
 Technology peripherals
AI
AI produces pictures faster, more beautifully, and understands your thoughts better. What technical secrets has the high-beauty Vincent picture model cultivated?
Technology peripherals
AI
AI produces pictures faster, more beautifully, and understands your thoughts better. What technical secrets has the high-beauty Vincent picture model cultivated?
AI produces pictures faster, more beautifully, and understands your thoughts better. What technical secrets has the high-beauty Vincent picture model cultivated?


With the launch of large models and pressing the accelerator button, Vincentian diagrams are undoubtedly one of the hottest application directions.
Since the birth of Stable Diffusion, there have been an endless stream of large models of Wen Shengtu at home and abroad, and it felt like "fighting between gods" for a while. In just a few months, the title of "The Strongest AI Artist" has changed hands several times. Every technological iteration continues to push the upper limit of AI image generation quality and speed.
So now, we can get any picture we want by entering a few words. Whether it’s a professional-level commercial poster or a hyper-realistic photo, the fidelity of AI mapping has amazed us. Even AI won the 2023 Sony World Photography Award. Before the announcement of the grand prize, this "photo" had been exhibited at Somerset House in London - if the author did not disclose it publicly, no one might find out that the photo was actually created by AI. E Eldagse and his AI generation work "Electrician"
 How to make the pictures drawn by AI is more beautiful, which is inseparable from AI technicians to persevere.
How to make the pictures drawn by AI is more beautiful, which is inseparable from AI technicians to persevere. The live broadcast began. Li Liang first dissected in detail the recent "top-tier" domestic large model - the technical upgrade of the Vincent diagram model of the ByteDance Doubao large model.
Li Liang said that the problems that the Doubao team wants to solve mainly include three aspects: first, how to achieve stronger image and text matching to meet the user's idea design; second, how to generate more beautiful images to provide more ultimate The user experience; the third is how to produce pictures more quickly to meet ultra-large-scale service calls. In terms of image and text matching, the Doubao team started with data, refined and filtered the massive image and text data, and finally stored hundreds of billions of high-quality images in the database. In addition, the team also specially trained a multi-modal large language model for the recapiton task. This model will more comprehensively and objectively describe the physical relationships of images in pictures.
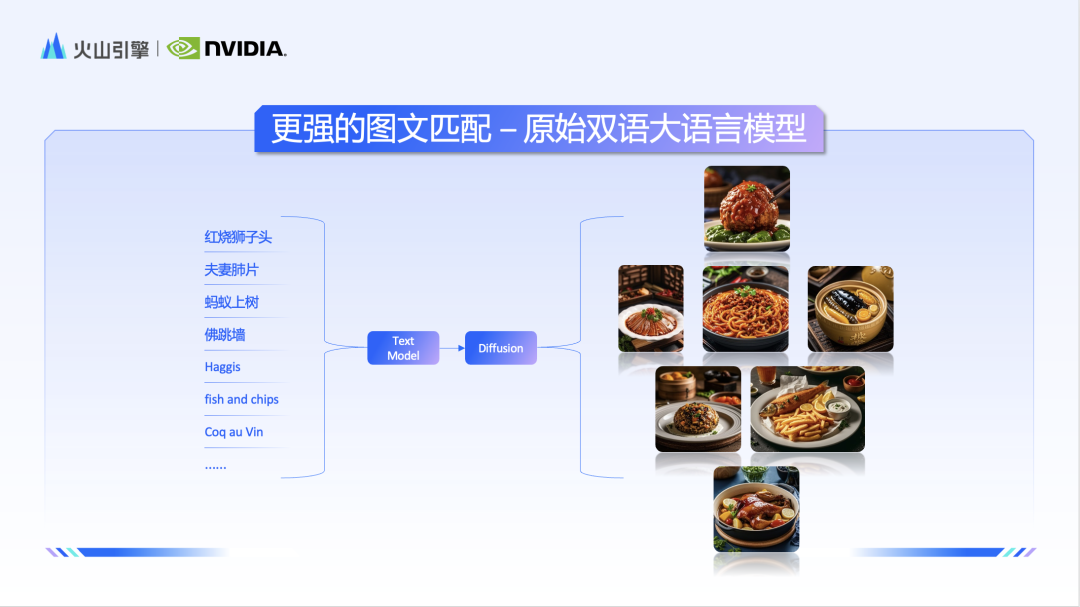
After having high-quality and high-detailed image and text data, if you want to better leverage the strength of the model, you need to improve the ability of the text understanding module. The team uses a native bilingual large language model as a text encoder, which significantly improves the model's ability to understand Chinese. Therefore, in the face of national elements such as "Tang Dynasty" and "Lantern Festival", the Doubao and Vincent diagram models also show a more profound understanding.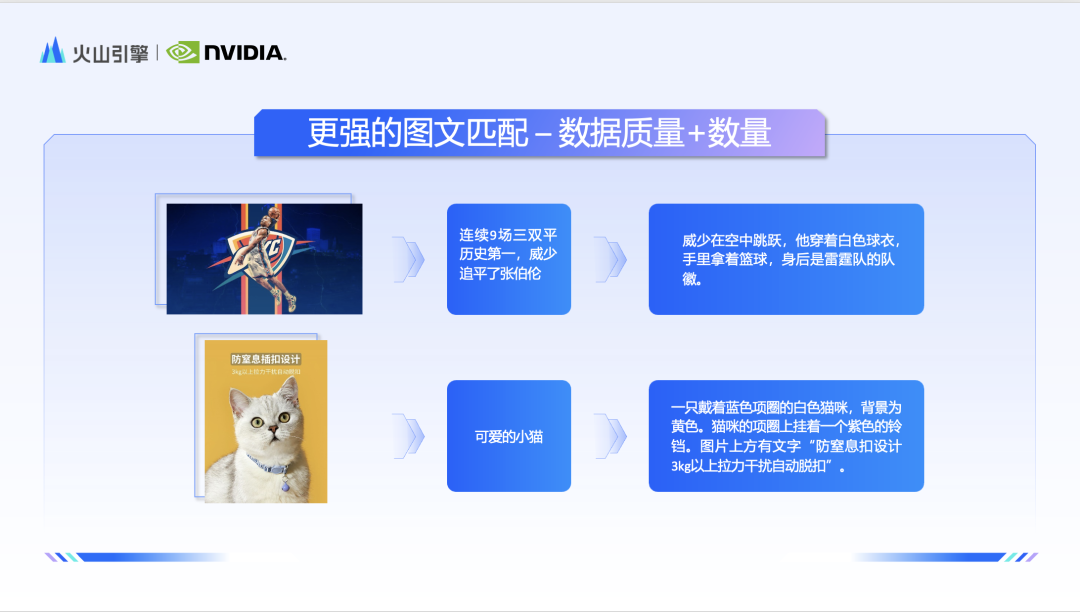
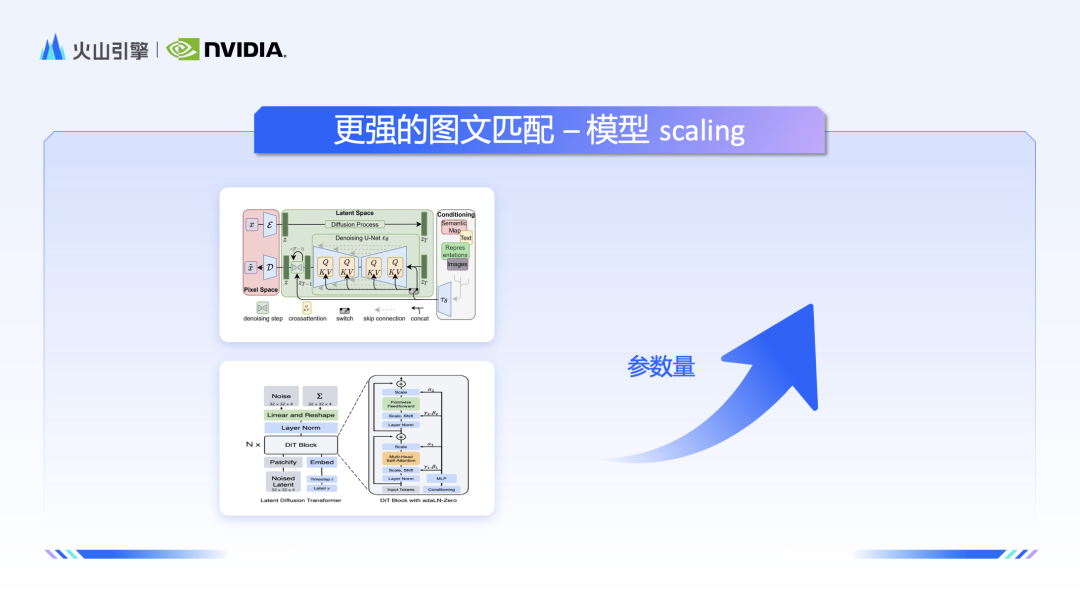
接下来,英伟达解决方案架构师赵一嘉从底层技术出发,讲解了文生图最主流的基于Unet的SD和DIT两种模型架构及其相应的特性,并介绍了英伟达的Tensorrt, Tensorrt-LLM, Triton, Nemo Megatron 等工具如何为部署模型提供支持,助力大模型更加高效地推理。
赵一嘉首先分享了 Stable Diffusion 背后模型的原理详解,细致地阐述了 Clip、VAE 和 Unet 等关键组件的工作原理。随着 Sora 爆火,也带火了背后的 DiT(扩散 Transformer)架构。赵一嘉进一步从模型结构、特性和算力消耗三方面,从模型结构、特性和资源消耗三个方面,对 SD 和 DiT 的优势进行了全面的比较。
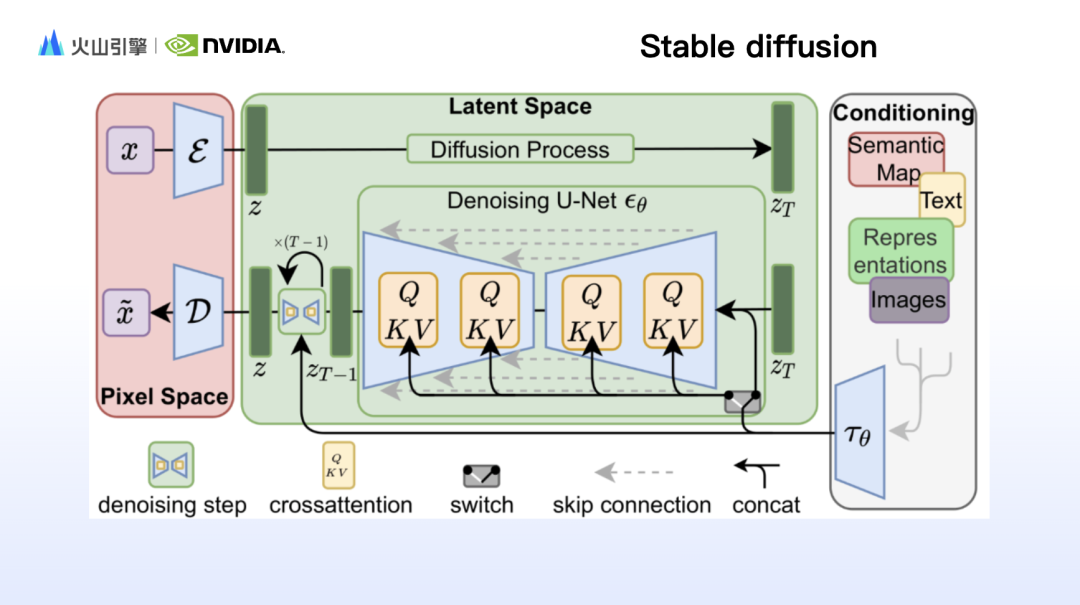
使用 Stable diffusion 生成图像时,往往会感觉提示词内容在生成结果中都得到了呈现,但图不是自己想要的,这是因为基于文字出图的 Stable diffusion 并不擅长控制图像的细节,例如构图、动作、面部特征、空间关系等。因此,基于Stable diffusion 的工作原理,研究人员们设计了许多控制模块,弥补 Stable diffusion 的短板。赵一嘉补充了其中具有代表性的 IP-adapter 和 ControlNet。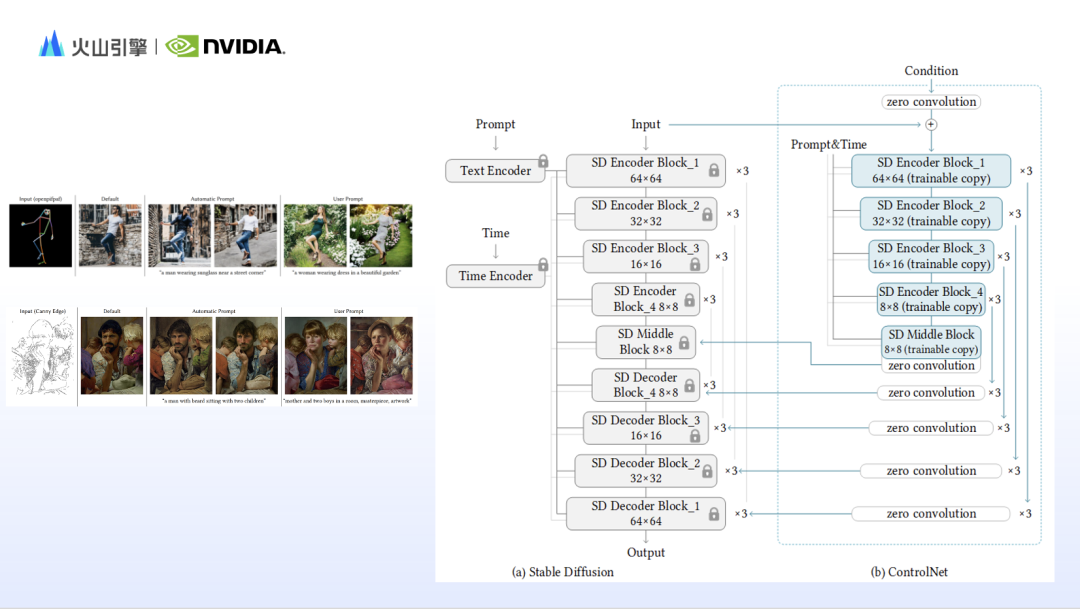
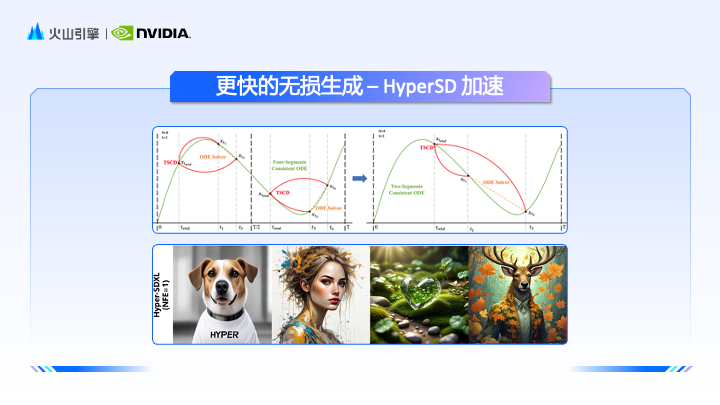
想要加快吃算力的文生图模型的推理速度,英伟达的技术支持发挥了关键作用。赵一嘉介绍了 Nvidia TensorRT 和 TensorRT-LLM 工具,这些工具通过高性能卷积、高效调度和分布式部署等技术,优化了图文生成模型的推理过程。同时,英伟达的 Ada、Hopper 以及即将推出的 BlackWell 硬件架构,都已支持 FP8 训练和推理,将为模型训练带来更加丝滑的体验。

经历了六场精彩的直播,由火山引擎、NVIDIA 联手本站和 CMO CLUB 共同推出的《AIGC体验派》迎来了圆满收官。通过这六期节目,相信大家对 AIGC 如何从「有趣」变为「有用」有了更深的理解。我们也期待着《AIGC 体验派》不止停留在节目的讨论中,并更能在实际中加速营销领域智能化升级的进程。
《AIGC 体验派》全六期回顾地址:https://vtizr.xetlk.com/s/7CjTy
The above is the detailed content of AI produces pictures faster, more beautifully, and understands your thoughts better. What technical secrets has the high-beauty Vincent picture model cultivated?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1670
1670
 14
1428
52
1329
25
1273
29
1256
24
14
1428
52
1329
25
1273
29
1256
24

 Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Kimi: In just one sentence, in just ten seconds, a PPT will be ready. PPT is so annoying! To hold a meeting, you need to have a PPT; to write a weekly report, you need to have a PPT; to make an investment, you need to show a PPT; even when you accuse someone of cheating, you have to send a PPT. College is more like studying a PPT major. You watch PPT in class and do PPT after class. Perhaps, when Dennis Austin invented PPT 37 years ago, he did not expect that one day PPT would become so widespread. Talking about our hard experience of making PPT brings tears to our eyes. "It took three months to make a PPT of more than 20 pages, and I revised it dozens of times. I felt like vomiting when I saw the PPT." "At my peak, I did five PPTs a day, and even my breathing was PPT." If you have an impromptu meeting, you should do it
 A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion can not only imitate better, but also "create". The diffusion model (DiffusionModel) is an image generation model. Compared with the well-known algorithms such as GAN and VAE in the field of AI, the diffusion model takes a different approach. Its main idea is a process of first adding noise to the image and then gradually denoising it. How to denoise and restore the original image is the core part of the algorithm. The final algorithm is able to generate an image from a random noisy image. In recent years, the phenomenal growth of generative AI has enabled many exciting applications in text-to-image generation, video generation, and more. The basic principle behind these generative tools is the concept of diffusion, a special sampling mechanism that overcomes the limitations of previous methods.
 Unifying characters and changing scenes, PixVerse, a video generation artifact, has been played out by netizens, and its super consistency has become a 'killer move'
Apr 01, 2024 pm 02:11 PM
Unifying characters and changing scenes, PixVerse, a video generation artifact, has been played out by netizens, and its super consistency has become a 'killer move'
Apr 01, 2024 pm 02:11 PM
Another double click is the debut of a new feature. Have you ever wanted to change the background of a character in a picture, but the AI always produces the effect of "the object is neither the person nor the object". Even in mature generation tools such as Midjourney and DALL・E, some prompt skills are required to maintain character consistency, otherwise the characters will change around and you will not achieve the results you want. However, this time it’s your chance. The new "Character-Video" function of the AIGC tool PixVerse can help you achieve all this. Not only that, it can generate dynamic videos to make your characters more vivid. Enter a picture and you will be able to get the corresponding dynamic video results. On the basis of maintaining the consistency of the characters, the rich background elements and character dynamics allow the generated results to be
 All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
In the early morning of June 20th, Beijing time, CVPR2024, the top international computer vision conference held in Seattle, officially announced the best paper and other awards. This year, a total of 10 papers won awards, including 2 best papers and 2 best student papers. In addition, there were 2 best paper nominations and 4 best student paper nominations. The top conference in the field of computer vision (CV) is CVPR, which attracts a large number of research institutions and universities every year. According to statistics, a total of 11,532 papers were submitted this year, and 2,719 were accepted, with an acceptance rate of 23.6%. According to Georgia Institute of Technology’s statistical analysis of CVPR2024 data, from the perspective of research topics, the largest number of papers is image and video synthesis and generation (Imageandvideosyn
 From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
We know that LLM is trained on large-scale computer clusters using massive data. This site has introduced many methods and technologies used to assist and improve the LLM training process. Today, what we want to share is an article that goes deep into the underlying technology and introduces how to turn a bunch of "bare metals" without even an operating system into a computer cluster for training LLM. This article comes from Imbue, an AI startup that strives to achieve general intelligence by understanding how machines think. Of course, turning a bunch of "bare metal" without an operating system into a computer cluster for training LLM is not an easy process, full of exploration and trial and error, but Imbue finally successfully trained an LLM with 70 billion parameters. and in the process accumulate
 Xiaomi Photo Album AIGC editing function officially launched: supports intelligent image expansion and magic elimination Pro
Mar 14, 2024 pm 10:22 PM
Xiaomi Photo Album AIGC editing function officially launched: supports intelligent image expansion and magic elimination Pro
Mar 14, 2024 pm 10:22 PM
According to news on March 14, Xiaomi officially announced today that the AIGC editing function of Xiaomi Photo Album is officially launched on Xiaomi 14 Ultra mobile phones, and will be fully launched on Xiaomi 14, Xiaomi 14 Pro and Redmi K70 series mobile phones within this month. The AI large model brings two new functions to Xiaomi Photo Album: Intelligent Image Expansion and Magic Elimination Pro. AI smart image expansion supports the expansion and automatic composition of poorly composed pictures. The operation method is: open the photo album to edit - enter cropping and rotation - click smart image expansion. Magic Elimination Pro can seamlessly eliminate passers-by in tourist photos. The method of use is: open the photo album to edit - enter Magic Elimination - click Pro in the upper right corner. At present, Xiaomi 14Ultra machine has launched intelligent image expansion and magic elimination Pro functions.
 AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
Editor of the Machine Power Report: Yang Wen The wave of artificial intelligence represented by large models and AIGC has been quietly changing the way we live and work, but most people still don’t know how to use it. Therefore, we have launched the "AI in Use" column to introduce in detail how to use AI through intuitive, interesting and concise artificial intelligence use cases and stimulate everyone's thinking. We also welcome readers to submit innovative, hands-on use cases. Video link: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Recently, the life vlog of a girl living alone became popular on Xiaohongshu. An illustration-style animation, coupled with a few healing words, can be easily picked up in just a few days.
 A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
Title: A must-read for technical beginners: Difficulty analysis of C language and Python, requiring specific code examples In today's digital age, programming technology has become an increasingly important ability. Whether you want to work in fields such as software development, data analysis, artificial intelligence, or just learn programming out of interest, choosing a suitable programming language is the first step. Among many programming languages, C language and Python are two widely used programming languages, each with its own characteristics. This article will analyze the difficulty levels of C language and Python
