
 Backend Development
Python Tutorial
Crawling Pages with Infinite Scroll using Scrapy and Playwright
Backend Development
Python Tutorial
Crawling Pages with Infinite Scroll using Scrapy and Playwright
Crawling Pages with Infinite Scroll using Scrapy and Playwright

When crawling websites with Scrapy you'll quickly come across all sorts of scenarios that require you to get creative or interact with the page that you're trying to scrape. One of these scenarios is when you need to crawl an infinite scroll page. This type of website page loads more content as you scroll down the page like a social media feed.
There is definitely more than one way to crawl these types of pages. One way I recently approached this was to continue scrolling until the page length stopped increasing (i.e. scroll to the bottom). This post steps through this process.
This post assumes that you have a Scrapy project set up, running, and a Spider that you can modify and run.
Using Playwright with Scrapy
This integration uses the scrapy-playwright plugin to integrate Playwright for Python with Scrapy. Playwright is a headless browser automation library used to interact with web pages and extract data.
I've been using uv for Python package installation and management.
Then, I use virtual environments right from uv with:
uv venv source .venv/bin/activate
Install the scrapy-playwright plugin and Playwright with the following command into your virtual environment:
uv pip install scrapy-playwright
Install the browser you want to use with Playwright. For example, to install Chromium, you can run the following command:
playwright install chromium
You can also install other browsers like Firefox if needed.
Note: The below Scrapy code and Playwright integration have only been tested with Chromium.
Update the settings.py file or the custom_settings attribute in the spider to include the DOWNLOAD_HANDLERS and PLAYWRIGHT_LAUNCH_OPTIONS settings.
# settings.py
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_LAUNCH_OPTIONS = {
# optional for CORS issues
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
# optional for debugging
"headless": False,
},
For PLAYWRIGHT_LAUNCH_OPTIONS you can set the headless option to False to have the browser instance open and watch the process run. This is good for debugging and building out the initial scraper.
Dealing with CORS Issues
I pass in the additional args to disable web security and isolate origins. This is useful when you are crawling sites that have CORS issues.
For example, there may be situations when required JavaScript assets are not loaded or network requests are not made because of CORS. You can isolate this faster by checking the browser console for errors if certain page actions (like clicking a button) are not working as expected but everything else is.
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
}
Crawling Infinite Scroll Pages
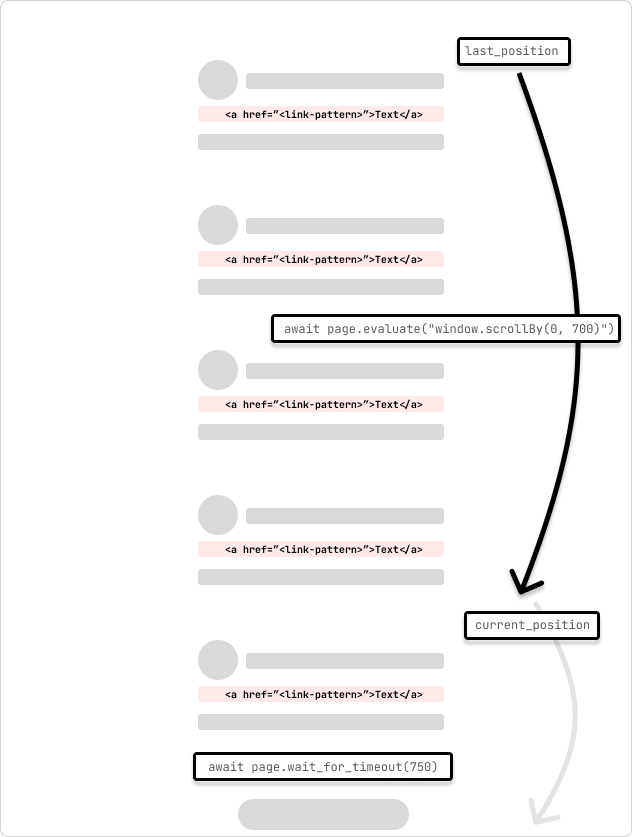
This is an example of a spider that crawls an infinite scroll page. The spider scrolls the page by 700 pixels and waits for 750ms for the request to complete. The spider will continue to scroll until it reaches the bottom of the page indicated by the the scroll position not changing as it goes through the loop.
I'm modifying the settings in the spider itself using custom_settings to keep the settings in one place. You can also add these settings to the settings.py file.
# /<project>/spiders/infinite_scroll.py
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
class InfinitePageSpider(CrawlSpider):
"""
Spider to crawl an infinite scroll page
"""
name = "infinite_scroll"
allowed_domains = ["<allowed_domain>"]
start_urls = ["<start_url>"]
custom_settings = {
"TWISTED_REACTOR": "twisted.internet.asyncioreactor.AsyncioSelectorReactor",
"DOWNLOAD_HANDLERS": {
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
},
"LOG_LEVEL": "INFO",
}
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
async def parse(
self,
response,
):
page = response.meta["playwright_page"]
page.set_default_timeout(10000)
await page.wait_for_timeout(5000)
try:
last_position = await page.evaluate("window.scrollY")
while True:
# scroll by 700 while not at the bottom
await page.evaluate("window.scrollBy(0, 700)")
await page.wait_for_timeout(750) # wait for 750ms for the request to complete
current_position = await page.evaluate("window.scrollY")
if current_position == last_position:
print("Reached the bottom of the page.")
break
last_position = current_position
except Exception as error:
print(f"Error: {error}")
pass
print("Getting content")
content = await page.content()
print("Parsing content")
selector = Selector(text=content)
print("Extracting links")
links = selector.xpath("//a[contains(@href, '/<link-pattern>/')]//@href").getall()
print(f"Found {len(links)} links...")
print("Yielding links")
for link in links:
yield {"link": link}
One thing that I've learned is that no two pages or sites are the same so you may need to adjust the scroll amount and wait time to account for the page and also any latency in the network round trips for the requests to complete. You can dynamically adjust this programmatically by checking the scroll position and the time it takes for the request to complete.
On the page load, I'm waiting a bit longer for the assets to load and the page to render. The Playwright page is passed to the parse callback method in the response.meta object. This is used to interact with the page and scroll the page. This is specified in the scrapy.Request arguments with the playwright=True and playwright_include_page=True options.
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
This spider will scroll the page with page.evaluate and the scrollBy() JavaScript method by 700 pixels and then wait for 750ms for the request to complete. Then, the Playwright page content is copied to a Scrapy selector, and extract the links from the page. The links are then yielded to the Scrapy pipeline to continue processing.
For situations where the page requests begin to load duplicate content, you can add a check to see if the content has already been loaded and then break out of the loop. Or, if you have an idea of the number of scroll loads, you can add a counter to break out of the loop after a certain number of scrolls plus/minus a buffer.
Infinite Scroll with an Element Click
It's also possible that the page may have an element that you can scroll to (i.e. "Load more") that will trigger the next set of content to load. You can use the page.evaluate method to scroll to the element and then click it to load the next set of content.
...
try:
while True:
button = page.locator('//button[contains(., "Load more")]')
await button.wait_for()
if not button:
print("No 'Load more' button found.")
break
is_disabled = await button.is_disabled()
if is_disabled:
print("Button is disabled.")
break
await button.scroll_into_view_if_needed()
await button.click()
await page.wait_for_timeout(750)
except Exception as error:
print(f"Error: {error}")
pass
...
This method is useful when you know the page has a button that will load the next set of content. You can also use this method to click on other elements that will trigger the next set of content to load. The scroll_into_view_if_needed method will scroll the button or element into view if it is not already visible on the page. This is one of those scenarios when you will want to double-check the page actions with headless=False to see if the button is being clicked and the content is being loaded as expected before running a full crawl.
Note: As mentioned above, confirm that the page assets(.js) are loading correctly and that the network requests are being made so that the button (or element) is mounted and clickable.
Wrapping Up
Web crawling is a case-by-case scenario and you will need to adjust the code to fit the page that you are trying to scrape. The above code is a starting point to get you going with crawling infinite scroll pages with Scrapy and Playwright.
Hopefully, this helps to get you unblocked! ?
Subscribe to get my latest content by email -> Newsletter
The above is the detailed content of Crawling Pages with Infinite Scroll using Scrapy and Playwright. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1243
24
14
1423
52
1317
25
1268
29
1243
24

 Python vs. C : Applications and Use Cases Compared
Apr 12, 2025 am 12:01 AM
Python vs. C : Applications and Use Cases Compared
Apr 12, 2025 am 12:01 AM
Python is suitable for data science, web development and automation tasks, while C is suitable for system programming, game development and embedded systems. Python is known for its simplicity and powerful ecosystem, while C is known for its high performance and underlying control capabilities.
 Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python excels in gaming and GUI development. 1) Game development uses Pygame, providing drawing, audio and other functions, which are suitable for creating 2D games. 2) GUI development can choose Tkinter or PyQt. Tkinter is simple and easy to use, PyQt has rich functions and is suitable for professional development.
 The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
You can learn basic programming concepts and skills of Python within 2 hours. 1. Learn variables and data types, 2. Master control flow (conditional statements and loops), 3. Understand the definition and use of functions, 4. Quickly get started with Python programming through simple examples and code snippets.
 Python vs. C : Learning Curves and Ease of Use
Apr 19, 2025 am 12:20 AM
Python vs. C : Learning Curves and Ease of Use
Apr 19, 2025 am 12:20 AM
Python is easier to learn and use, while C is more powerful but complex. 1. Python syntax is concise and suitable for beginners. Dynamic typing and automatic memory management make it easy to use, but may cause runtime errors. 2.C provides low-level control and advanced features, suitable for high-performance applications, but has a high learning threshold and requires manual memory and type safety management.
 How Much Python Can You Learn in 2 Hours?
Apr 09, 2025 pm 04:33 PM
How Much Python Can You Learn in 2 Hours?
Apr 09, 2025 pm 04:33 PM
You can learn the basics of Python within two hours. 1. Learn variables and data types, 2. Master control structures such as if statements and loops, 3. Understand the definition and use of functions. These will help you start writing simple Python programs.
 Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
To maximize the efficiency of learning Python in a limited time, you can use Python's datetime, time, and schedule modules. 1. The datetime module is used to record and plan learning time. 2. The time module helps to set study and rest time. 3. The schedule module automatically arranges weekly learning tasks.
 Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
Python is widely used in the fields of web development, data science, machine learning, automation and scripting. 1) In web development, Django and Flask frameworks simplify the development process. 2) In the fields of data science and machine learning, NumPy, Pandas, Scikit-learn and TensorFlow libraries provide strong support. 3) In terms of automation and scripting, Python is suitable for tasks such as automated testing and system management.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
