical task in drug discovery and organic synthesis, and AI is increasingly used to speed up the process. Existing AI methods have unsatisfactory performance and limited diversity. In practice, chemical reactions often cause local molecular changes, with considerable overlap between reactants and products. Inspired by this, Hou Tingjun's team at Zhejiang University proposed to redefine single-step retrosynthetic prediction as a molecular string editing task, iteratively refining the target molecular string to generate precursor compounds. And an editing-based retrosynthetic model EditRetro is proposed, which can achieve high-quality and diverse predictions. Extensive experiments show that the model achieves excellent performance on the standard benchmark data set USPTO-50 K, with a top-1 accuracy of 60.8%.
 Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Editor | ScienceAI Based on limited clinical data, hundreds of medical algorithms have been approved. Scientists are debating who should test the tools and how best to do so. Devin Singh witnessed a pediatric patient in the emergency room suffer cardiac arrest while waiting for treatment for a long time, which prompted him to explore the application of AI to shorten wait times. Using triage data from SickKids emergency rooms, Singh and colleagues built a series of AI models that provide potential diagnoses and recommend tests. One study showed that these models can speed up doctor visits by 22.3%, speeding up the processing of results by nearly 3 hours per patient requiring a medical test. However, the success of artificial intelligence algorithms in research only verifies this
