Hybrid experts also have specializations in the field of surgery.
For the current mixed-modality basic model, the common architectural design is to fuse the encoder or decoder of a specific modality, but this method has limitations: it cannot integrate information from different modalities, and it is difficult to output. Contains content in multiple modalities. In order to overcome this limitation, the Chameleon team of Meta FAIR proposed a new single Transformer architecture in the recent paper "Chameleon: Mixed-modal early-fusion foundation models", which can be based on the next token. The prediction goal is to model mixed-modal sequences composed of discrete image and text tokens, allowing for seamless inference and generation between different modalities. 
After completing pre-training on approximately 10 trillion mixed-modal tokens, Chameleon has demonstrated a wide range of visual and language capabilities and can handle a variety of different downstream tasks well. Chameleon's performance is particularly impressive in the task of generating mixed-modal long answers. It even beats commercial models such as Gemini 1.0 Pro and GPT-4V. However, for a model like Chameleon where various modalities are mixed in the early stages of model training, expanding its capabilities requires investing a lot of computing power. Based on the above problems, the Meta FAIR team conducted some research and exploration on routed sparse architecture and proposed MoMa: Modality-aware expert hybrid architecture.
- 論文標題:MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
- 論文地址:https://arxiv.org/pdf/2407.21770有研究表明,這類架構可以有效地擴展單模態的基礎模型的能力,也可以增強多模態對比學習模型的性能。但是,將其用於較早將各種模態融合的模型訓練還是一個機遇與挑戰並存的課題,還少有人研究。
該團隊的研究基於這一洞見:不同模態具有固有的異構性 —— 文字和圖像 token 具有不同的資訊密度和冗餘模式。
在將這些 token 整合成統一的融合架構的同時,該團隊也提出透過整合針對具體模態的模組來進一步優化該框架。團隊將此概念稱為模態感知型稀疏性(modality-aware sparsity),簡稱MaS;其能讓模型更好地捕捉每個模態的特徵,同時還能透過部分參數共享和注意力機制維持強大的跨模態整合性能。
之前的VLMo、BEiT-3 和VL-MoE 等研究已經採用了混合模態專家(MoME/mixture-of-modality-experts)方法來訓練視覺- 語言編碼器和掩碼式語言構建模,來自FAIR 的研究團隊更進一步將MoE 的可用範圍又推進了一步。 模型架構
系列離散token。 Chameleon 的核心是一個基於 Transformer 的模型,其會在圖像和文字 token 的組合序列上應用自註意力機制。這能讓此模型捕捉模態內和模態間的複雜關聯。此模型的訓練使用的目標是下一 token 預測目標,以自回歸方式產生文字和圖像 token。 在 Chameleon 中,圖像的 token 化方案採用了一個學習型圖像分詞器,它將基於大小為 8192 的 codebook 將 512 × 512 的圖像編碼成 1024 個離散 token。對於文本的分詞將使用一個詞表大小為 65,536 的 BPE 分詞器,其中包含圖像 token。這種統一的分詞方法可以讓模型無縫處理圖像和文字 token 交織錯雜的任意序列。 借助這種方法,新模型繼承了表徵統一、靈活性好、可擴展性高、支持端到端學習這些優點。 在此基礎上(圖 1a),為了進一步提升早期融合模型的效率和效能,團隊也引進了模態感知型稀疏性技術。 該團隊提出了一種寬度感知方法:將模態感知型模組稀疏性標準混合專家(MoE)架構。 此方法基於此洞見:不同模態的 token 有各自不同的特徵和資訊密度。 透過為每個模態建立不同的專家分組,可讓模型開發出專門的處理路徑,同時維持跨模態的資訊整合能力。 圖 1b 展示了這種模態感知型專家混合(MoMa)的關鍵組件。簡單來說,先將各個特定模態的專家分組,然後實現分層路由(分為模態感知型路由和模態內路由),最後選擇專家。詳細過程請參考原論文。 整體來說,對於一個輸入 token x,MoMa 模組的形式化定義為: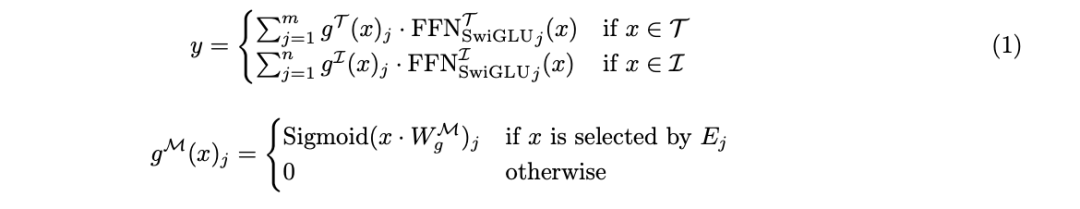
在 MoMa 計算之後,該團隊又進一步使用了殘差連接和 Swin Transformer 歸一化。 之前也有研究者將某些易性引入維度,他們的方法要麼是使用深度學習的路由器。 具體而言,如下圖所示,該團隊的做法是在每個MoD 層中,在混合專家(MoE)路由之前都集成MoD,從而確保在模態分離之前,整批數據都能應用MoD。 在推理階段,我們不能直接使用MoE 的專家選擇路由或MoD 的層數據選擇路由,因為在一批數據中進行 top )選擇會破壞因果關係。 為了保證推理的因果關係,受上述MoD 論文的啟發,研究團隊引入了輔助路由器(auxiliary router),其作用是僅基於token 的隱藏表徵預測該token 被某個專家或層選中的可能性。 在優化表徵空間和路由機制方面,對於一個從頭開始訓練 MoE 架構,存在一個獨特的難題。團隊發現:MoE 路由器負責為每個專家劃分錶徵空間。但是,在模型訓練的早期階段,這個表徵空間並非最優,這就會導致訓練得到的路由函數也是次優的。 為了克服這一局限,他們基於 Komatsuzaki 等人的論文《Sparse upcycling: Training mixture-of-experts from dense checkpoints》提出了一種升級改造方法。 
具體來說,首先訓練一個每個模態都有一個 FFN 專家的架構。經過一些預先設定的步數之後,再對該模型進行升級改造,具體做法是:將每個特定模態的FFN 轉換成一個專家選擇式MoE 模組,並將每個專家初始化為第一階段訓練的專家。這裡會在保留前一階段的資料載入器狀態的同時重置學習率調度器,以確保第二階段的訓練能使用已刷新的資料。 為了促進專家更加專業,該團隊還使用了 Gumbel 噪聲來增強 MoE 路由函數,從而使得新的路由器能以可微分的方式對專家進行採樣。 這種升級改造方法加上 Gumbel-Sigmoid 技術,可克服學習到的路由器的局限性,從而提升新提出的模態感知型稀疏架構的性能。 為促進 MoMa 的分散式訓練,該團隊採用了完全分片式資料並行(FSDP/Fully Sharded Data Parallel)。但是,相較於常規 MoE,此方法存在一些特有的效率難題,包括負載平衡問題和專家執行的效率問題。 對於負載平衡問題,該團隊開發了一種平衡的資料混合方法,可讓每台 GPU 上的文字 - 影像資料比例與專家比例保持一致。 對於專家執行的效率問題,該團隊探索了一些策略,可幫助提升不同模態的專家的執行效率:
- 將各個模態的專家限制為同構的專家,並禁止將文字token 路由到圖像專家,反之亦然;
- 使用模組稀疏性(block sparsity)來提升執行效率;
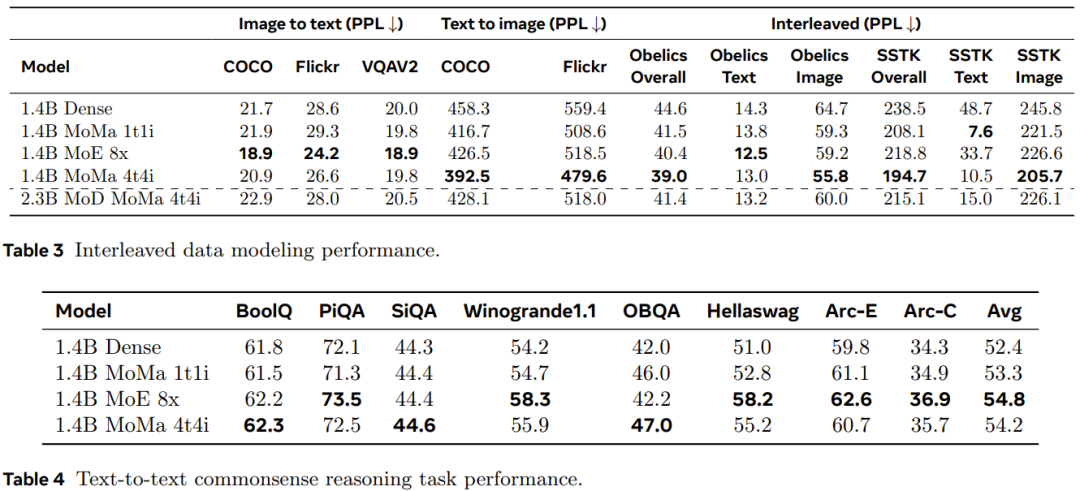
由於實驗中每台 GPU 處理的 token 都足夠多,因此即使使用多個分批次矩陣乘法,硬體利用率也不算大問題。因此,團隊認為對於目前規模的實驗環境而言,依序執行的方法是比較好的選擇。 為了進一步提升吞吐量,該團隊還採用了其它一些優化技術。 其中包括降低梯度通訊量、自動化的 GPU 核融合等一般最佳化操作,研究團隊也透過 torch.compile 實現了圖優化。 此外,他們還針對 MoMa 開發了一些優化技術,包括跨不同層復用模態 token 索引,以最高效地同步 CPU 和 GPU 之間的設備。 實驗中所使用的預處理資料集和預處理過程一樣與訓練過程中所使用的預處理資料集一樣與訓練過程中使用的預處理資料集一樣與訓練過程中使用的預處理資料集一樣與訓練過程中使用的預處理資料集一樣與訓練過程中使用的預處理資料集一樣與訓練過程中使用的預處理資料集一樣與訓練過程中使用的預處理資料集一樣與訓練過程中使用的預處理資料集一樣與訓練過程中所使用的預處理資料集相同為了評估擴展效能,他們訓練模型使用的 token 數量超過 1 兆。 該團隊分析了不同模型在不同計算層級上的擴展性能,這些計算層級(FLOPs)相當於三種大小的密集模型:90M、M 435M 和1.4B。 實驗結果表明,一個稀疏模型僅使用總 FLOPs 的 1/η 就能比肩膀同等 FLOPs 的密集模型的預訓練損失(η 表示預訓練加速因子)。 引入特定模態的專家分組可提高不同規模模型的預訓練效率,這對影像模態尤其有益。如圖 3 所示,使用 1 個影像專家和 1 個文字專家的 moe_1t1i 配置顯著優於對應的密集模型。 擴展每個模態分組的專家數量還能進一步提升模型效能。 該團隊觀察到,當採用 MoE 和 MoD 以及它們的組合形式時,訓練損失的收斂速度會得到提升。如圖 4 所示,在 moe_1t1i 架構中加入 MoD(mod_moe_1t1i)可大幅提升不同模型大小的模型效能。 此外,在不同的模型大小和模態上,mod_moe_1t1i 能媲美甚至超過 moe_4t4i,這表明在深度維度上引入稀疏性也能有效提升訓練效率。 另一方面,還能看到堆疊 MoD 和 MoE 的收益會逐漸下降。 為了研究擴展專家數量的影響,該團隊進行了進一步的消融實驗。他們探索了兩種場景:為每種模態分配同等數量的專家(平衡)以及為每種模態分配不同數量的專家(不平衡)。結果見圖 5。 對於平衡的設置,從圖 5a 可以看到,隨著專家數量提升,訓練損失會明顯下降。但文字和圖像損失表現出了不同的擴展模式。這表明每種模態的固有特性會導致不同的稀疏建模行為。 對於不平衡的設置,圖 5b 比較了同等專家總數(8)的三種不同配置。可以看到,一個模態的專家越多,模型在該模態上的表現通常就越好。 該團隊自然也驗證了前述的升級改造的效果。圖 6 比較了不同模型變體的訓練曲線。 結果表明,升級改造確實能進一步改善模型訓練:當第一個階段有10k 步時,升級改造能帶來1.2 倍的FLOPs 收益;而當這個步數為20k 時,也有1.16 倍的FLOPs 收益。 此外,還能觀察到,隨著訓練推進,經過升級改造的模型與從頭開始訓練的模型之間的性能差距會不斷增大。 稀疏模型通常無法立即帶來效能增益,因為稀疏模型會增加動態性和相關的資料平衡問題。為了量化新提出的方法對訓練效率的影響,團隊通常控制變數實驗比較了不同架構的訓練吞吐量。結果見表 2。 可以看到,相比於密集模型,基於模態的稀疏性能實現更好的質量 - 吞吐量權衡,並且能隨專家數量增長展現出合理的可擴展性。另一方面,儘管 MoD 變體取得了最好的絕對損失,但由於額外的動態性和不平衡性,它們的計算成本往往也更高。 該團隊也評估了模型在留存的語言建模資料和下游任務上的表現。結果見表 3 和 4。 如表3 所示,透過使用多個圖像專家,1.4B MoMa 1t1i 模型在大多數指標上都優於相應的密集模型,只有在COCO 和Flickr 上的圖像到文本條件困惑度指標例外。進一步擴展專家數量也能提升效能,其中 1.4B MoE 8x 在圖像到文字效能上達到了最佳。 此外,如表 4 所示,1.4B MoE 8x 這個模型也非常擅長文本到文本任務。 1.4B MoMa 4t4i 在所有條件影像困惑度指標上表現最佳,而其在大多數基準上的文字困惑度也非常接近 1.4B MoE 8x。 整體而言,在混合文字和影像兩種模態的資料上,1.4B MoMa 4t4i 模型的建模結果最佳。 The above is the detailed content of Hybrid experts are more assertive and can perceive multiple modalities and act according to the situation. Meta proposes modality-aware expert hybrids. For more information, please follow other related articles on the PHP Chinese website!



























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



